a newbie in Porto Seguro’s Safe Driver Prediction(solo参赛 TOP 5%)
关于kaggle
kaggle是一个国际性质的机器学习竞赛平台,跟国内很多出名的别的平台比,kaggle上参与者之间的交流多很多,可以很大程度上提高参赛人员水平。而且kaggle本身难度也比国内的很多比赛要大很多。
Porto Seguro’s Safe Driver Prediction
这个比赛是一家巴西的公司发起的预测购买汽车保险后一年内是否会发生理赔。整个比赛组织方提供了一个训练集和一个预测集,原始训练数据有59列,595212条,需要预测的数据有892816条。整个数据集都被处理过,无法通过每一列数据的列名以及其中的数据都被加密。
比赛过程中每天可以提交五份答案,成绩计算方式是gini系数( 2×auc−1 ),答案中的30%将被用于public Leaderboard的排名,这个每次提交都可以看到。剩余数据用于private Leaderboard排名的计算,这个排名是比赛的最终排名在比赛截止的时候会用选手之前上交的且由选手选定的两份答案计算。
大概的历程(絮叨部分)
整个比赛的过程,从刚开始一个对于分类问题似懂非懂而且自身比较弱的状态慢慢变得有了一些了解。做比赛的过程中自己的成绩从一个负数慢慢做到了0.285,中间学习了很多东西包括stacking,cv等等。
慢慢的自己的排名接近到了6%的位置,当时由于一些考试的原因,离开比赛去复习了一周左右的时间,考完试回来发现自己排名跌落到了20%左右的位置。
当时很着急,发现是因为有人公布了自己一个0.287的kernel,这个kernel利用很多别人公布的kernel的输出的答案,进行一次求平均,最后自己可以达到0.287,当时那个阶段完全靠自己的方案达到0.287的非常少。
在那之后陆续有人通过平均自己的结果与一些公开的kernel的结果达到了很高的排名。这个方法在当时看来是非常有诱惑力的做法,当时很多人就开始就这种方案开始讨论,这种方法是不是一种过拟合。当时我的想法是想自己好好做一份结果出来并不想平均别人的结果,因为自己是来锻炼自己,来学习成长的而不是单纯追求一个成绩。
在这之后一直在挣扎着想要获得更高的成绩,结果发现就算自己尝试各种方法去融合各种模型也不能达到效果,自己的最高成绩就只是0.285。
越来越临近比赛的截止日期,每天都有很多人超越自己的排名,慢慢的自己排名就跌到了百分之二十几的位置,每天都很糟心,尝试各种东西catboost,rf,gbdt,xgb,lgb,mlp等等,但是这些算法的各种融合都不能使自己的成绩有很大的提升,自己的成绩稳定在0.285(local cv 0.2895)左右。
越到后期,越糟心关于比赛的进展,在最后一天,自己决定尝试一下平均自己的答案和别人公布的kernel的输出,最后发现这样可以达到0.286。在最后选择两份答案作为最终计算排名的答案的时候,犹豫了一段时间,自己决定两种方式都试一下,提交一份完全自己做的(0.285),提交一份和其他人平均的结果(0.286),在出成绩的前三分钟里,我在kaggle平台上写了一个discussion,想表达一下自己虽然努力了,但是结果不好的,有点沮丧,想感谢一下比赛中那些回答过自己问题,给予过自己帮助的人。
在我discussion写一半的时候出成绩了,当时惊喜地发现自己的当初的选择是正确的,相信自己,相信local cv是正确的,很多人都过拟合了,自己public LB的成绩是0.290(private LB 0.285),这个和local cv的结果比较接近,最终自己的排名定在了第240名,总共有5169支队伍参赛。
整个比赛结束,总结一下要相信自己,要努力,无论何时都要保持一个冷静的心态来面对各种情况。
整个比赛做完,自己学到了很多东西,收获很多,自己做的东西不足的地方也很多,下面大致列一下自己的大致解决方案,欢迎每一位朋友指出其中的问题与缺陷。
整体方案(干货)
数据探索
面对数据集,里面有空值(原始数据集空值用-1表示),这里先不着急对空值进行处理,先简单判断了一些所有列直接的一个相关性,并画出相关性图,如下:
import pandas as pd;
import numpy as np;
import seaborn as sns;
import matplotlib.pyplot as plt;
train_data_raw=pd.read_csv("D:/general_file_unclassified/about_code/kaggle/Porto_Seguro_s_Safe_Driver_Prediction/train/train_s.csv");
test_data_raw=pd.read_csv("D:/general_file_unclassified/about_code/kaggle/Porto_Seguro_s_Safe_Driver_Prediction/test/test_s.csv");
train_data_raw=train_data_raw.drop(['id'],axis=1);
corrmat = train_data_raw.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);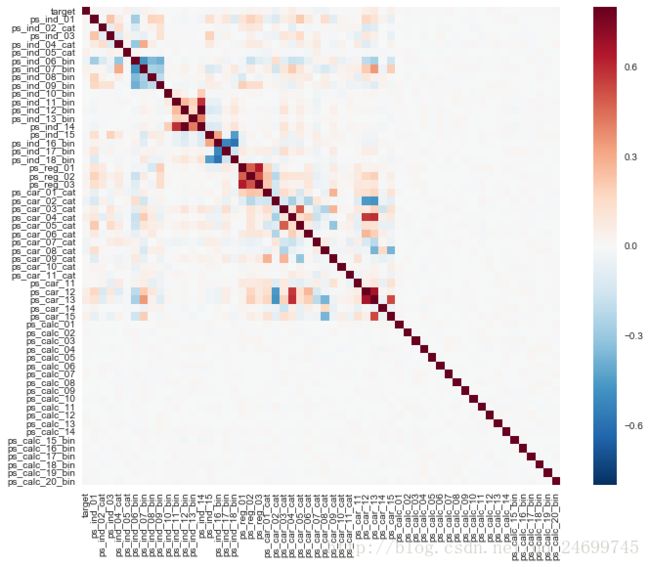
从上面的图像中可以发现所有名字中带有ps_calc的列与其他列的相关性非常低,这一点将作为后面特征筛选的依据。
关于空值,由于本次比赛的数据中-1的意义特殊,我们可以通过一些画图手段发现一些列的值为-1的时候该样本发起诉讼的可能性很大,或者很小,例如:
sns.pointplot(x="ps_ind_04_cat", y="target", data=train_data_raw);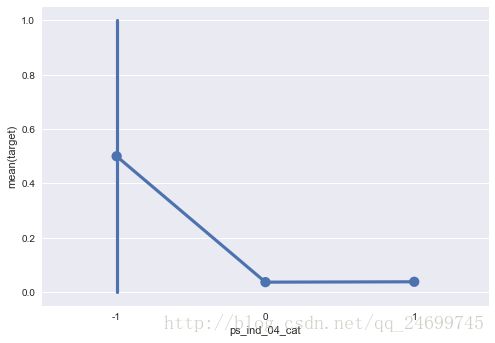
数据预处理
- 去除含有’ps_calc’的列
- 保留所有值为-1的空值
- 将所有带有cat的列进行onehot
- 剩下的所有数据调整尺度到[0,1]之间
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 11 10:58:10 2017
@author: 56390
"""
import pandas as pd;
import numpy as np;
from sklearn.ensemble import BaggingClassifier;
from sklearn.ensemble import ExtraTreesClassifier;
from sklearn.neural_network import MLPClassifier;
from sklearn.linear_model import LogisticRegression;
from sklearn.svm import SVC, LinearSVC;
from sklearn.ensemble import RandomForestClassifier;
from sklearn.neighbors import KNeighborsClassifier;
from sklearn.naive_bayes import GaussianNB;
from sklearn.linear_model import Perceptron;
from sklearn.linear_model import SGDClassifier;
from sklearn.tree import DecisionTreeClassifier;
from sklearn.metrics import roc_auc_score;
from sklearn.ensemble import GradientBoostingClassifier;
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
import xgboost as xgb;
import lightgbm as lgb;
from sklearn.feature_selection import RFECV;
from sklearn.preprocessing import OneHotEncoder;
from sklearn.preprocessing import MinMaxScaler;
from preprocess import rawDataProcess;
from stacker import stacker;
from stacker import linearBlending;
from catboost import CatBoostClassifier;
train_data_raw=pd.read_csv("/home/lj407/Data/Lxy_data/kaggle/PortoPrediction/train/train.csv");
test_data_raw=pd.read_csv("/home/lj407/Data/Lxy_data/kaggle/PortoPrediction/test/test.csv");
train_data_raw=train_data_raw.drop(['id'],axis=1);
colListDrop=[];
for column in train_data_raw:
if 'ps_calc_' in column:
colListDrop.append(column);
print('ps_calc_以及一些相关性很低的特征删除,,去除的列如下')
print('-'*60);
train_data_raw=train_data_raw.drop(colListDrop,axis=1);
print(colListDrop);
print('含有-1值的列')
print('-'*60);
for column in train_data_raw.drop(['target'],axis=1):
if -1 in train_data_raw[column].values:
print(column);
colCatList=[];
colScList=[];
for column in train_data_raw.drop(['target'],axis=1):
if 'cat' in column:
if train_data_raw[column].min()==-1:
train_data_raw[column]+=1
test_data_raw[column]+=1;
colCatList.append(column);
elif 'bin' not in column:
colScList.append(column);
print('需要onehot的列')
print('-'*60);
print(colCatList);
print('需要调整尺度的列')
print('-'*60);
print(colScList);
rawpro=rawDataProcess(train_data_raw,test_data_raw,colCatList,colScList);
dataAll=[rawpro.toTrainData(),rawpro.toTestData()];
random_train_data=dataAll[0].sample(frac=1.0,random_state=888);
train_data_train_x=random_train_data.drop(['target'],axis=1);
train_data_train_y=random_train_data['target'];
test_data=dataAll[1];调参
调参利用sklearn上提供的gridsearch来进行暴力搜索参数
#这里只是实例,并不是实际中用的参数与模型
catb=CatBoostClassifier();
paramGrid={
'iterations':[30],
'verbose':[True],
'depth':[3]
};
cf=GridSearchCV(catb,paramGrid,cv=StratifiedKFold(n_splits=5,random_state=1),scoring='roc_auc');
cf.fit(train_data_train_x,train_data_train_y);
print(cf.best_score_);
print(cf.best_params_);根据调好的模型来进行进一步的特征筛选
这里采用sklearn中提供的RFECV来进行特征的删除,每次迭代会删除20列特征(这里的列是经过onehot和尺度调整的),然后会选择CV结果最高的删除方式作为最后的结果。
estimator = lgb.LGBMClassifier(subsample=0.8,colsample_bytree=0.8,max_bin=10,subsample_freq=10,min_child_samples=500,max_depth=9,random_state=666,boosting_type='gbdt',n_estimators=1200,learning_rate=0.01,verbose=1);
selector = RFECV(estimator, step=int(20), cv=StratifiedKFold(n_splits=5,random_state=1),scoring='roc_auc',verbose=True);
selector = selector.fit(train_data_train_x[featureSelected],train_data_train_y);
print(len(selector.grid_scores_));
print(selector.grid_scores_);根据lgb我对特征进行进一步筛选,如下:
selectedColByLgbm=[0 , 1 , 2 , 3 , 6 , 8 , 9 , 10 , 12 , 13 , 14 , 15 , 17 , 18 , 19 , 20 , 21 , 22 , 23 , 24 , 25 , 26 , 28 , 30 , 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 , 39 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 54 , 55 , 56 , 57 , 58 , 59 , 60 , 62 , 63 , 65 , 66 , 68 , 69 , 70 , 73 , 74 , 75 , 76 , 77 , 78 , 79 , 80 , 81 , 83 , 84 , 85 , 86 , 87 , 91 , 92 , 96 , 97 , 98 , 100 , 106 , 107 , 108 , 111 , 115 , 117 , 121 , 122 , 123 , 124 , 125 , 128 , 129 , 130 , 131 , 133 , 136 , 140 , 142 , 145 , 153 , 154 , 155 , 160 , 162 , 170 , 171 , 173 , 174 , 175 , 177 , 178 , 180 , 183 , 185 , 187 , 189 , 190 , 191 , 193 , 194 , 195 , 196 , 198 , 199 , 200 , 201 , 202 , 203 , 204 , 205 , 206];
print('经过ligbm的挑选后剩下的特征数量为: ',len(selectedColByLgbm))
featureSelected=selectedColByLgbm;
train_data_train_x=train_data_train_x.iloc[:,featureSelected];stacking
stacking,我这里采用的stacking分为两层,第一层是之前各种调参好的模型,第二层是一个’以auc为损失函数’的线性模型(注:不是逻辑回归,这个方法可以在很小程度上比逻辑回归有更好的表现)。
以AUC为损失函数:这种方法的具体实现方式为,假设这里有 n 个模型,首先给定分割份数为 β ,每个个模型得到一部分份数,假设第第 i 个模型得到的份数为 αi ,第 i 个模型的权重为 weighti ,这样的话每个模型的权重表达如下:
然后在
stacking与这个特殊线性模型的代码实现
import pandas as pd;
import numpy as np;
import copy as cp;
import math;
from sklearn.metrics import roc_auc_score;
from sklearn.model_selection import StratifiedKFold;
from sklearn.linear_model import LogisticRegression;
from sklearn.model_selection import cross_val_score;
class stacker:
def __init__(self,modelList,higherModel=-1,kFold=StratifiedKFold(n_splits=5,random_state=0),kFoldHigher=StratifiedKFold(n_splits=5,random_state=777)):
#assert type(modelList)==list,"输入必须为一个模型的列表"
#assert type(kFold)==StratifiedKFold,"输入必须为StratifiedKFold"
self.kFold=kFold;
self.kFoldHigher=kFoldHigher;
self.modelList=modelList;
self.higherModel=higherModel;
def fit(self,X,Y,upsample=False):
#assert type(X)==pd.DataFrame,"X输入必须为DataFrame"
#assert type(Y)==pd.DataFrame,"Y输入必须为DataFrame"
self.modelScoreList=[];
self.modelListList=[];
self.modelHigherList=[];
higherTrain=pd.DataFrame(np.zeros((Y.shape[0], len(self.modelList))));
i=0;
for model in self.modelList:
modelList=[];
giniScoreList=[];
for kTrainIndex,kTestIndex in self.kFold.split(X,Y):
kTrain_x=X.iloc[kTrainIndex];
kTrain_y=Y.iloc[kTrainIndex];
if upsample:
upsampleTrainData=self.upsample(kTrain_x,kTrain_y);
kTrain_x=upsampleTrainData.drop(['label'],axis=1);
kTrain_y=upsampleTrainData['label'];
kTest_x=X.iloc[kTestIndex];
kTest_y=Y.iloc[kTestIndex];
modelCp=cp.deepcopy(model);
modelCp.fit(kTrain_x,kTrain_y);
modelList.append(modelCp);
testPre=modelCp.predict_proba(kTest_x)[:,1];
higherTrain.values[kTestIndex,i]=testPre;
giniScore=2*roc_auc_score(kTest_y,testPre)-1;
giniScoreList.append(giniScore);
print('baseModel gini: ',giniScore);
self.modelScoreList.append((np.array(giniScoreList).mean(),np.array(giniScoreList).std()));
print('mean gini: ',np.array(giniScoreList).mean());
print('-'*20);
i+=1;
self.modelListList.append(modelList);
print(higherTrain.shape);
self.re_score=[];
for kTrainIndex,kTestIndex in self.kFoldHigher.split(higherTrain,Y):
higherModelcp=cp.deepcopy(self.higherModel);
kTrain_x=higherTrain.iloc[kTrainIndex];
kTrain_y=Y.iloc[kTrainIndex];
kTest_x=higherTrain.iloc[kTestIndex];
kTest_y=Y.iloc[kTestIndex];
higherModelcp.fit(kTrain_x,kTrain_y);
testPre=higherModelcp.predict_proba(kTest_x)[:,1];
giniScore=2*roc_auc_score(kTest_y,testPre)-1;
self.re_score.append(giniScore);
self.modelHigherList.append(higherModelcp);
print('stacker gini',np.array(self.re_score).mean());
def upsample(self,X,Y):
# print('X shape: ',X.shape);
# print('Y shape: ',Y.shape);
data_copy=X.copy(deep=True);
data_copy['label']=Y;
positiveData=data_copy[data_copy['label']==1];
negativeData=data_copy[data_copy['label']==0];
pNum=positiveData.shape[0];
nNum=negativeData.shape[0];
# print('原始负样本数量',nNum);
# print('原始正样本数量',pNum);
if pNum>nNum:
ratio=(int)(pNum/nNum);
for i in range(0,ratio-1):
data_copy=data_copy.append(negativeData,ignore_index=True);
elif nNum>pNum:
ratio=(int)(nNum/pNum);
for i in range(0,ratio-1):
data_copy=data_copy.append(positiveData,ignore_index=True);
# print(data_copy.shape);
# print('负样本数量',data_copy[data_copy['label']==0].shape[0]);
# print('正样本数量',data_copy[data_copy['label']==1].shape[0]);
return data_copy;
def predict_proba(self,X):
#assert type(X)==pd.DataFrame,"X输入必须为DataFrame"
ans=0;
higherX=pd.DataFrame();
for i in range(0,len(self.modelListList)):
for cf in self.modelListList[i]:
if i not in higherX.columns:
higherX[i]=cf.predict_proba(X)[:,1]/len(self.modelListList[i]);
else:
higherX[i]+=cf.predict_proba(X)[:,1]/len(self.modelListList[i]);
ans=0;
for higherModel in self.modelHigherList:
if type(ans)==type(0):
ans=higherModel.predict_proba(higherX)[:,1]/len(self.modelHigherList);
else:
ans+=higherModel.predict_proba(higherX)[:,1]/len(self.modelHigherList);
return ans;class linearBlending:
def __init__(self,paramList,sum_counts):
self.paramList=paramList;
self.sum_counts=sum_counts;
self.bestScore=-1;
self.bestParam=cp.deepcopy(paramList);
def __enumerate(self,sum_counts,paramNum,X,Y):
paramNum-=1;
if paramNum>0:
temp=sum_counts;
for i in range(0,sum_counts+1):
self.paramList[paramNum]=i;
temp=sum_counts-i;
self.__enumerate(temp,paramNum,X,Y);
else:
self.paramList[0]=sum_counts;
pre=self.predict_proba(X)[:,1];
giniScore=2*roc_auc_score(Y,pre)-1;
if giniScore>self.bestScore:
self.bestScore=giniScore;
self.bestParam=cp.deepcopy(self.paramList);
def fit(self,X,Y):
self.bestScore=-1;
self.__enumerate(self.sum_counts,len(self.paramList),X,Y);
self.paramList=cp.deepcopy(self.bestParam);
def predict_proba(self,X):
ans=0;
X=pd.DataFrame(X);
for i in range(0,len(self.paramList)):
if type(ans)==type(0):
ans=X.values[:,i]*self.paramList[i]/self.sum_counts;
else:
ans+=X.values[:,i]*self.paramList[i]/self.sum_counts;
#print(np.vstack((1-ans,ans)).shape);
return np.vstack((1-ans,ans)).T;实际模型融合以及训练
'''
训练stacking分类器
整个分类器分为两层
第一层为gbdt,xgboost,rf
第二层为rf
'''
mlpCf=MLPClassifier(random_state=2099,hidden_layer_sizes=(80,),activation='logistic',solver='adam',alpha=0.0001,batch_size=200,learning_rate='adaptive',shuffle=True,learning_rate_init=0.005,tol=0.00001,power_t=0.4,max_iter=10,beta_1=0.55,beta_2=0.998)
bagMlpCf=BaggingClassifier(base_estimator=mlpCf,n_estimators=150,max_samples=1.0,max_features=0.8,random_state=2066,n_jobs=-1,verbose=1);
cfList=[
xgb.sklearn.XGBClassifier(n_estimators=3800,max_depth=4,seed=5,learning_rate=0.011,subsample=.8,min_child_weight=6,colsample_bytree=.8,scale_pos_weight=1.6, gamma=10,reg_alpha=8,reg_lambda=1.3,silent=False)
# ,xgb.sklearn.XGBClassifier(subsample=0.8,max_depth=6,seed=15,colsample_bytree=0.80,n_estimators=1300,learning_rate=0.01,min_child_weight=2)
# ,xgb.sklearn.XGBClassifier(subsample=0.8,max_depth=4,seed=8,colsample_bytree=0.80,n_estimators=2500,learning_rate=0.01,min_child_weight=4)
# ,lgb.LGBMClassifier(subsample=0.7,colsample_bytree=0.3,feature_fraction=0.9,bagging_freq=1,num_leaves=16,subsample_freq=2,random_state=88,boosting_type='gbdt',n_estimators=2300,learning_rate=0.01)
#,ExtraTreesClassifier(random_state=2019,criterion='entropy',max_features=0.5,max_depth=16,min_samples_split=200,n_estimators=100,n_jobs=-1)
,bagMlpCf
,lgb.LGBMClassifier(subsample=0.8,colsample_bytree=0.8,max_bin=10,subsample_freq=10,min_child_samples=500,max_depth=9,random_state=666,boosting_type='gbdt',n_estimators=1200,learning_rate=0.01,verbose=1)
# ,GradientBoostingClassifier(max_depth=6,n_estimators=100,random_state=132,subsample=0.8,max_features=0.8,min_samples_leaf=200)
,CatBoostClassifier(verbose=True,depth=8,iterations=200,learning_rate=0.1,eval_metric='AUC',bagging_temperature=0.8,l2_leaf_reg=4,rsm=0.8,random_seed=10086)
];
higherCf=linearBlending([0,0,0,0],20);
#higherCf=LogisticRegression();
stackerCf=stacker(cfList,higherCf,kFold=StratifiedKFold(n_splits=5,random_state=1))
stackerCf.fit(train_data_train_x,train_data_train_y,upsample=False);预测结果并输出
ans=stackerCf.predict_proba(test_data[train_data_train_x.columns]);
ans=pd.DataFrame({'id':test_data['id'],'target':ans});
ans.to_csv("/home/lj407/Data/Lxy_data/kaggle/PortoPrediction/submit.csv",columns=['id','target'],index=False);
print('end');