任务调度框架Oozie学习笔记
目录
1. 工作流调度框架Oozie功能初步认识
2. 几种调度框架讲解
3. Oozie 功能架构及三大Server讲解
4. Oozie安装部署
5. Oozie案例运行MapReduce Wordflow讲解
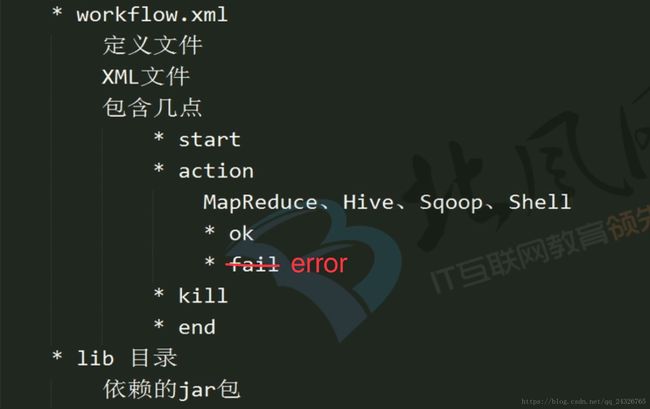
6. 如何定义OoozieWorkflow讲解
7. Oozie Workflow中MapReduce Action定义讲解
8. 编写OozieWorkflow的MapReduceAction并运行
9. WorkFlow中Hive Action使用案例讲解
10. Oozie WorkFlow中Sqoop Action使用案例讲解
11. Oozie WorkFlow中Shell Action使用案例讲解
12. Oozie Coordinator调度讲解及系统时区配置与定时触发两种配置方式
13. Oozie Coordinator配置定时触发案例演示
14. Oozie Coordinator配置调度MapReduce WordCount程序
15. Oozie企业使用案例(Hive Action、Sqoop Actoion及定时调度)
16. Oozie中Coordinator中的数据可用性及Bundle讲解
1. 工作流调度框架Oozie功能初步认识

2. 几种调度框架讲解

Linux Crontab:
针对每个用户而言的
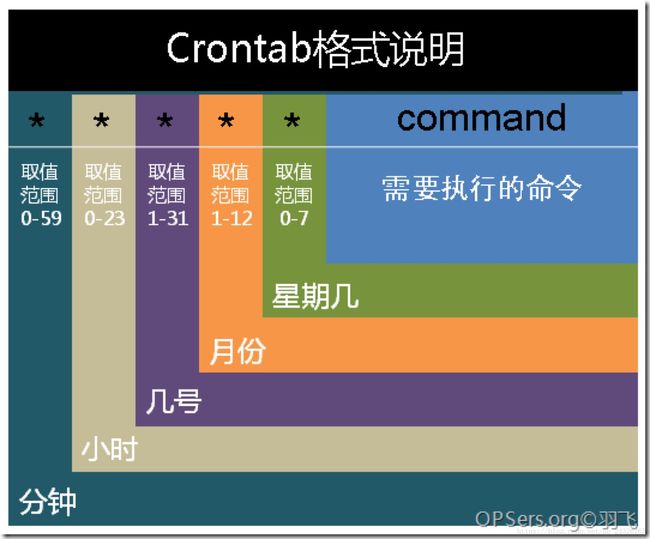



实例:
每分钟写一次日期到bf-date.log


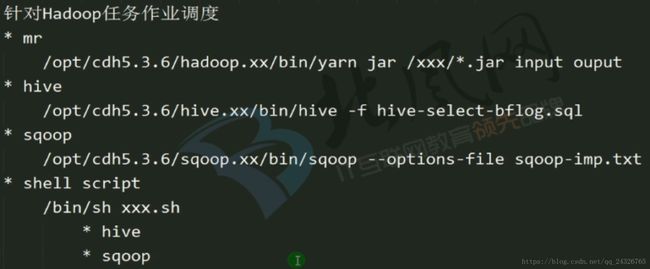
缺点:不能回滚、不易管理
Azkaban:
比Oozie简单,但是功能有限。
Oozie:
多用于数据仓库、ETL;但是使用困难。
Zeus:
阿里、一号店在用;增加了监控界面;使用简单。
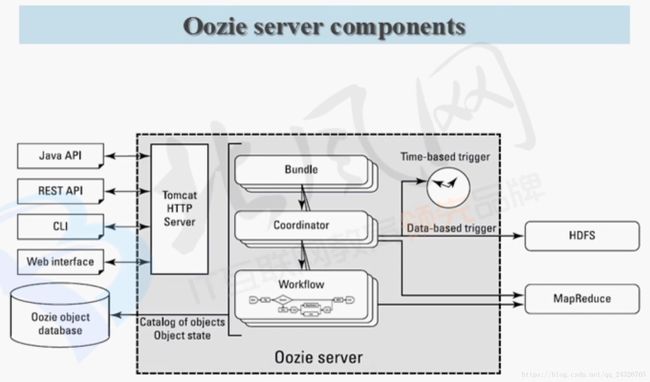
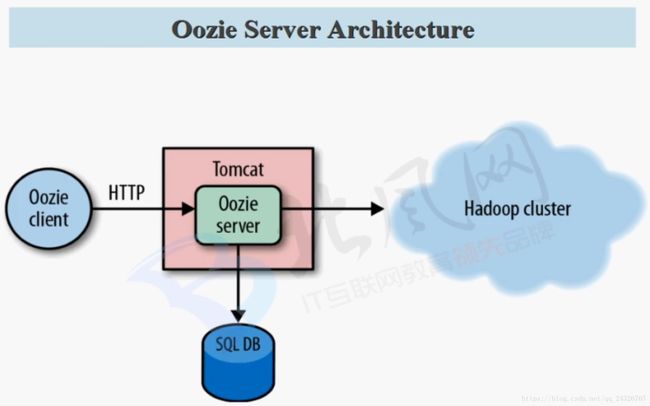
3. Oozie 功能架构及三大Server讲解





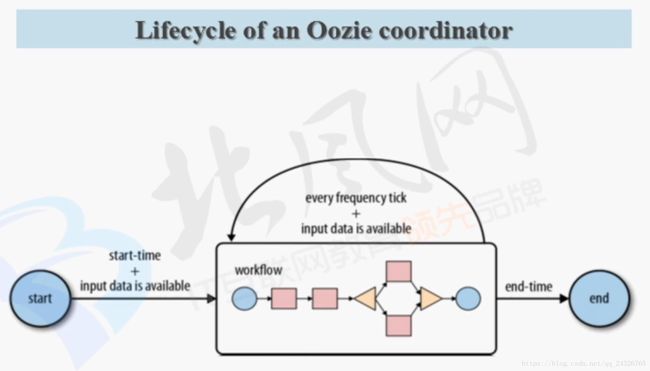
(coordinator也是一个任务,封装了workflow,设置开始和结束时间。)
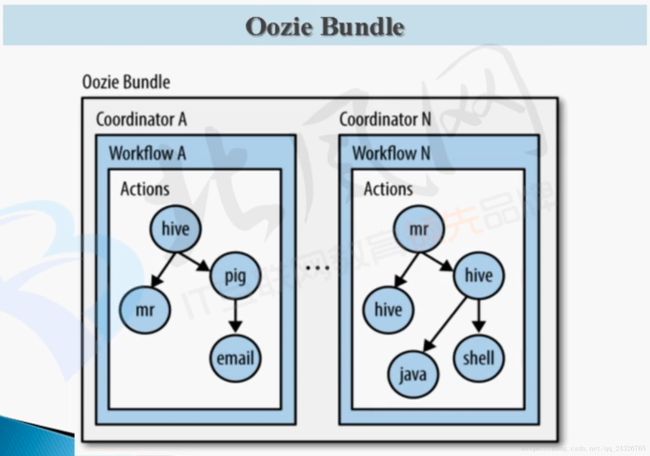
bundle绑定了多个coordinator,可批量停止、挂起、关闭、开启。Oozie独有的功能。
4. Oozie安装部署
如果需要编译安装,可查看官网文档的quick start:

安装cdh版本:
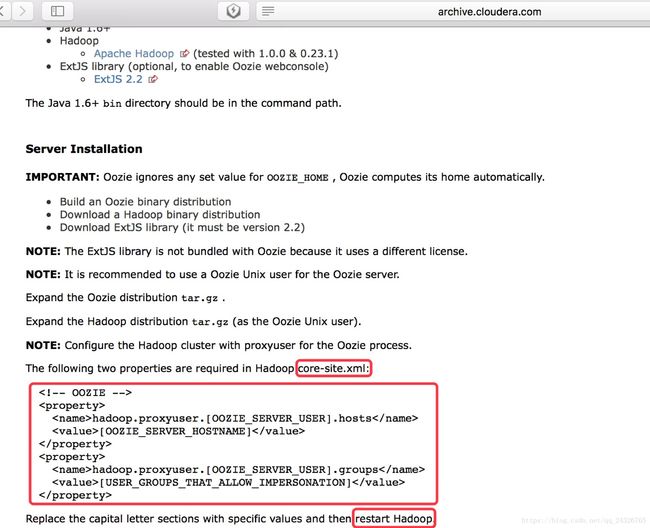
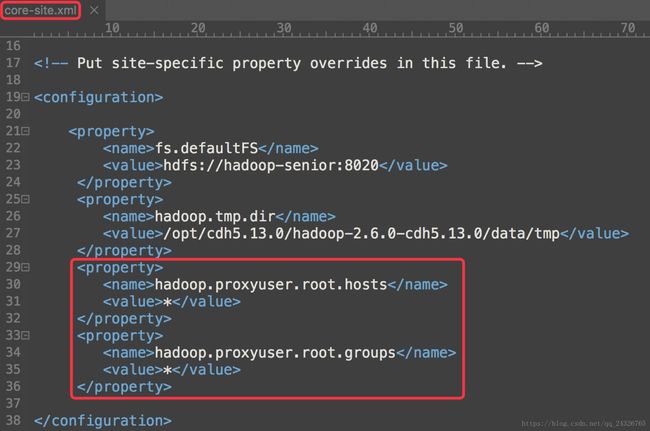
① 在core-site.xml中添加代理用户
-
<property>
-
<name>hadoop.proxyuser.root.hosts
name>
-
<value>*
value>
-
property>
-
<property>
-
<name>hadoop.proxyuser.root.groups
name>
-
<value>*
value>
-
property>
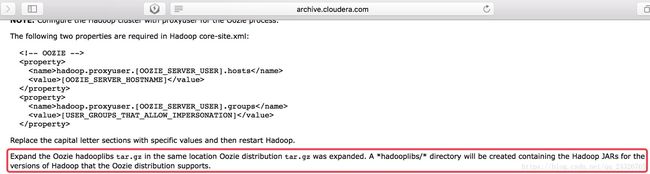
② 解压oozie-hadooplibs-4.1.0-cdh5.13.0.tar.gz
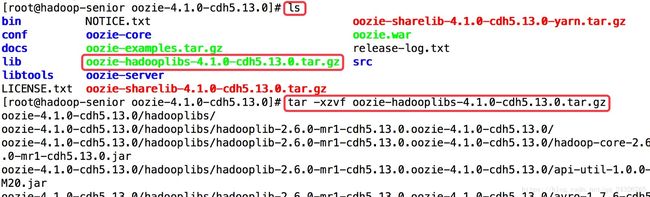


③ 创建libext目录,并放入mapreduce2的jar包


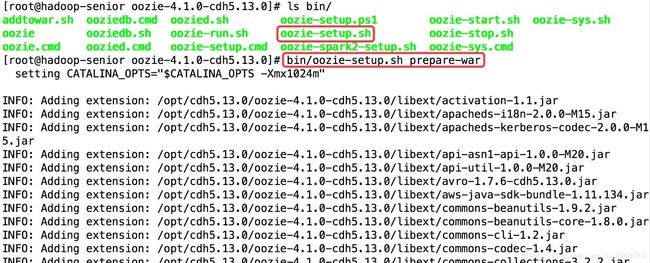
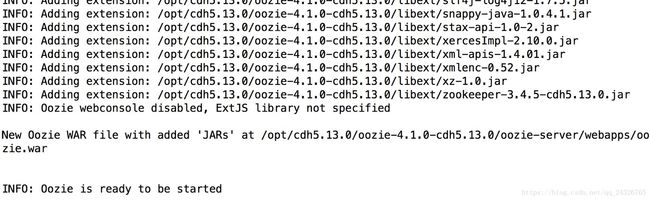
④ 准备war包:将jar包添加到war包中供tomcat使用

⑤ 将oozie支持的组件jar包上传到hdfs上

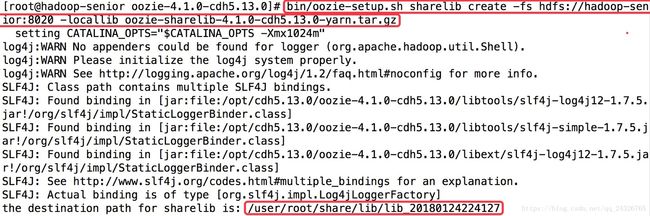
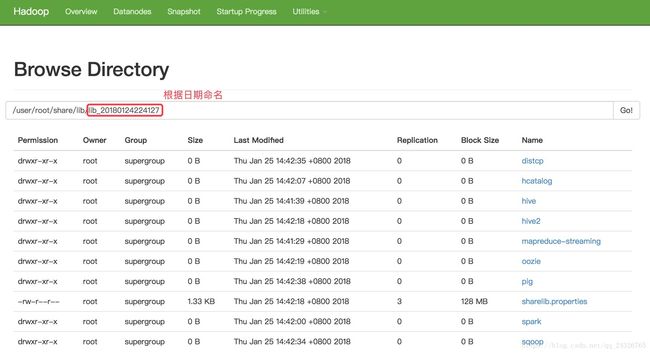
如果出现异常:
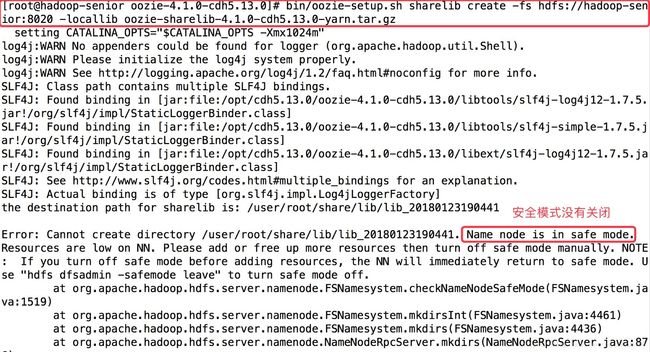
解决:关闭安全模式

⑥ 修改oozie使用的数据库
默认使用的是derby数据库(在实际生产环境中使用的是mysql):
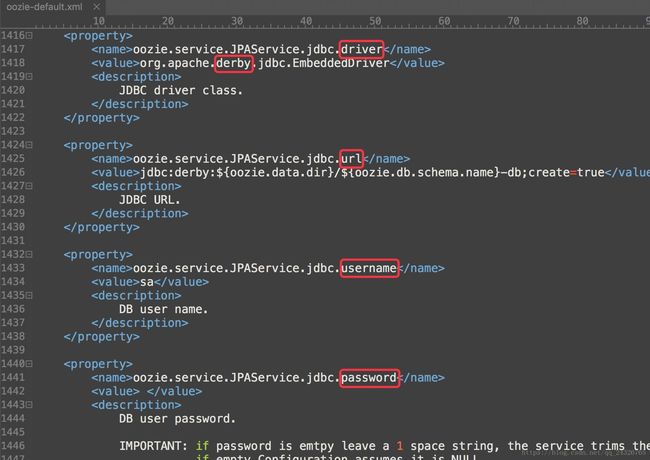
修改后:
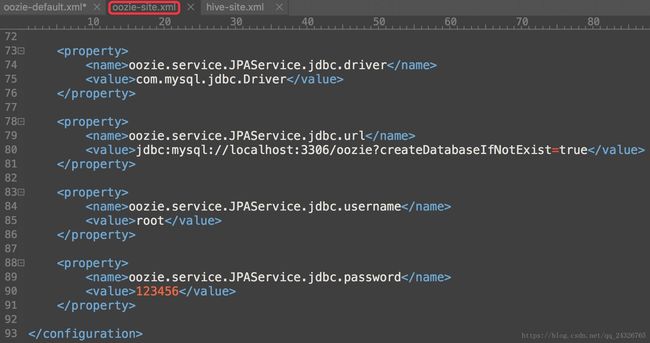
-
<property>
-
<name>oozie.service.JPAService.jdbc.driver
name>
-
<value>com.mysql.jdbc.Driver
value>
-
property>
-
-
<property>
-
<name>oozie.service.JPAService.jdbc.url
name>
-
<value>jdbc:mysql://localhost:3306/oozie?createDatabaseIfNotExist=true
value>
-
property>
-
-
<property>
-
<name>oozie.service.JPAService.jdbc.username
name>
-
<value>root
value>
-
property>
-
-
<property>
-
<name>oozie.service.JPAService.jdbc.password
name>
-
<value>123456
value>
-
property>
重启oozie后,查看日志,发现异常:
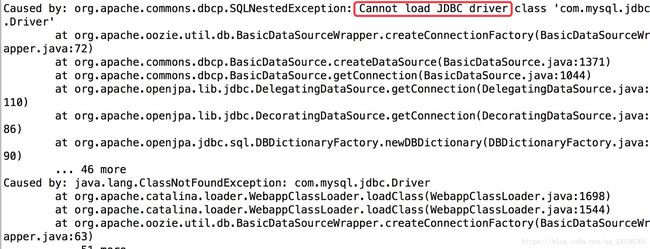
将mysql驱动放入libext和lib中,重新准备war包:
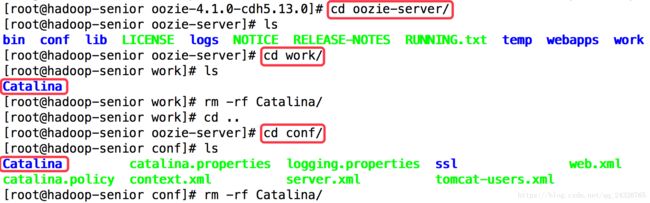
如果在启动时出现已启动,或者关闭时找不到pid,删除原来的pid文件:
[root@hadoop-senior oozie-4.1.0-cdh5.13.0]# rm -f oozie-server/temp/oozie.pid重新add jar包
[root@hadoop-senior oozie-4.1.0-cdh5.13.0]# bin/oozie-setup.sh prepare-war
重新生成sql脚本:
[root@hadoop-senior oozie-4.1.0-cdh5.13.0]# bin/ooziedb.sh create -sqlfile oozie.sql -run DB Connection
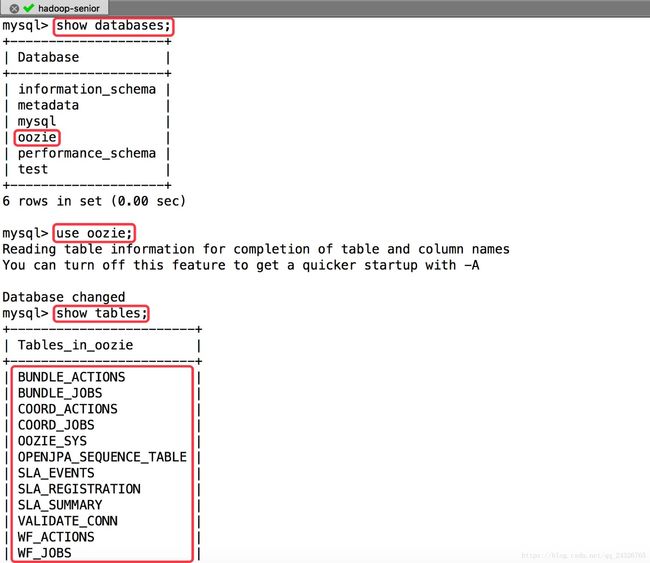
查看mysql:
⑦ 创建oozie需要使用的sql脚本(如果第⑥步执行过了就跳过)
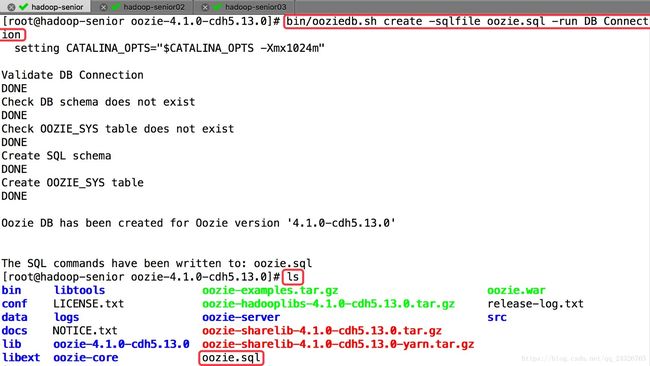
查看脚本:
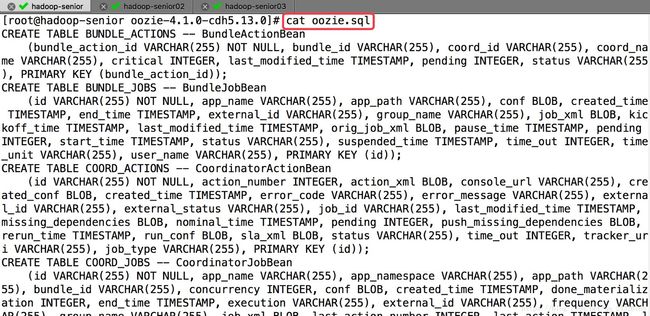
⑧ 启动oozie守护进程(其实就是启动tomcat):
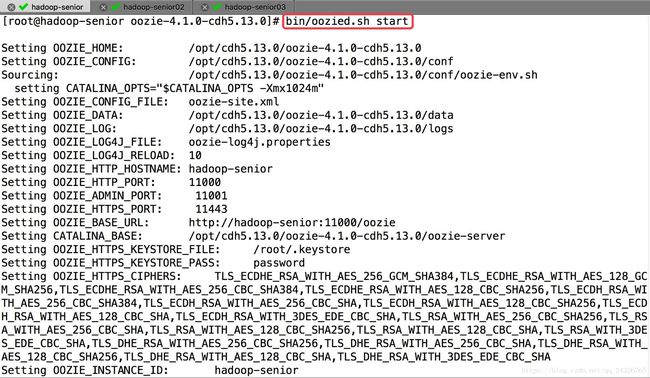

查看日志,如果出现如下异常:

(说明oozie读取的是本地路径,而不是hdfs路径)
解决:在oozie-site.xml中配置hadoop的配置文件路径
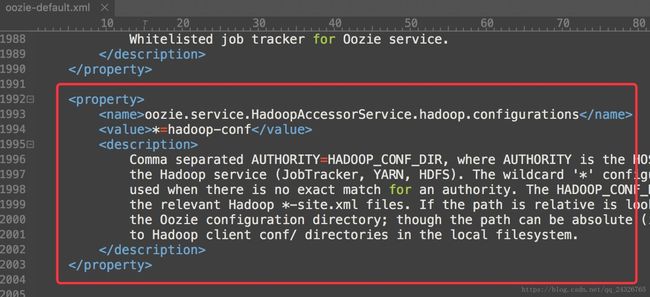
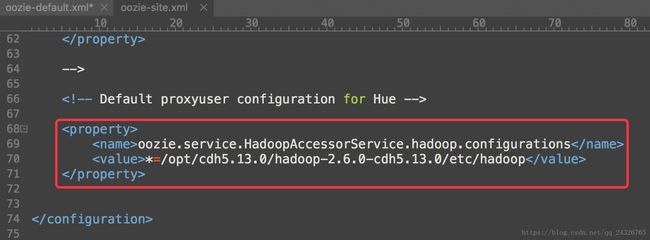
-
<property>
-
<name>oozie.service.HadoopAccessorService.hadoop.configurations
name>
-
<value>*=/opt/cdh5.13.0/hadoop-2.6.0-cdh5.13.0/etc/hadoop
value>
-
property>
⑨ 查看:
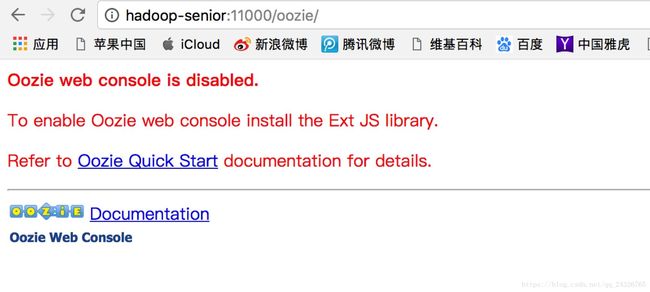
会发现,需要extjs library,可在oozie文档中点击下载:


关闭oozie后进行如下操作:
![]()

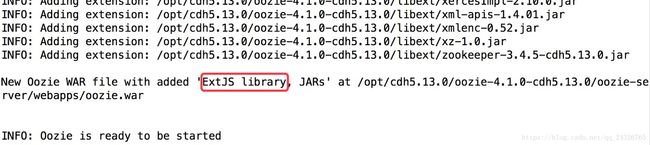
开启oozie:
5. Oozie案例运行MapReduce Wordflow讲解

① 解压oozie-examples.tar.gz

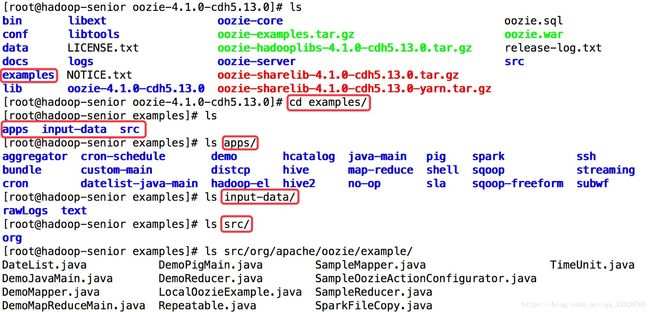
② 将解压的案例上传到hdfs
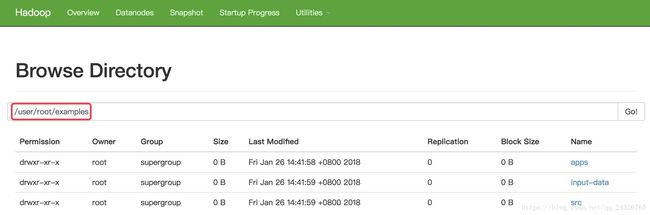
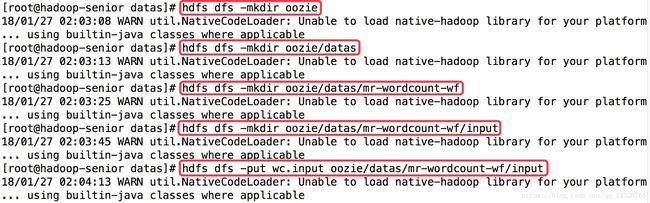
[root@hadoop-senioroozie-4.1.0-cdh5.13.0]# hdfs dfs -put examples examples(不写绝对路径,默认的是用户的主目录。例如:/user/root/)
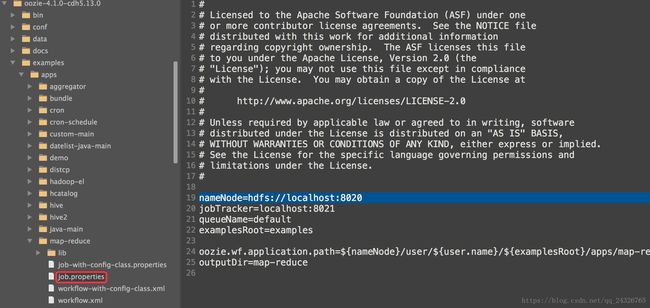
③ 修改job.properties
先看本机的程序运行的主机和端口和job.properties中的是否一致
job.properties:
![]()
本机:
修改job.properties:
修改前
修改后

(workflow.xml必须在hdfs上,因为整个集群要访问)
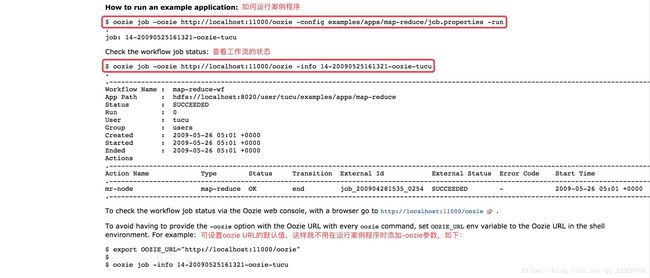
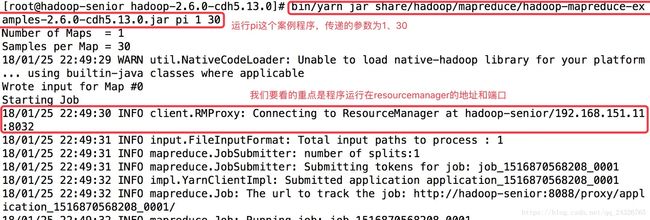
④ 运行案例程序


[root@hadoop-senior oozie-4.1.0-cdh5.13.0]# bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run
(如果设置了OOZIE_URL如:exportOOZIE_URL= http://localhost:11000/oozie可直接bin/oozie job -configexamples/apps/map-reduce/job.properties -run)
为什么是两个mapreduce?oozie本身就是一个mapreduce,而程序也是一个mapreduce。
注意:如果运行了该程序,yarn8088端口查看,mapreduce无反应,且oozie界面,mapreduce一直是running状态:
 查看程序运行状态仍然是running
查看程序运行状态仍然是running
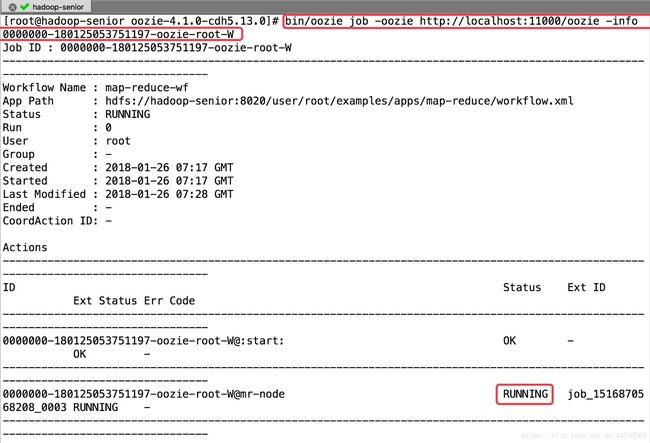
引出异常unhealthy node:

解决:原因就是磁盘的空间太满了,跟yarn-site.xml中的以下配置有关:

-
<property>
-
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage
name>
-
<value>98.5
value> //默认是90
-
property>
你可以清理磁盘空间,或者你可以暂时的吧这个使用率调大,但是这不是解决问题的根本,最好是清理磁盘空间或扩展。
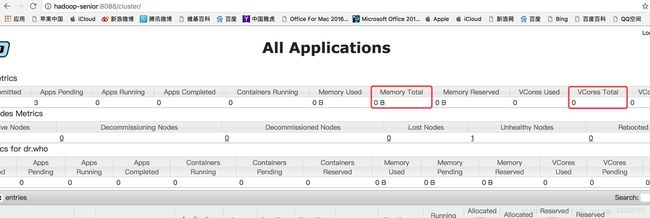
异常2:如果没有unhealthy node ,yarn 8088页面显示mapreduce运行成功,但是oozie仍然是running,最后SUSPENDED (但是运行成功),说明分配的资源不够。
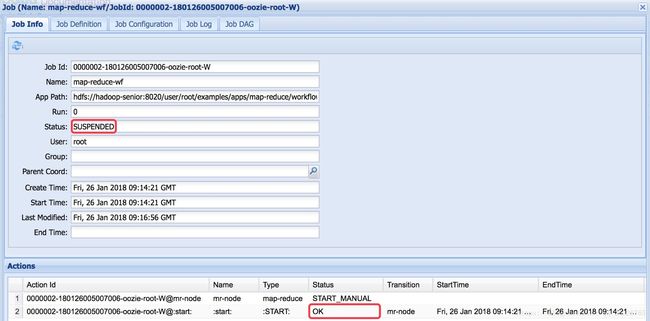
解决:调整Memory Total和VCores Total。
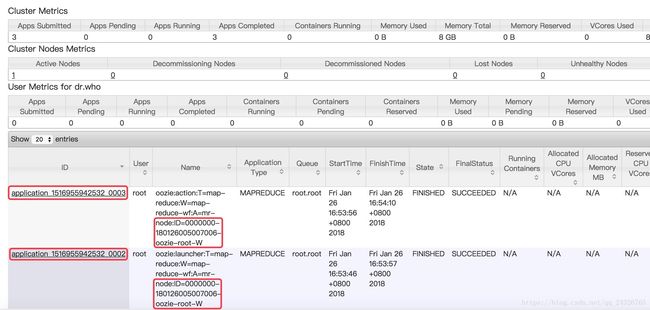
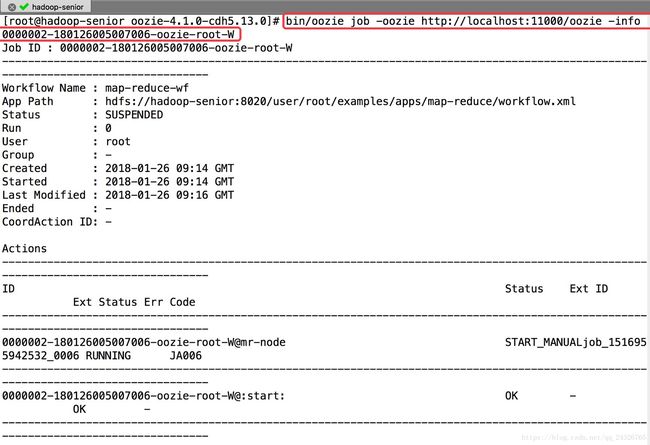
⑤ 查看

查看程序运行状态:
6. 如何定义OoozieWorkflow讲解



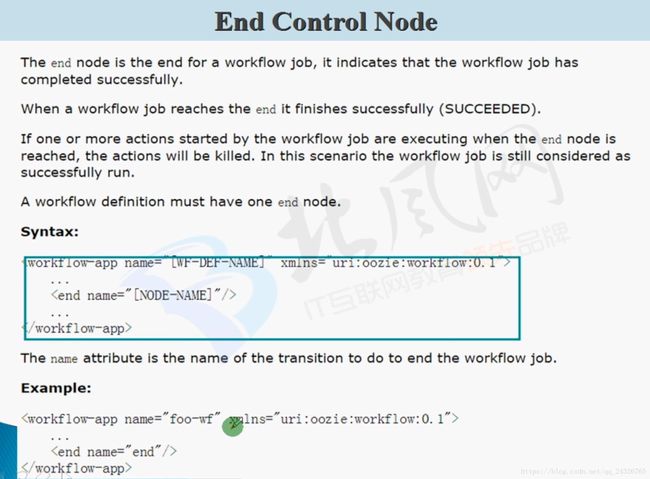

7. Oozie Workflow中MapReduce Action定义讲解


![]()





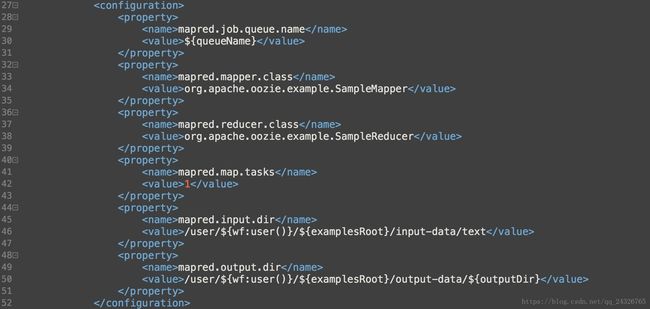
(oozie不用创建driver,直接配置属性就行)
8. 编写OozieWorkflow的MapReduceAction并运行


① 复制修改example中的实例

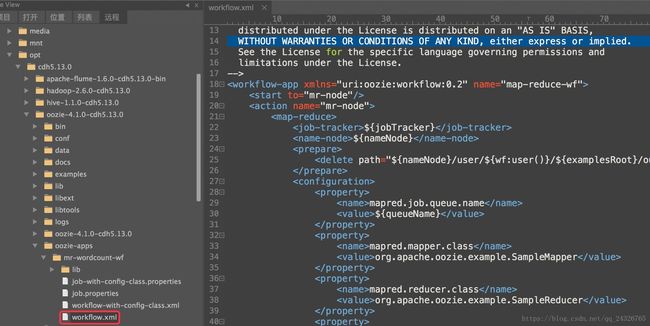
-
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
-
<start to="mr-node"/>
-
<action name="mr-node">
-
<map-reduce>
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<prepare>
-
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
-
prepare>
-
<configuration>
-
<property>
-
<name>mapred.job.queue.name
name>
-
<value>${queueName}
value>
-
property>
-
<property>
-
<name>mapred.mapper.class
name>
-
<value>org.apache.oozie.example.SampleMapper
value>
-
property>
-
<property>
-
<name>mapred.reducer.class
name>
-
<value>org.apache.oozie.example.SampleReducer
value>
-
property>
-
<property>
-
<name>mapred.map.tasks
name>
-
<value>1
value>
-
property>
-
<property>
-
<name>mapred.input.dir
name>
-
<value>/user/${wf:user()}/${examplesRoot}/input-data/text
value>
-
property>
-
<property>
-
<name>mapred.output.dir
name>
-
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}
value>
-
property>
-
configuration>
-
map-reduce>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
<kill name="fail">
-
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
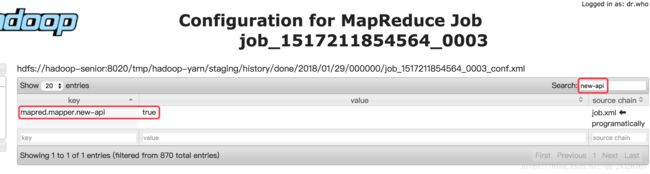
因为案例中的是mapreduce1所以要修改成mapreduce2,方法1:在hadoop xml文档中查找,方法2:在yarn的History-->Configuration页面查找(这种方法是你运行的job中设置的有才会找到)。
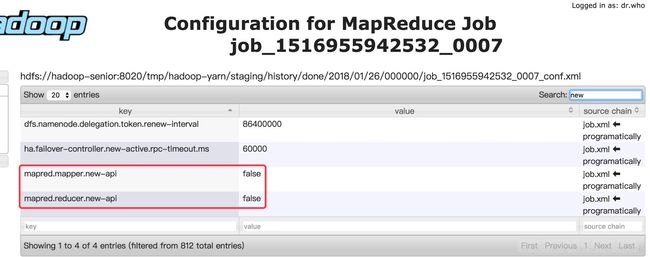
(Oozie默认调用的是老的mapreduce,所以开启新的mapredce(设置为true),否则会报错

)

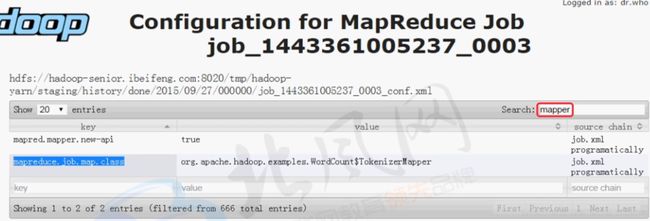
……
修改后如下图:
job.properties
nameNode=hdfs://hadoop-senior:8020
jobTracker=hadoop-senior:8032
queueName=default
//这里设置值,以供workflow.xml引用
//设置路径时,前后最好都不要加/,避免在写路径时不知道该不该加/
oozieAppsRoot=user/root/oozie-apps
oozieDataRoot=user/root/oozie/datas
oozie.wf.application.path=${nameNode}/${oozieAppsRoot}/mr-wordcount-wf/workflow.xml
inputDir=mr-wordcount-wf/input
outputDir=mr-wordcount-wf/output
workflow.xml
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="mr-wordcount-wf">
-
//名称设置不要超过20个字符
-
<start to="mr-node-wordcount"/>
-
<action name="mr-node-wordcount">
-
<map-reduce>
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<prepare>
-
<delete path="${nameNode}/${oozieAppsRoot}/${outputDir}"/>
-
prepare>
-
//整体设置和java代码中设置job的步骤一致。
-
<configuration>
-
<property>
-
<name>mapred.mapper.new-api
name>
-
<value>true
value>
-
property>
-
<property>
-
<name>mapred.reducer.new-api
name>
-
<value>true
value>
-
property>
-
<property>
-
<name>mapreduce.job.queuename
name>
-
<value>${queueName}
value>
-
property>
-
<property>
-
<name>mapreduce.job.map.class
name>
-
<value> com.zhuyu.mapreduce.WordCount$WordCountMapper
value>
-
property>
-
<property>
-
<name>mapreduce.job.reduce.class
name>
-
<value> com.zhuyu.mapreduce.WordCount$WordCountReducer
value>
-
property>
-
//当map的输入输出和reduce的输入输出一致,可不用设置map的输入输出
-
<property>
-
<name>mapreduce.map.output.key.class
name>
-
<value>org.apache.hadoop.io.Text
value>
-
property>
-
<property>
-
<name>mapreduce.map.output.value.class
name>
-
<value>org.apache.hadoop.io.IntWritable
value>
-
property>
-
<property>
-
<name>mapreduce.job.output.key.class
name>
-
<value>org.apache.hadoop.io.Text;
value>
-
property>
-
<property>
-
<name>mapreduce.job.output.value.class
name>
-
<value>org.apache.hadoop.io.IntWritable
value>
-
property>
-
// 默认多少个块就有多少个mapreduce,所以删除
-
-
<property>
-
<name>mapreduce.input.fileinputformat.inputdir
name>
-
<value>${nameNode}/${oozieDatasRoot}/${inputDir}
value>
-
property>
-
<property>
-
<name>mapreduce.output.fileoutputformat.outputdir
name>
-
<value>${nameNode}/${oozieAppsRoot}/${outputDir}
value>
-
property>
-
-
configuration>
-
map-reduce>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
<kill name="fail">
-
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
(千万不要有注释,否则会出错)
② 将自己编写的mapreduce jar包放在lib目录下

③ 将程序放到hdfs上,并准备input数据
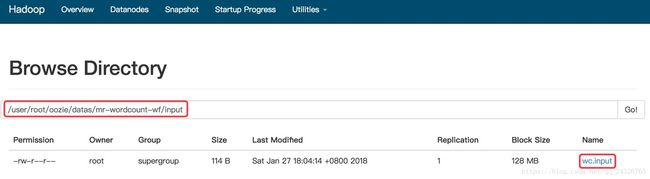
[root@hadoop-senioroozie-4.1.0-cdh5.13.0]# hdfs dfs -put oozie-apps/ oozie-apps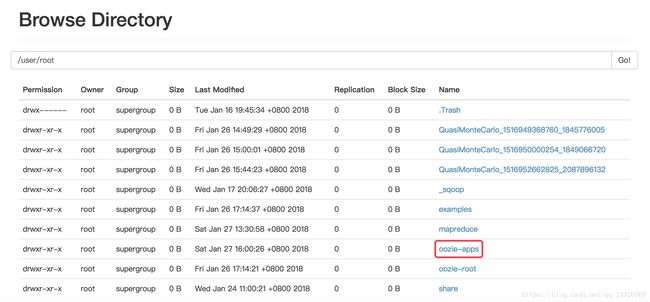
④ 运行程序

YARN:
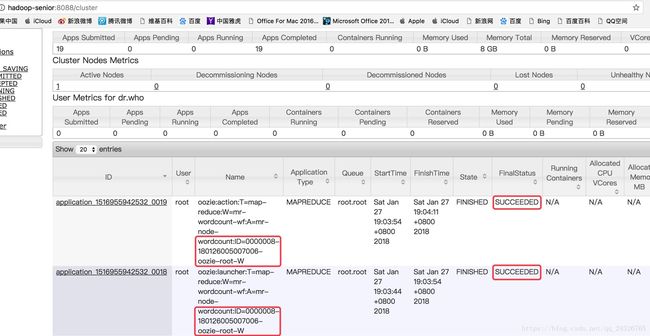
(如果出错查看logs/oozie.log日志)
OOZIE:
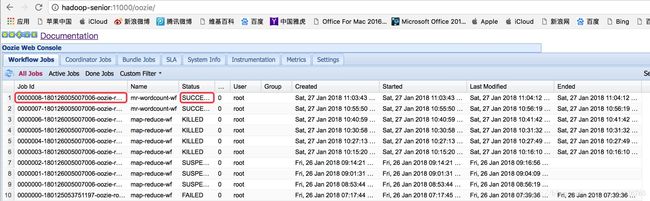
输出文件:
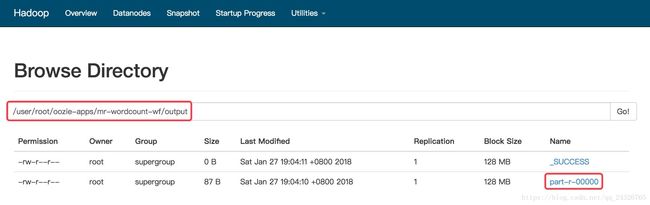
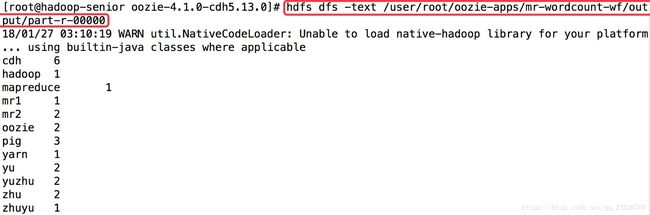
9. WorkFlow中Hive Action使用案例讲解
文档:
http://hadoop-senior:11000/oozie/docs/DG_HiveActionExtension.html
① 复制案例到oozie-apps下

② 修改job.properties
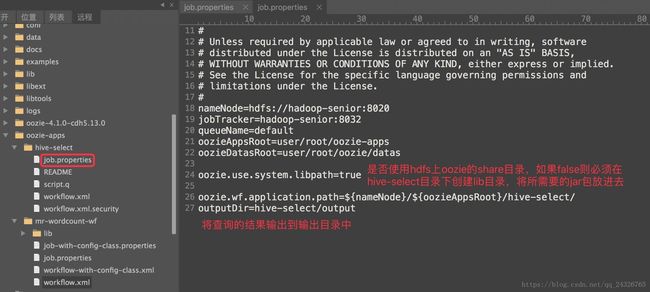
-
nameNode=hdfs:
//hadoop-senior:8020
-
jobTracker=hadoop-senior:
8032
-
queueName=
default
-
oozieAppsRoot=user/root/oozie-apps
-
oozieDatasRoot=user/root/oozie/datas
-
-
-
oozie.use.system.libpath=
true
-
// xml可指定可不指定,不指定的话会自动在该目录下找
-
oozie.wf.application.path=${nameNode}/${oozieAppsRoot}/hive-
select/
-
outputDir=hive-
select/output
② 将hive配置文件复制到hive-select目录下(为⑤做铺垫)

③ 创建lib目录,将mysql驱动放入

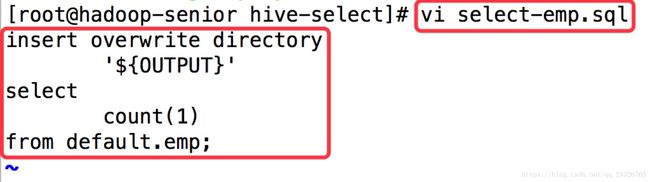
④ 修改hive脚本文件(为⑤做铺垫)
[root@hadoop-senior hive-select]# mv script.q select-emp.sql
⑤ 修改workflow.xml
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="wf-hive-select">
-
<start to="hive-node"/>
-
<action name="hive-node">
-
<hive xmlns="uri:oozie:hive-action:0.2">
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<prepare>
-
<delete path="${nameNode}/${oozieAppsRoot}/${outputDir}"/>
-
prepare>
-
<job-xml>${nameNode}/${oozieAppsRoot}/hive-select/hive-site.xml
job-xml>
-
<configuration>
-
<property>
-
<name>mapred.job.queue.name
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
<script>
select-emp.sql
script>
-
<param>OUTPUT=${nameNode}/${oozieAppsRoot}/${outputDir}
param>
-
hive>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
-
<kill name="fail">
-
<message>Hive failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
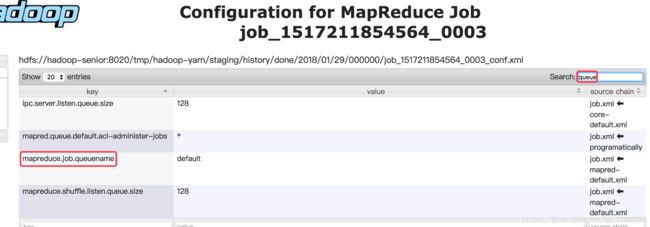
查看是否使用的是新的api:使用hive运行一个mapreduce语句,例如select count(1) from emp;然后在yarn web页面查看。

(所以使用的是旧的api)
要添加
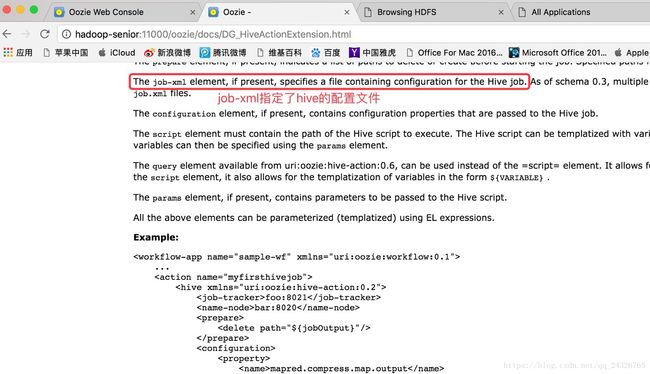
否则会出现以下异常:
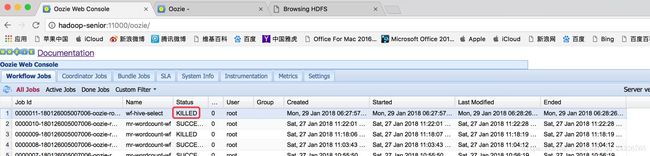
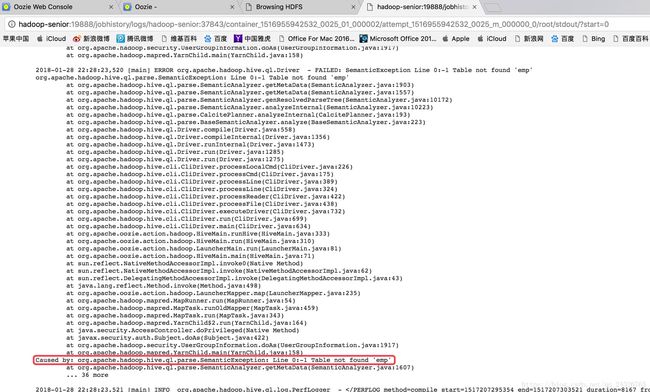
如果在运行oozie任务时,oozie服务强制关闭了,但是查不到错误?
方法一:但是yarn web页面查看任务完成了,说明资源的问题,在重新运行前,jps查看服务,kill掉占用资源的任务。
方法二:workflow.xml内路径配置错误,查看yarn日志和oozie.log。
方法三:磁盘容量不足,清理磁盘(df –lh查看)。
情况四:重启虚拟机。
杀死oozie任务:
[root@hadoop-senior oozie-4.1.0-cdh5.13.0]# bin/oozie job -kill 0000000-180128225452391-oozie-root-W
⑥ 运行
![]()
-
export OOZIE_URL=http:
//hadoop-senior:11000/oozie/
-
bin/oozie job --config oozie-apps/hive-
select/job.properties -run
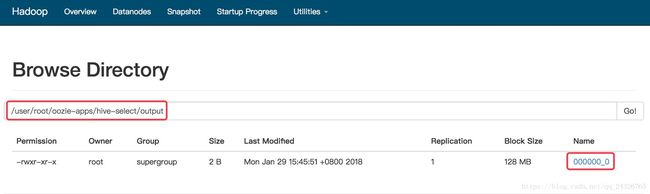
⑦ 查看:



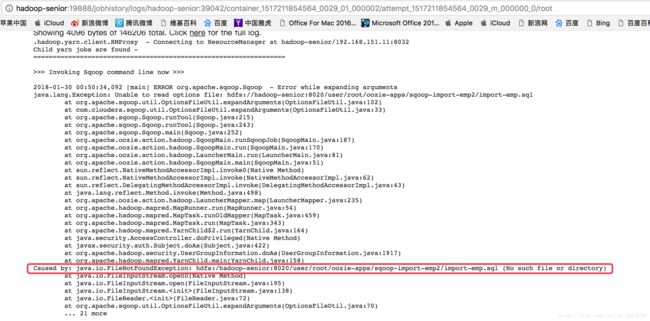
10. Oozie WorkFlow中Sqoop Action使用案例讲解
① 复制样本案例
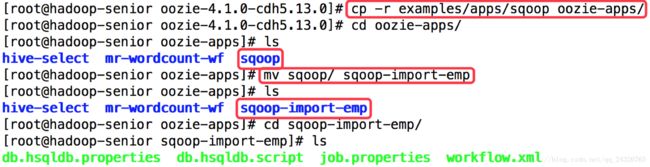
db.hsqldb.properties属性文件
db.hsqldb.script脚本文件
二者都可删除
② 在sqoop-import-emp下创建lib,并将mysql驱动放入

cp /opt/software/mysql-connector-java-5.1.32-bin.jar oozie-apps/sqoop-import-emp/lib/
③ 测试是老api还是新api
在mysql中建表:
-
create
table
`my_user`(
-
`id` tinyint(
4)
not
null auto_increment,
-
`acount`
varchar(
255)
default
null,
-
`password`
varchar(
255)
default
null,
-
primary
key(
`id`)
-
);
-
insert
into
`my_user`
values(
'1',
'admin',
'admin');
-
insert
into
`my_user`
values(
'2',
'pu',
'pu');
-
insert
into
`my_user`
values(
'3',
'system',
'system');
-
insert
into
`my_user`
values(
'4',
'zxh',
'zxh');
-
insert
into
`my_user`
values(
'5',
'test',
'test');
-
insert
into
`my_user`
values(
'6',
'pudong',
'pudong');
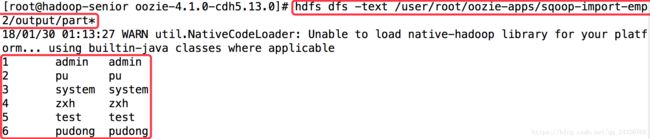
将mysql中的数据导入到hdfs:
-
bin/sqoop import \
-
--connect jdbc:mysql://hadoop-senior:3306/test \
-
--username root \
-
--password 123456 \
-
--table my_user \
-
--target-dir /user/root/oozie/datas/sqoop-import-user/output \
-
--num-mappers 1
④ 修改job.properties
-
nameNode=hdfs:
//hadoop-senior:8020
-
jobTracker=hadoop-senior:
8032
-
queueName=
default
-
oozieAppsRoot=user/root/oozie-apps
-
oozieDatasRoot=user/root/oozie/datas
-
-
oozie.use.system.libpath=
true
-
-
oozie.wf.application.path=${nameNode}/${oozieAppsRoot}/sqoop-
import-emp/
-
outputDir=sqoop-
import-emp/output
⑤ 修改workflow.xml
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="sqoop-wf">
-
<start to="sqoop-node"/>
-
-
<action name="sqoop-node">
-
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<prepare>
-
<delete path="${nameNode}/${oozieAppsRoot}/${outputDir}"/>
-
prepare>
-
<configuration>
-
<property>
-
<name>mapreduce.job.queuename
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
// 命令前不需要sqoop
-
// 可通过--fields-terminated-by "分隔符" 进行字段分割
-
<command>import --connect jdbc:mysql://hadoop-senior:3306/test --username root --password 123456 --table my_user --target-dir ${nameNode}/${oozieAppsRoot}/${outputDir} --num-mappers 1
command>
-
sqoop>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
-
<kill name="fail">
-
<message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
⑥ 运行
-
[root@hadoop-senior oozie-
4.1.
0-cdh5.
13.0]
# export OOZIE_URL=http://hadoop-senior:11000/oozie/
-
[root@hadoop-senior oozie-
4.1.
0-cdh5.
13.0]
# bin/oozie job -config oozie-apps/sqoop-import-emp/job.properties –run
⑦ 复制样本案例

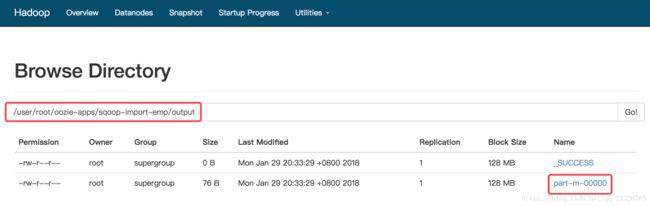
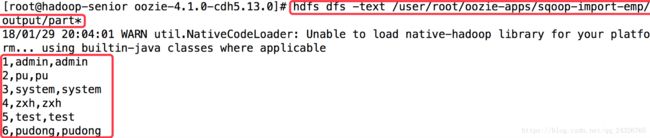
⑧ 可能出现的异常
异常(没有放置mysql驱动包/驱动包版本问题):
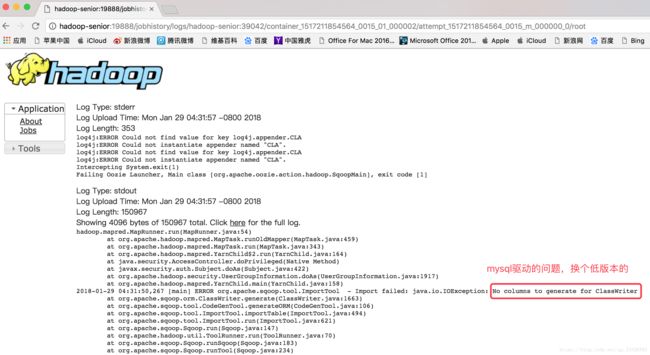
补充:
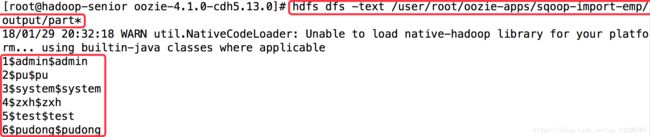
1. 将分隔符设定为$$$
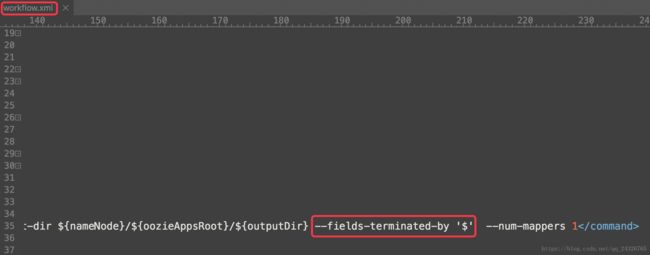
查看运行结果后发现格式并不正确
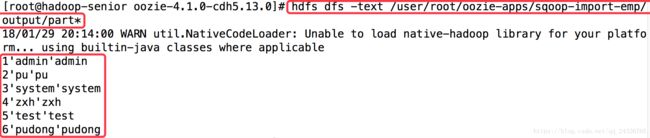
应将单引号变为双引号
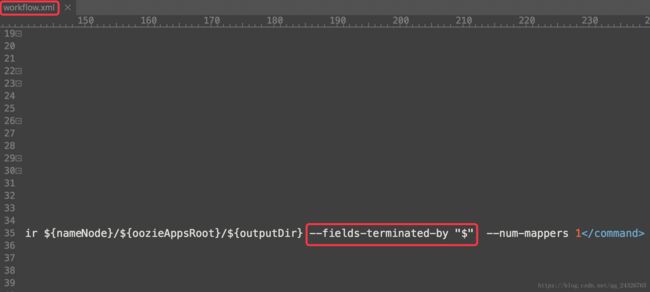
--fields-terminated-by "$"
2.
脚本文件:

脚本文件上传到hdfs上(暂未解决):


脚本文件在本地(暂未解决):


3.
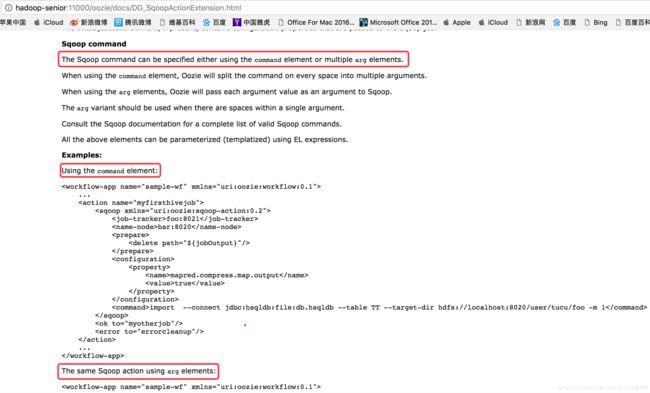

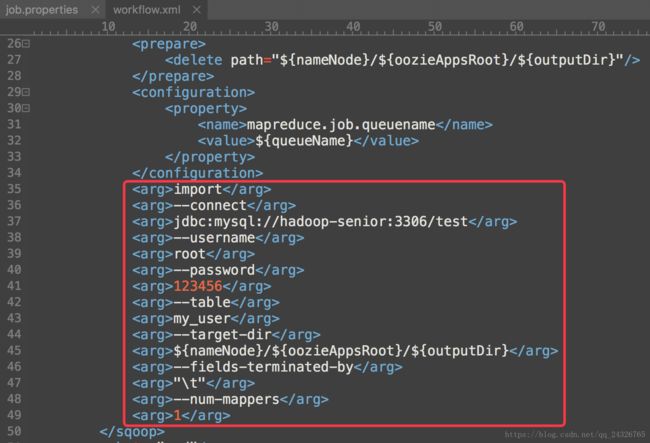
-
<arg>import
arg>
-
<arg>--connect
arg>
-
<arg>jdbc:mysql://hadoop-senior:3306/test
arg>
-
<arg>--username
arg>
-
<arg>root
arg>
-
<arg>--password
arg>
-
<arg>123456
arg>
-
<arg>--table
arg>
-
<arg>my_user
arg>
-
<arg>--target-dir
arg>
-
<arg>${nameNode}/${oozieAppsRoot}/${outputDir}
arg>
-
<arg>--fields-terminated-by
arg>
-
<arg>"\t"
arg>
-
<arg>--num-mappers
arg>
-
<arg>1
arg>


11. Oozie WorkFlow中Shell Action使用案例讲解
① 拷贝shell样本案例

② 编写shell脚本和hive脚本
hive脚本:
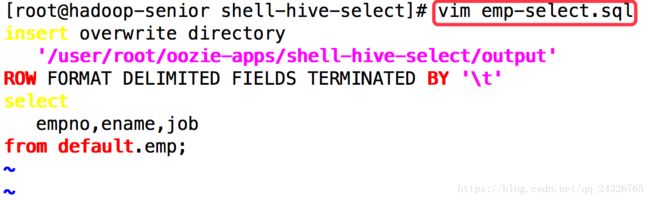
-
insert overwrite
directory
-
'/user/root/oozie-apps/shell-hive-select/output'
-
ROW
FORMAT
DELIMITED
FIELDS
TERMINATED
BY
'\t'
-
select
-
empno,ename,job
-
from default.emp;
shell脚本:
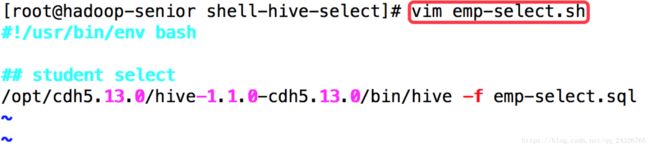
-
#!/usr/bin/env bash
-
-
## student select
-
/opt/cdh5.13.0/hive-1.1.0-cdh5.13.0/bin/hive -f emp-select.sql
③ 修改job.properties
-
nameNode=hdfs:
//hadoop-senior:8020
-
jobTracker=hadoop-senior:
8032
-
queueName=
default
-
oozieAppsRoot=user/root/oozie-apps
-
oozieDatasRoot=user/root/oozie/datas
-
-
oozie.wf.application.path=${nameNode}/${oozieAppsRoot}/shell-hive-
select
-
-
exec=emp-
select.sh
-
script=emp-
select.sql
④ 修改workflow.xml
修改前:
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="shell-wf">
-
<start to="shell-node"/>
-
<action name="shell-node">
-
<shell xmlns="uri:oozie:shell-action:0.2">
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<configuration>
-
<property>
-
<name>mapred.job.queue.name
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
<exec>echo
exec>
-
<argument>my_output=Hello Oozie
argument>
-
<capture-output/>
-
shell>
-
<ok to="check-output"/>
-
<error to="fail"/>
-
action>
-
<decision name="check-output">
-
<switch>
-
<case to="end">
-
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
-
case>
-
<default to="fail-output"/>
-
switch>
-
decision>
-
<kill name="fail">
-
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<kill name="fail-output">
-
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
修改后:
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="shell-wf">
-
<start to="shell-node"/>
-
<action name="shell-node">
-
<shell xmlns="uri:oozie:shell-action:0.2">
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<configuration>
-
<property>
-
<name>mapred.job.queue.name
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
// shell脚本名称
-
<exec>${exec}
exec>
-
// 将shell脚本和hive脚本放到计算节点当前的工作目录
-
// 前面的是shell脚本在hdfs的路径,#${exec}代表是该路径的简称
-
<file>${nameNode}/${oozieAppsRoot}/shell-hive-select/${exec}#${exec}
file>
-
<file>${nameNode}/${oozieAppsRoot}/shell-hive-select/${script}#${script}
file>
-
<capture-output/>
-
shell>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
<kill name="fail">
-
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
(本例中不使用<job-xml>是因为在shell脚本中使用的hive命令会自动在hive配置文件目录下寻找配置文件)
为什么要使用
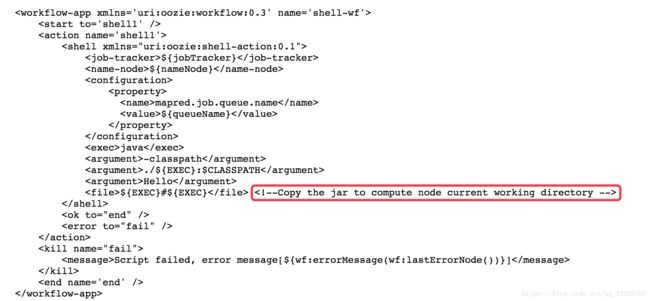

nm-local-dir是namenode的本地目录,![]() 是分布式缓存文件,mapreduce在运行的时候会自动将文件从hdfs拷贝到这里。
是分布式缓存文件,mapreduce在运行的时候会自动将文件从hdfs拷贝到这里。
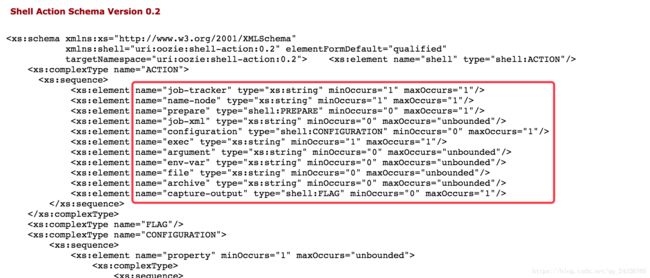
标签要有序:
⑤ 运行
-
[root@hadoop-senior oozie-
4.1.
0-cdh5.
13.0]
# export OOZIE_URL=http://hadoop-senior:11000/oozie/
-
-
[root@hadoop-senior oozie-
4.1.
0-cdh5.
13.0]
# bin/oozie job -config /opt/cdh5.13.0/oozie-4.1.0-cdh5.13.0/oozie-apps/shell-hive-select/job.properties -run
⑥ 查看

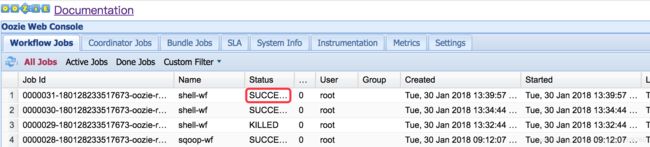
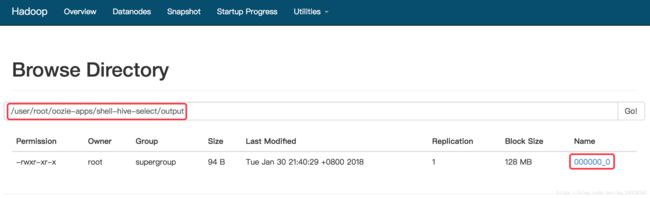

12. Oozie Coordinator调度讲解及系统时区配置与定时触发两种配置方式


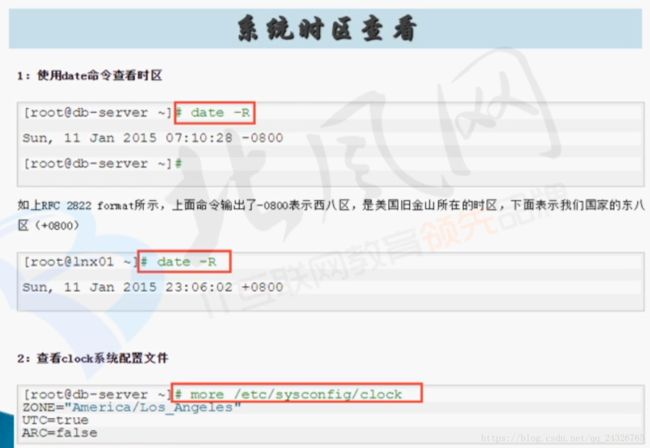
( -代表西,+代表东;为什么是4位?两位是时,两位是分 )
修改时区:
查看时区文件:



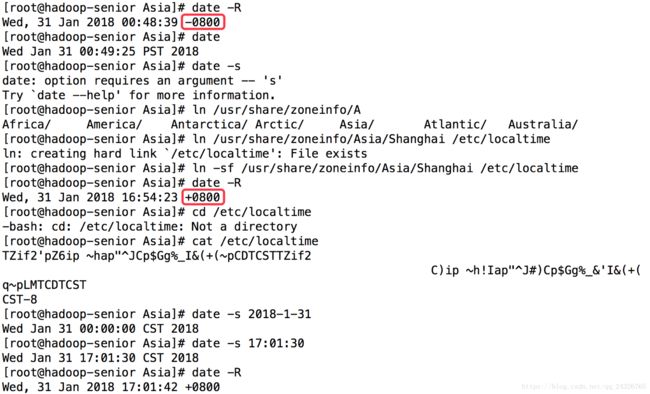
修改oozie时区:

查看oozie使用的时区:
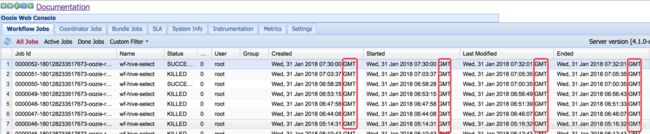
修改oozie运行时的时区:
查看默认的时区
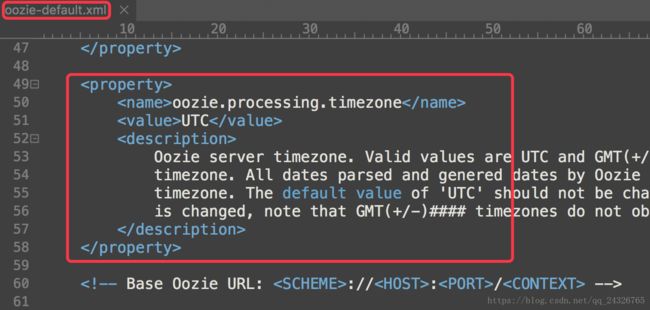
在oozie-site.xml中设置
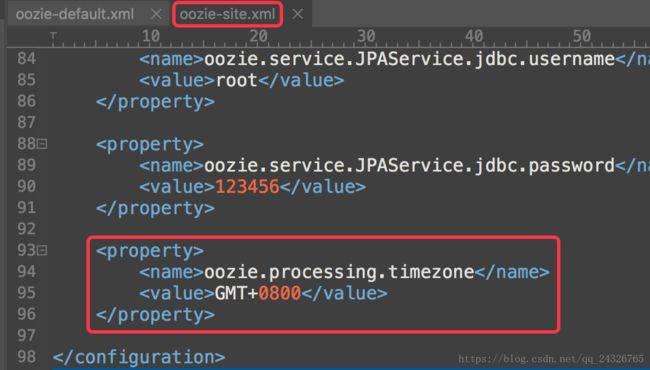
修改oozie控制台显示的时区:
方法一:
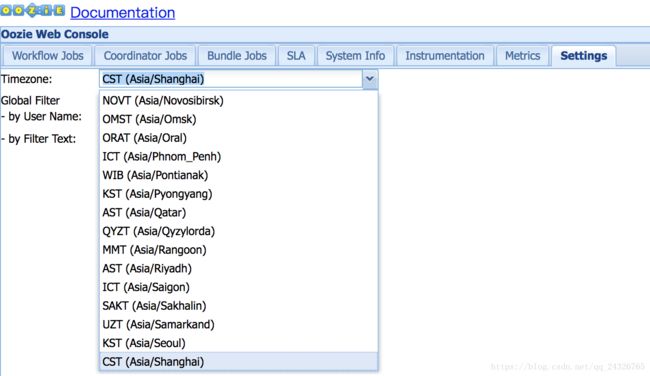
方法二:

(改完之后不用重启oozie服务,但是浏览器必须要清楚缓存)


清除oozie缓存:
异常:oozie控制台不能使用

解决:ExtJS library出现异常,重新prepare war包
[root@hadoop-senior oozie-4.1.0-cdh5.13.0]# bin/oozie-setup.sh prepare-war
13. Oozie Coordinator配置定时触发案例演示
① 拷贝样本案例
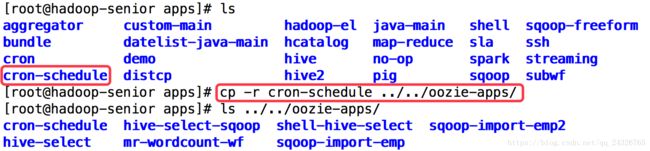

② 修改job.properties
修改前:
-
nameNode=hdfs://localhost:8020
-
jobTracker=localhost:8021
-
queueName=default
-
examplesRoot=examples
-
-
oozie.coord.application.path=
${nameNode}/user/
${user.name}/
${examplesRoot}/apps/cron-schedule
-
start=2010-01-01T00:00Z
-
end=2010-01-01T01:00Z
-
workflowAppUri=
${nameNode}/user/
${user.name}/
${examplesRoot}/apps/cron-schedule
修改后:
-
nameNode=hdfs:
//hadoop-senior:8020
-
jobTracker=hadoop-senior:
8032
-
queueName=
default
-
oozieAppsRoot=user/root/oozie-apps
-
oozieDatasRoot=user/root/oozie/datas
-
// 调度文件
-
oozie.coord.application.path=$
{nameNode}/$
{oozieAppsRoot}/cron-schedule
-
// 任务开始和结束的时间
-
start=
2018-
01-
31T21:
25+
0800
-
end=
2018-
01-
31T21:
28+
0800
-
// 工作流文件
-
workflowAppUri=$
{nameNode}/$
{oozieAppsRoot}/cron-schedule
③ 修改workflow.xml
不做任务,只是测试任务调度
-
// 根据官网查看最新版本
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="no-op-wf">
-
<start to="end"/>
-
<end name="end"/>
-
workflow-app>
④ 修改coordinator.xml
修改前:
-
<coordinator-app name="cron-coord" frequency="0/10 * * * *" start="${start}" end="${end}" timezone="UTC"
-
xmlns=
"uri:oozie:coordinator:0.2">
-
<action>
-
<workflow>
-
<app-path>${workflowAppUri}
app-path>
-
<configuration>
-
<property>
-
<name>jobTracker
name>
-
<value>${jobTracker}
value>
-
property>
-
<property>
-
<name>nameNode
name>
-
<value>${nameNode}
value>
-
property>
-
<property>
-
<name>queueName
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
workflow>
-
action>
-
coordinator-app>
修改后:
-
<coordinator-app name="cron-coord" frequency="${coord:minutes(1)}"
-
start=
"${start}"
end=
"${end}"
timezone=
"GMT+0800"
-
xmlns=
"uri:oozie:coordinator:0.4">
-
<action>
-
<workflow>
-
<app-path>${workflowAppUri}
app-path>
-
<configuration>
-
<property>
-
<name>jobTracker
name>
-
<value>${jobTracker}
value>
-
property>
-
<property>
-
<name>nameNode
name>
-
<value>${nameNode}
value>
-
property>
-
<property>
-
<name>queueName
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
workflow>
-
action>
-
coordinator-app>
版本:

frequency(频率):
设置时间的两种表达方式
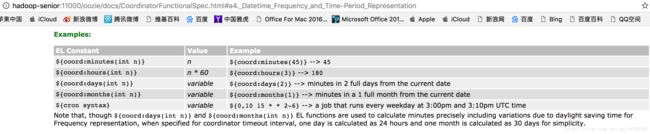
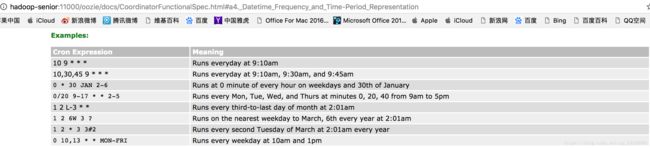
⑤ 查看

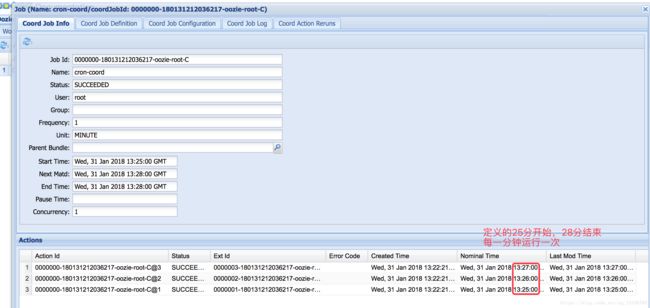
因为没有执行mapreduce,所以yarn上没有。
可能出现的异常:

设置的时间频率为每分钟执行一次低于oozie默认的最小时间间隔,需要修改配置文件。

重启oozie服务。
14. Oozie Coordinator配置调度MapReduce WordCount程序
① 拷贝样本案例
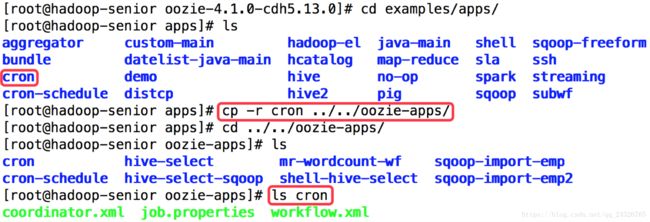
② 编写job.properties
-
nameNode=hdfs:
//hadoop-senior:
8020
-
jobTracker=hadoop-senior:
8032
-
queueName=default
-
oozieAppsRoot=user/root/oozie-apps
-
oozieDatasRoot=user/root/oozie/datas
-
-
oozie.coord.application.path=${nameNode}/${oozieAppsRoot}/cron
-
start=
2018-
02-
01T11:
39+080
0
-
end=
2018-
02-
01T11:
49+080
0
-
workflowAppUri=${nameNode}/${oozieAppsRoot}/cron/
-
inputDir=mr-wordcount-wf/input
-
outputDir=mr-wordcount-wf/output
③ 编写workflow.xml
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="mr-wordcount-wf">
-
<start to="mr-node-wordcount"/>
-
<action name="mr-node-wordcount">
-
<map-reduce>
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<prepare>
-
<delete path="${nameNode}/${oozieAppsRoot}/${outputDir}"/>
-
prepare>
-
<configuration>
-
<property>
-
<name>mapred.mapper.new-api
name>
-
<value>true
value>
-
property>
-
<property>
-
<name>mapred.reducer.new-api
name>
-
<value>true
value>
-
property>
-
<property>
-
<name>mapreduce.job.queuename
name>
-
<value>${queueName}
value>
-
property>
-
<property>
-
<name>mapreduce.job.map.class
name>
-
<value>com.zhuyu.mapreduce.WordCount$WordCountMapper
value>
-
property>
-
<property>
-
<name>mapreduce.job.reduce.class
name>
-
<value>com.zhuyu.mapreduce.WordCount$WordCountReducer
value>
-
property>
-
<property>
-
<name>mapreduce.map.output.key.class
name>
-
<value>org.apache.hadoop.io.Text
value>
-
property>
-
<property>
-
<name>mapreduce.map.output.value.class
name>
-
<value>org.apache.hadoop.io.IntWritable
value>
-
property>
-
<property>
-
<name>mapreduce.job.output.key.class
name>
-
<value>org.apache.hadoop.io.Text;
value>
-
property>
-
<property>
-
<name>mapreduce.job.output.value.class
name>
-
<value>org.apache.hadoop.io.IntWritable
value>
-
property>
-
<property>
-
<name>mapreduce.input.fileinputformat.inputdir
name>
-
<value>${nameNode}/${oozieDatasRoot}/${inputDir}
value>
-
property>
-
<property>
-
<name>mapreduce.output.fileoutputformat.outputdir
name>
-
<value>${nameNode}/${oozieAppsRoot}/${outputDir}
value>
-
property>
-
-
configuration>
-
map-reduce>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
<kill name="fail">
-
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
④ 编写coordinator.xml
-
<coordinator-app name="cron-coord-mr" frequency="0/2 * * * *"
-
start=
"${start}"
end=
"${end}"
timezone=
"GMT+0800"
-
xmlns=
"uri:oozie:coordinator:0.4">
-
<action>
-
<workflow>
-
<app-path>${workflowAppUri}
app-path>
-
<configuration>
-
<property>
-
<name>jobTracker
name>
-
<value>${jobTracker}
value>
-
property>
-
<property>
-
<name>nameNode
name>
-
<value>${nameNode}
value>
-
property>
-
<property>
-
<name>queueName
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
workflow>
-
action>
-
coordinator-app>
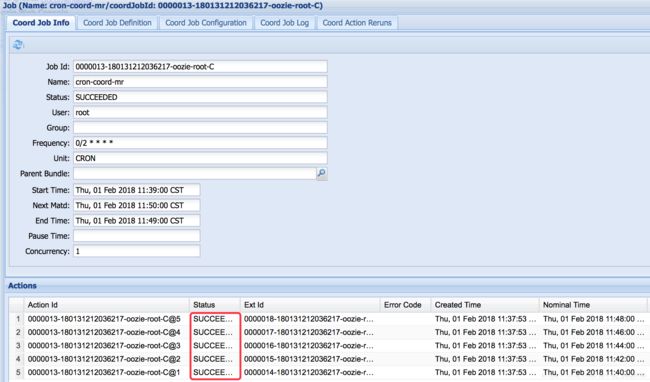
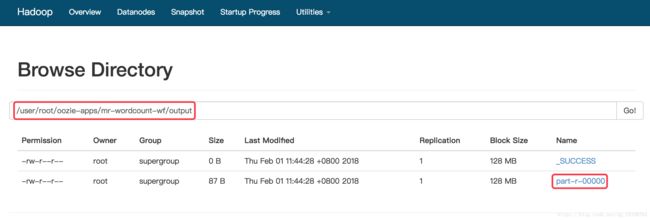
⑤ 查看


(可在oozie url的setting中设置)
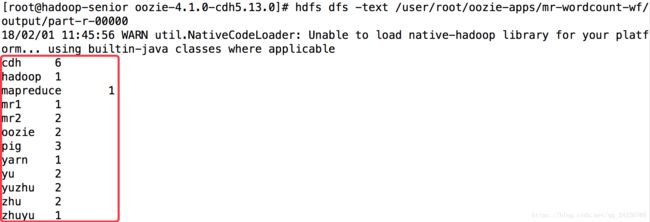
15. Oozie企业使用案例(Hive Action、Sqoop Actoion及定时调度)
使用hive统计emp表各部门的人数,将结果写到hdfs,再使用sqoop将结果写入mysql。
① 将hive-site.xml放到hive-select-sqoop下,将mysql驱动放到lib下
② 编写job.properties
③ 编写workflow.xml
-
<workflow-app xmlns="uri:oozie:workflow:0.5" name="wf-hive-select">
-
<start to="hive-node"/>
-
<action name="hive-node">
-
<hive xmlns="uri:oozie:hive-action:0.2">
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<prepare>
-
<delete path="${nameNode}/${oozieAppsRoot}/${outputDir}"/>
-
prepare>
-
<job-xml>${nameNode}/${oozieAppsRoot}/hive-select/hive-site.xml
job-xml>
-
<configuration>
-
<property>
-
<name>mapred.job.queue.name
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
<script>
select-emp.sql
script>
-
<param>OUTPUT=${nameNode}/${oozieAppsRoot}/${outputDir}
param>
-
hive>
-
<ok to="sqoop-node"/>
-
<error to="fail"/>
-
action>
-
<action name="sqoop-node">
-
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
-
<job-tracker>${jobTracker}
job-tracker>
-
<name-node>${nameNode}
name-node>
-
<configuration>
-
<property>
-
<name>mapreduce.job.queuename
name>
-
<value>${queueName}
value>
-
property>
-
configuration>
-
// 测试一下sqoop命令再执行oozie
-
<command>export --connect jdbc:mysql://hadoop-senior:3306/test --username root --password 123456 --table emp_dept_count --export-dir ${OUTPUT} --fields-terminated-by "," --num-mappers 1
command>
-
sqoop>
-
<ok to="end"/>
-
<error to="fail"/>
-
action>
-
<kill name="fail">
-
<message>Hive failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
message>
-
kill>
-
<end name="end"/>
-
workflow-app>
④ 编写hive脚本
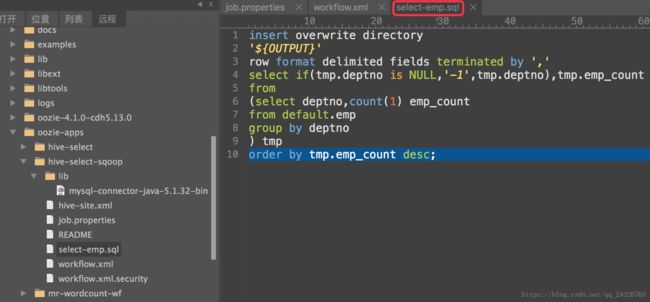
-
insert overwrite
directory
-
'${OUTPUT}'
-
row
format
delimited
fields
terminated
by
',' // 任何分隔符皆可,但是在导出数据的时候要设置
--fields-terminated-by
-
select
if(tmp.deptno
is
NULL,
'-1',tmp.deptno),tmp.emp_count
-
from
-
(
select deptno,
count(
1) emp_count
-
from default.emp
-
group
by deptno
-
) tmp
-
order
by tmp.emp_count
desc;