吴恩达-DeepLearning.ai-05 序列模型(一)
吴恩达-DeepLearning.ai-05 序列模型
循环序列模型
1、为什么选择序列模型?
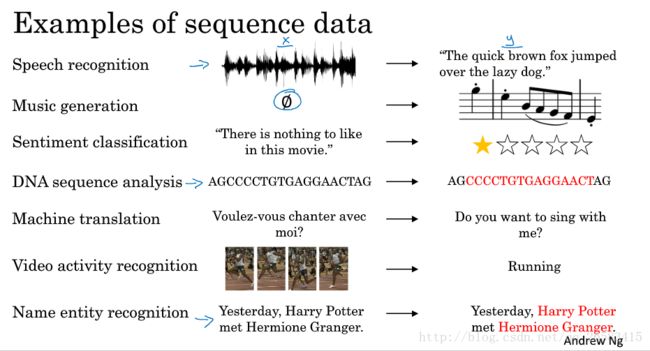
举了几个例子:语音识别、音乐生成、情感分析、DNA序列分析、机器翻译、视频动作识别、命名实体识别等
2、数学符号
文本数据的表示:命名实体识别中,要识别的内容标签为1,其他为0,。同时对句子中的词进行数学符号表示(one-hot,word2vec,glove等)
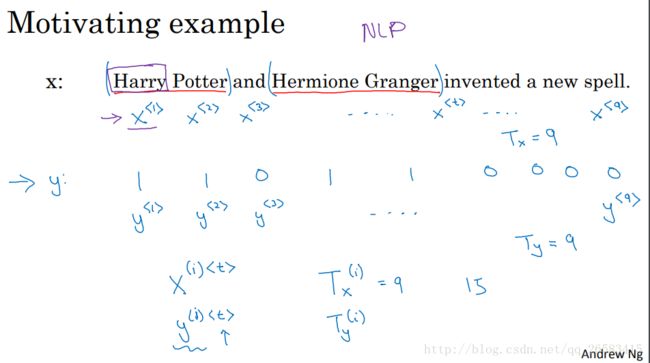
one-hot词向量表示:
首先有一个词袋可以对句子中的词进行编码(词袋越大越好一般3-5万),然后就可以使用one-hot对句子中的词进行one-hot编码,把文本表示为数值形式。

3、循环神经网络模型
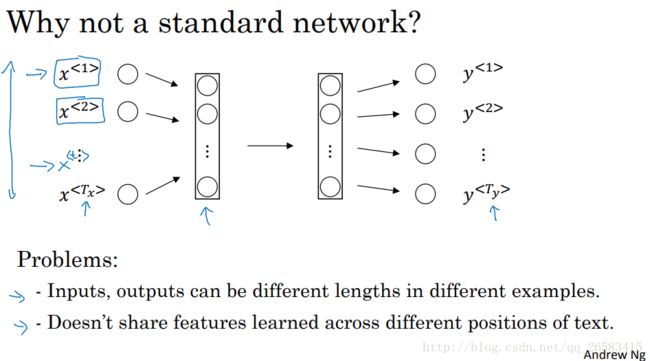
为什么用一个标准的神经网络效果不好?
1、在不同的例子中输入和输出具有不同的长度,即使通过填充将句子表示为相同的长度,看起来也不太好。
2、不能共享从文本上面不同位置学习到的特征,既在文本的上个位置学到的特征希望在下一个位置可以有信息保留(类似于CNN权值共享),可以减少模型参数。
什么是循环神经网络?

首先把第一个单词x(1)送入隐层中得到第一个预测结果y'(1),当把第二个单词x(2)送入隐藏层得到y'(2),不仅用了x(2)的数据信息,还利用了从第一个时间步骤中得到的a(1),然后重复到y'(Ty)。对于初始化参数a(0)一般为0向量。
循环神经网络是从左到右扫描数据,同时每个时间步骤上的输入参数也是共享的(W_ax),水平轴上的参数也是共享的(W_aa),每个时间步骤上的输出参数也是共享的(W_ya)表示。
缺点:只使用了当前词之前的信息进行预测,没有考虑后面词的影响,为了来解决提出了双向循环神经网络(BRNN)。
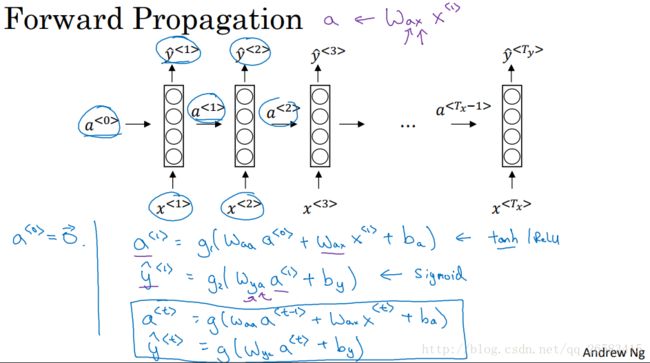
需要迭代计算的两个变量a(i)、y(i)的推导公式。
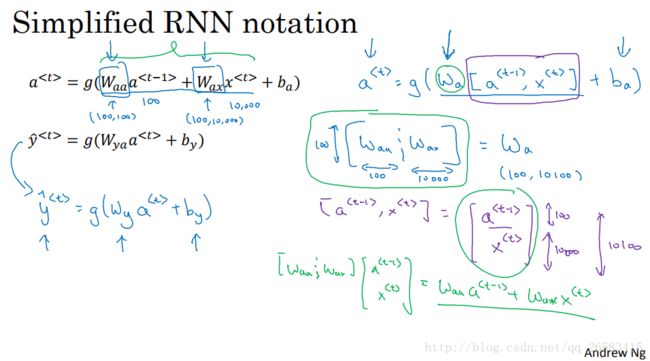
4、循环神经网络中的反向传播(Backpropagation through time,TTBP)
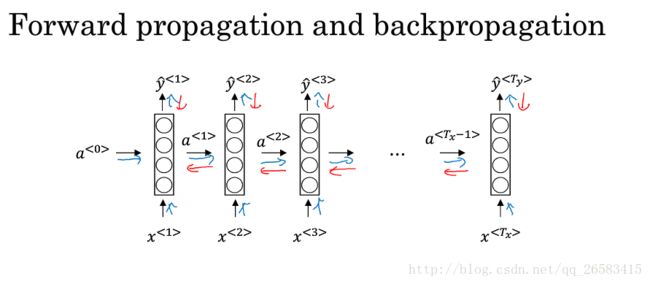
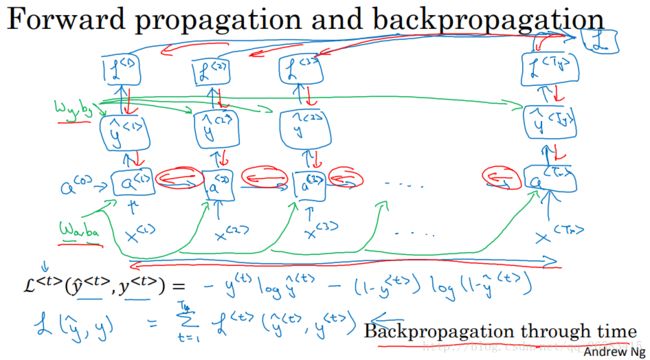
讲述了TTBP是怎样工作的,需要分别计算每个单独的损失,然后计算损失之和,再使用反向传播分别优化每个单独的部分。
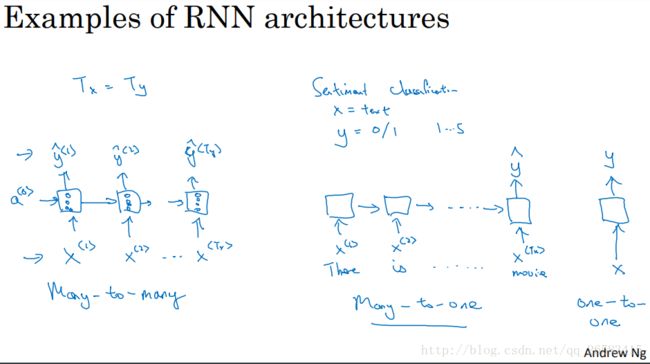
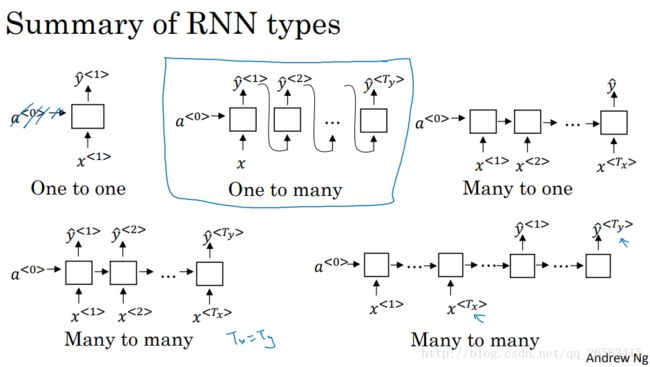
5、不同类型的循环神经网络
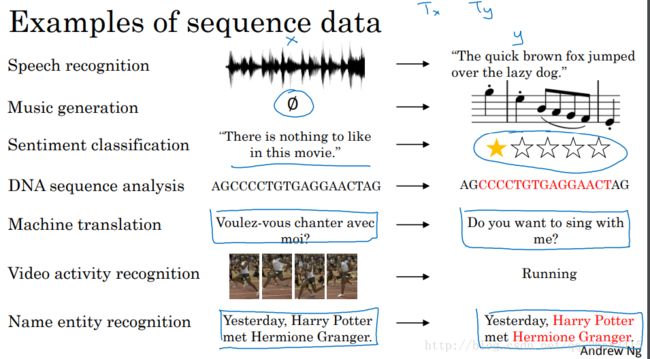
根据前面的不同例子可以分别用不同类型的模型取解决:
语音识别:many-to-many
音乐生成:ont-to-many
情感分析:many-to-one
DNA序列分析:many-to-many
机器翻译:many-to-many
视频动作识别:many-to-one
命名实体识别:many-to-many
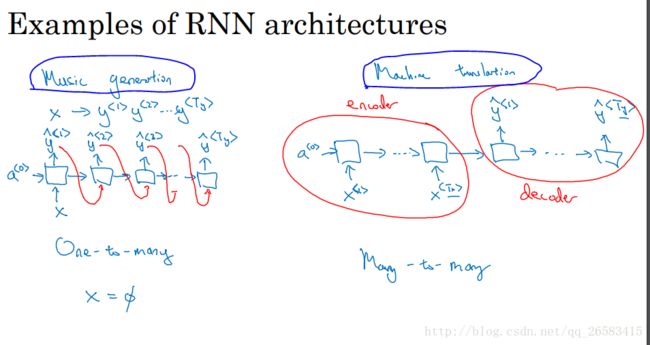
6、语言模型序列生成
什么是语言模型?
计算出不同句话的概率,对于给定的一段文本序列,语言模型需要判断各个单词出现的概率大小。
怎样建立一个语言模型?
预料——词袋——词向量(未知词表示为UNK)——建立模型(如:RNN)

RNN模型的语言模型建立
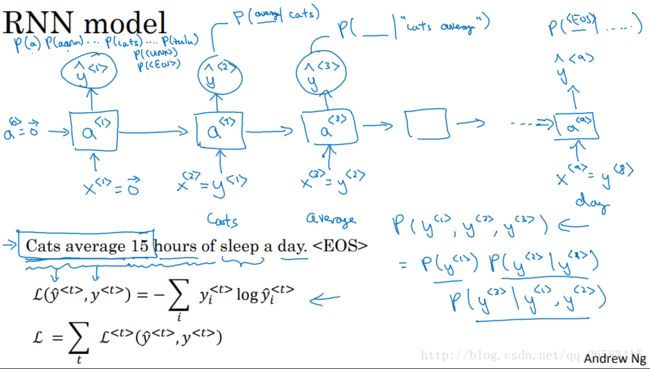
首先给定输入x(1)=0向量,a(0)=0向量,通过然后输出层用softmax进行预测词典中词出现在这里的概率作为第一个输出y'(1)(y'(1)的输出是softmax的结果,而不管是哪个词),接下来第二步我们设置x(2)=y(1)(表示直接告诉他第一个正确的此时cats),然后往上传输同样经过softmax得到第二个输出y'(2),这样持续传输知道句子结尾。
在RNN中每一步都会考虑前面得到的词,计算出下一个词的概率(从左到右每次与此一个词)。
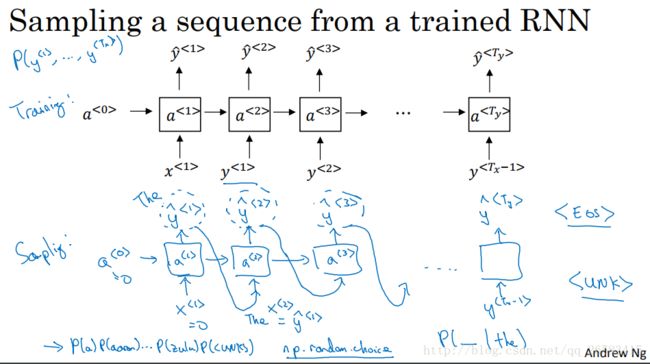
7、从模型中进行采样
在训练完一个模型之后,想要知道模型到底学到了什么?非正式的方法是进行一次新序列的采样。
一个序列模型模拟了任意特定单词序列的概率,我们要做的就是对这个单词序列进行采样,生成一个新的单词序列。
采样:
1、对你想要模型生成的第一个单词进行采样(既对第一个softmax的输出进行随机采样)。
2、将刚采样得到的结果作为第二个的输入,从复上面的采样方法,得到第二个的输出。
3、重复上面的步骤直到最后,这样就得到了一串字符表示的句子(基于词汇的RNN模型)。
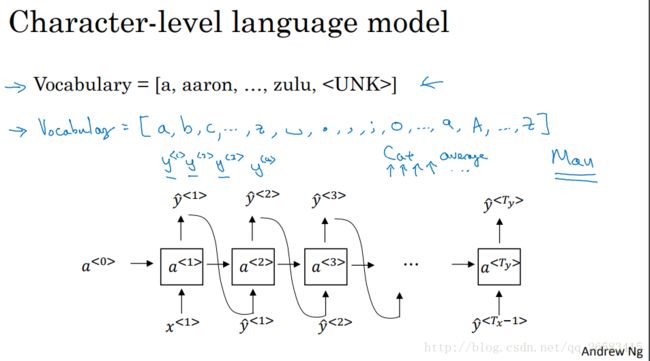
基于词汇的语言模型:单词为最小变量。
基于字符的语言模型:字母为最小变量。(计算量大,数据量大,目前效果不好,以后可能会好)
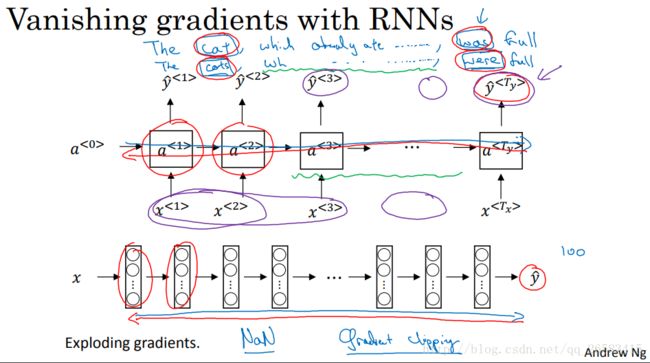
8、RNN神经网络的梯度消失和梯度爆炸
9、GRU单元(门控循环单元)
通过改变RNN的隐藏层,使其可以更好地捕捉深层连接(长范围的依赖),并改善了梯度消失问题。
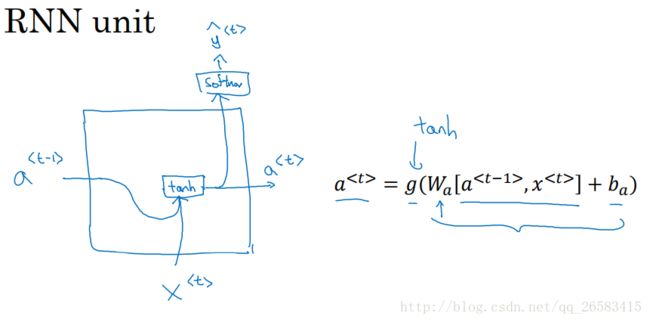
一个RNN单元的内部结构,基本表示了整个单元的运算流程。
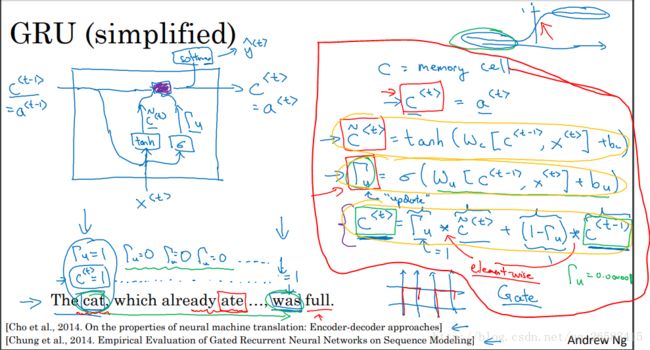
当从左到右读取文本时,GRU将会有一个新变量c(记忆细胞,提供了记忆能力,例如:对下面句子cat和was单数和复数的判断,因为存储了t时刻的信息),这里的c(t)=a(t)(LSTM中是不等的),用c'(t)替代表示c(t),公式如下图。GRU重要的内容:有一个门(值域为[0,1]),公式如下图。重要的就是这两个公式用c'(t)来表示c(t)的更新公式,同时用门来决定是否进行更新。用cat和was举了一个例子,当第一次见到cat时发现是一个新的信息所以门打开(假设为1),当后面遇到was时发现这就是单数的所以前面cat的信息没有用了,所以可以忘记这个信息了门再打开进行更新。从c(t)的真正更新公式可以看到当门的值为0是表示不会更新用的是就得信息,当为1是表示可以更新用的是当前计算得到的c'(t)值作为更新值。对于下面的英文短句来说在cat时门为1没到was之前门都是0表示不要更新,知道was时验证了单数的信息门又变为1更新为当前信息。
GRU优点:通过门决定了信息传递的记忆性。同时门的值一般很小(0.00001),所以缓解了梯度消失的问题,可以是模型运行在非常大的依赖词上

10、长短时记忆网络(LSTM,long short term memory)
在LSTM中a(t)不在和c(t)相等。LSTM对于c(t)的更新反映了LSTM名称的由来,你通过两个门一个记忆门一个遗忘门可以选择记忆或者遗忘。

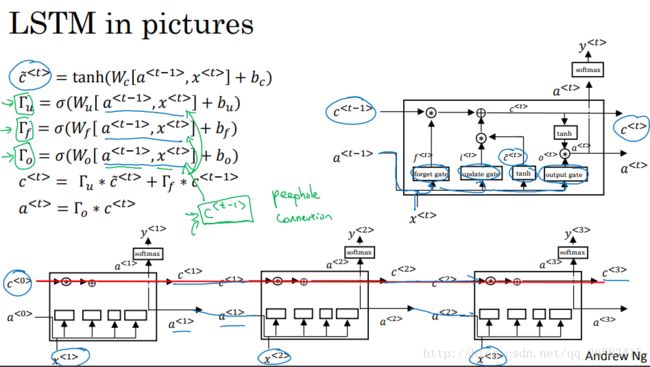
GRU:模型简单,方便扩展,计算速度快,更适合大规模问题。
LSTM:模型灵活多变,计算速度稍慢。
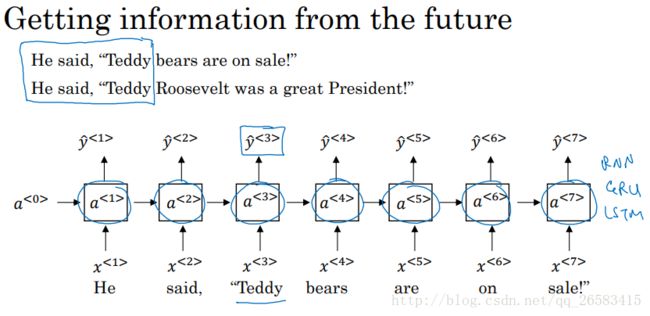
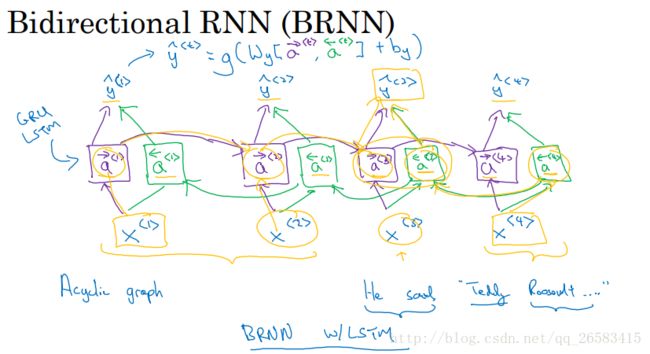
11、双向循环神经网络(Bidirectional RNN)
BRNN:在序列的某点不仅可以获取之前的信息而且可以获取未来的信息。
特点:同时考虑从左到右以前的信息,而且考虑从右到左未来的信息,可以对整个句子的任何位置进行预测,但是模型需要一段完整的数据序列(对于语音识别来说情况复杂,不是很适合),但是大多数的NLP任务都可以得到完整的数据序列,所以BILSTM,是NLP的首选。
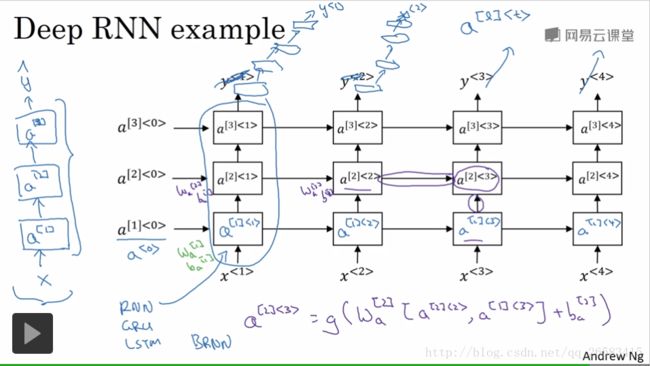
12、深度循环神经网络