大数据学习Hadoop之HDFS详解一
一、Hadoop的之HDFS架构:
1、基础概念:
1.1、架构组成:主要有以下四个部分组成:
HDFS Client:客户端
NameNode:名称节点
DataNode:数据节点
Secondary NameNode:第二名称节点
1.1.2、block(数据块)
大小:64M
128M
通过参数hdfs-site.xml dfs.blocksize进行修改
比如有一个文件130兆,会根据块大小128,切分为两个块
128兆和 2兆,两个块。
1.1.3、副本
默认是每个数据块有三个副本,最大的副本数为512,最小为1.
通过修改参数hdfs-site.xml dfs.replication
通常用来考察存储的大小,要考虑副本数是1和3的情况,分多种情况来回答。
2、HDFS架构设计:
2.1、架构图:
设计为主从架构
NameNode 一台
DateNode: 多台
不同的datanode处于不同的机架上,不同的网段。
自己的机架:需要机架,要配置机架感知功能
云服务器:不需要机架,不需要配置机架感知功能

2.2、进程组成
NameNode : 文件系统的命名空间 数据存储在内存上
作用:1、文件名称
2、文件目录结构
3、文件的属性(权限 创建时间 副本数)
4、文件对应哪些数据块--->数据块对应分布在哪些DN节点上。
DateNode:存储数据块+数据块的校验和NN通信 数据存储在磁盘上
1、每隔3秒发送1次心跳,向NameNode报告自己是否存在。
2、每隔10次心跳发送一次blockReport,向NameNode报告自己的块情况。
SecondaryNameNode: 存储:命名空间镜像文件fsimage+ editlog编辑日志 当配置有热备时,就不存在了。
作用:定期合并fsimage+ editlog为新的fsimage推送给NN,称为检查点checkpoint;
参数: dfs.namenode.checkpoint.period 3600s
一般企业中部署的有热备:NN active NN standby
3、副本放置策略:
第一副本策略:如何是datanode,优先放置在和上传数据相同的datanode上;如果是集群外提交,则随机放置在业务不太繁忙的节点上。
第二副本策略:放置在与第一个副本不同的机架的节点上。
第三副本策略:放置在与第二个副本相同机架的不同节点上。
4、HDFS的文件的读:
4.1、查看hdfs文件系统:
hdfs dfs -ls /

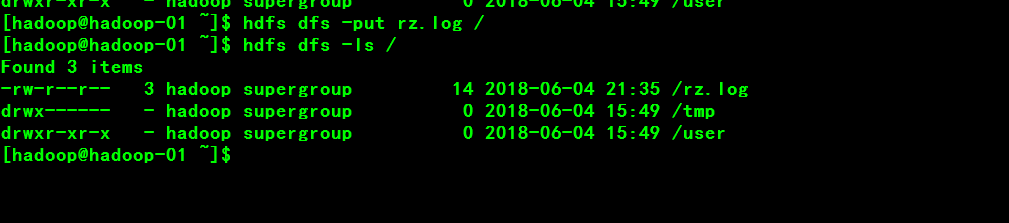
4.2、上传文件到hdfs文件系统
hdfs dfs -put rz.log /
hdfs dfs -ls /
4.3、查看文件内容
hdfs dfs -cat /rz.log

从上面的操作来看,读操作对于client端来说,是透明的操作,是连续的数据流。
4.4、文件的读流程图:

1.Client调用FileSystem.create(filePath)方法,去与Namenode进行rpc通信,Namenode会check该路径的文件是否存在以及有没有权限创建该文件,假如ok,就创建一个新文件,但是并不关联任何block,返回一个FSDataOutputStream对象;(假如not ok,就返回错误信息,所以写代码要try-catch)
2.Client调用FSDataOutputStream对象的write()方法,会将第一个块写入第一个Datanode,第一个Datanode写完传给第二个节点,第二个写完传给第三节点,当第三个节点写完返回一个ackpacket给第二个节点,第二个返回一个ackpacket给第一个节点,第一个节点返回ackpacket给FSDataOutputStream对象,意思标识第一个块写完,副本数为3;然后剩余的块依次这样写;
(当然写操作对于Client端也是透明的)3.当向文件写入数据完成后,Client调用FSDataOutputStream.close()方法,关闭输出流,flush缓存区的数据包;
4.再调用FileSystem.complete()方法,告诉Namenode节点写入成功。