storm 分布式的实时计算系统
Storm介绍
更多干货
-
分布式实战(干货)
-
spring cloud 实战(干货)
-
mybatis 实战(干货)
-
spring boot 实战(干货)
-
React 入门实战(干货)
-
构建中小型互联网企业架构(干货)
-
python 学习持续更新
-
ElasticSearch 笔记
-
kafka storm 实战 (干货)
-
scala 学习持续更新
-
RPC
-
深度学习
-
GO 语言 持续更新
Storm 大数据实事计算系统,是Twitter开源的一个分布式的实时计算系统
全量数据处理使用的大多是鼎鼎大名的hadoop、hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用,但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界的共识。而s4,storm,puma,spark等则是实时计算系统。
优点
- 简单编程模型。类似于MapReduce降低了并行批处理的复杂性,Strom降低了实时处理的复杂性。
- 服务化,一个服务框架支持热部署,即时上线或下线
- 分布式 可横向拓展,现在的项目不带个分布式特性都不好意思开源
- 高可靠性
- 编程模型简单
- 高效实时
- 可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责消息的重试。Storm创新性提出的ack消息追踪框架和复杂的事务性处理,能够满足很多级别的数据处理需求。不过,越高的数据处理需求,性能下降越严重。
- 快速。系统的设计保证了消息能得到快速的处理,zeroMQ作为其底层消息队列
- 本地模式。storm有一个“本地模式”,可以在处理过程中完全模拟storm集群。这让你可以快速进行开发
- 多语言。 实际上,Storm的多语言更像是临时添加上去似的。因为,你的提交部分还是要使用Java实现。
使用场景:数据的实时,持续计算,分布式RPC等。
发展
- 有50个大大小小的公司在使用Storm,相信更多的不留名的公司也在使用。这些公司中不乏淘宝,百度,Twitter,Groupon,雅虎等重量级公司。
- 从开源时候的0.5.0版本,到现在的0.8.0+,和即将到来的0.9.0+。先后添加了以下重大的新特性:
- 使用kryo作为Tuple序列化的框架(0.6.0)
- 添加了Transactional topologies(事务性拓扑)的支持(0.7.0)
- 添加了Trident的支持(0.8.0)
- 引入netty作为底层消息机制(0.9.0)
当前
Storm被广泛应用于实时分析,在线机器学习,持续计算、分布式远程调用等领域。来看一些实际的应用:
- 一淘-实时分析系统pora:实时分析用户的属性,并反馈给搜索引擎。最初,用户属性分析是通过每天在云梯上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
- 携程-网站性能监控:实时分析系统监控携程网的网站性能。利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。如果,业务场景中需要低延迟的响应,希望在秒级或者毫秒级完成分析、并得到响应,而且希望能够随着数据量的增大而拓展。那就可以考虑下,使用Storm了。
- 试想下,如果,一个游戏新版本上线,有一个实时分析系统,收集游戏中的数据,运营或者开发者可以在上线后几秒钟得到持续不断更新的游戏监控报告和分析结果,然后马上针对游戏的参数和平衡性进行调整。这样就能够大大缩短游戏迭代周期,加强游戏的生命力(实际上,zynga就是这么干的!虽然使用的不是Storm……Zynga研发之道探秘:用数据说话)。
- 除了低延迟,Storm的Topology灵活的编程方式和分布式协调也会给我们带来方便。用户属性分析的项目,需要处理大量的数据。使用传统的MapReduce处理是个不错的选择。但是,处理过程中有个步骤需要根据分析结果,采集网页上的数据进行下一步的处理。这对于MapReduce来说就不太适用了。但是,Storm的Topology就能完美解决这个问题。基于这个问题,我们可以画出这样一个Storm的Topology的处理图。
- 个性化推荐与应用:网页嵌入广告(个性化推销,根据用户购买及其搜索)
- 视频推荐系统:优酷登录后分析以往的观看记录来进行推荐。
- 推荐系统介绍:统计分析用户以往的观看记录,将统计后的结果作为推荐的依据,然后将视频个性化的推荐给用户,提高用户观看视频的可能性。
- 数据过滤,对用户发送的短信、微博等敏感词实时的过滤,对包含敏感词的信息进行保存,并监控发送消息的主体。
Storm概念
Spout(消息源)
- Spout是Storm里面特有的名词, Stream的源头. 通常是从外部数据源读取tuples, 并emit到topology.
- Spout可以同时emit多个tuple stream, 通过OutputFieldsDeclarer中的declareStream method来定义
- Spout需要实现IRichSpout接口, 最重要的方法是nextTuple, storm会不断调用该接口从spout中取数据
- 同时需要注意, Spout分为reliable or unreliable两种, 对于reliable, 还支持ack和fail方法, 具体参考"Reliability”
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike",
"jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
Bolt(消息处理者)
- Bolt支持多个输入流和emit多个输出流, 输出流和spout一样, 通过OutputFieldsDeclarer中的declareStream method来定义; 对于输入流, 如果想subscribe上层节点的多个输出streaming, 需要显式的通过stream_id去订阅, 如果不明确指定stream_id, 默认会订阅default stream.
public static class ExclamationBolt implements IRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Stream grouping(数据的分发方式)
Topology(拓扑)
- 可以理解为类似MapReduce job
- 根本区别, MR job执行完就结束, 而Topology会一直存在. 因为MR流动的是代码, 而Storm流动的数据.
- 所以Storm不可能替代MR, 因为对于海量数据, 数据的流动是不合理的
- 另一个区别, 我自己的想法, Topology对工作流有更好的支持, 而MR job往往只能完成一个map/reduce的过程, 而对于复杂的操作, 需要多个MR job才能完成.
- 而Topology的定义更加灵活, 可以简单的使用一个topology支持比较复杂的工作流场景
- Storm Topology是基于Thrift结构, 并且Nimbus是个Thrift server, 所以对于Topology可以用任何语言实现, 最终都是转化为Thrift结构
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new RandomSentenceSpout(), 5 );
builder.setBolt(2, new SplitSentence(), 8 ).shuffleGrouping(1);
builder.setBolt(3, new WordCount(), 12).fieldsGrouping(2, new Fields("word"));- Topology有一个spout, 两个bolt. setSpout和setBolt的参数都是一样, 分别为id(在Topology中的唯一标识); 处理逻辑(对于Spout就是数据产生function); 并发线程数(task数)
- 其中对于spout需要实现IRichSpout接口, 而bolt需要实现IRichBolt接口
- 比较特别的是, setBolt方法会返回一个InputDeclarer对象, 并且该对象是用来定义Bolt输入的, 比如上面.shuffleGrouping(1), 用1(spout)的输出流作为输入
Worker(工作进程)
Task(执行具体逻辑的任务)
Executor(执行Task的线程)
- 一个Topology可以包含一个或多个worker(并行的跑在不同的machine上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
- 一个worker可用包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集, 同时一个executor只能对应于一个component
- Task就是具体的处理逻辑对象, 一个executor线程可以执行一个或多个tasks
但一般默认每个executor只执行一个task, 所以我们往往认为task就是执行线程, 其实不然
task代表最大并发度, 一个component的task数是不会改变的, 但是一个componet的executer数目是会发生变化的
当task数大于executor数时, executor数代表实际并发数
Configuration(配置)
- 对于并发度的配置, 在storm里面可以在多个地方进行配置, 优先级如上面所示...
- worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大于machines的数目
- executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt("green-bolt", new GreenBolt(), 2)
- tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4) //set tasks number to 4
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);- 代码, 很清晰, 通过setBolt和setSpout一共定义2+2+6=10个executor threads.并且同setNumWorkers设置2个workers, 所以storm会平均在每个worker上run 5个executors
而对于green-bolt, 定义了4个tasks, 所以每个executor中有2个tasks
rebalancing动态的改变并发度
- Storm支持在不restart topology的情况下, 动态的改变(增减)worker processes的数目和executors的数目, 称为rebalancing.
- 通过Storm web UI, 或者通过storm rebalance命令
常用的类
BaseRichSpout (消息生产者)
BaseBasicBolt(消息处理者)
TopologyBuilder(拓扑的构建器)
Values(将数据存放的values,发送到下个组件)
Tuple
- (发送的数据被封装到Tuple,可以通tuple接收上个组件发送的消息)
- 命名的value序列, 可以理解成Key/value序列, 每个value可以是任何类型, 动态类型不需要事先声明.
- Tuple在传输中需要序列化和反序列化, storm集成了普通类型的序列化模块, 用户可以自定义特殊类型的序列化逻辑
Config(配置)
StormSubmitter / LocalCluster (拓扑提交器)
storm里面各个对象的示意图
计算拓补:Topology
- 一个实时计算应用程序的逻辑在storm里面被封装到topology对象里面, 我把它叫做计算拓补. Storm里面的topology相当于Hadoop里面的一个MapReduce Job, 它们的关键区别是:一个MapReduce Job最终总是会结束的, 然而一个storm的topoloy会一直运行 — 除非你显式的杀死它。 一个Topology是Spouts和Bolts组成的图状结构, 而链接Spouts和Bolts的则是Stream groupings。
消息源: Spout
- 消息源Spouts是storm里面一个topology里面的消息生产者。一般来说消息源会从一个外部源读取数据并且向topology里面发出消息: tuple。 消息源Spouts可以是可靠的也可以是不可靠的。一个可靠的消息源可以重新发射一个tuple如果这个tuple没有被storm成功的处理, 但是一个不可靠的消息源Spouts一旦发出一个tuple就把它彻底忘了 — 也就不可能再发了。
- 消息源Spouts可以发射多条消息流stream。要达到这样的效果, 使用OutFieldsDeclarer.declareStream来定义多个stream,然后使用SpoutOutputCollector来发射指定的sream。
消息处理者: Bolt
- 所有的消息处理逻辑被封装在bolts里面。Bolts可以做很多事情: 过滤, 聚合, 查询数据库等等。
- Bolts的主要方法是execute,它以一个tuple作为输入,Bolts使用OutputCollector来发射tuple, Bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知storm这个tuple被处理完成了。– 从而我们通知这个tuple的发射者Spouts。 一般的流程是:Bolts处理一个输入tuple, 发射0个或者多个tuple,然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack
Task:任务
- 每一个Spout和Bolt会被当作很多task在整个集群里面执行。默认情况下每一个task对应到一个线程(Executor),这个线程用来执行这个task,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。
配置Configuration
- storm里面有一堆参数可以配置来调整nimbus, supervisor以及正在运行的topology的行为, 一些配置是系统级别的, 一些配置是topology级别的。所有有默认值的配置的默认配置是配置在default.xml里面的。你可以通过定义个storm.xml在你的classpath厘米来覆盖这些默认配置。并且你也可以在代码里面设置一些topology相关的配置信息 – 使用StormSubmitter。当然,这些配置的优先级是: default.xml < storm.xml < TOPOLOGY-SPECIFIC配置。
消息流:Stream
- 消息流是storm里面的最关键的抽象。一个消息流是一个没有边界的tuple序列, 而这些tuples会被以一种分布式的方式并行地创建和处理。 对消息流的定义主要是对消息流里面的tuple的定义, 我们会给tuple里的每个字段一个名字。 并且不同tuple的对应字段的类型必须一样。 也就是说: 两个tuple的第一个字段的类型必须一样, 第二个字段的类型必须一样, 但是第一个字段和第二个字段可以有不同的类型。 在默认的情况下,tuple的字段类型可以是:integer, long, short, byte, string, double, float, boolean和byte array。 你还可以自定义类型 — 只要你实现对应的序列化器
消息分发策略:Stream groupings
- Shuffle Grouping:随机分组,随机派发stream里面的tuple,保证每个bolt接收到的tuple数目相同。
- Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts,而不同的userid则会被分配到不同的Bolts。
- All Grouping:广播发送,对于每一个tuple,所有的Bolts都会收到。
- Global Grouping: 全局分组,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果,有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping:直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
Storm 消息机制
首先, 所有tuple都有一个唯一标识msgId, 当tuple被emit的时候确定
_collector.emit(new Values("field1", "field2", 3) , msgId);
其次, 看看下面的ISpout接口, 除了获取tuple的nextTuple
还有ack和fail, 当Storm detect到tuple被fully processed, 会调用ack, 如果超时或detect fail, 则调用fail
此处需要注意的是, tuple只有在被产生的那个spout task上可以被ack或fail, 具体原因看后面的实现解释就理解了
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
最后, 在spout怎么实现的, 其实比较简单.
对于Spout queue, get message只是open而不是pop, 并且把tuple状态改为pending, 防止该tuple被多次发送.
一直等到该tuple被ack, 才真正的pop该tuple, 当然该tuple如果fail, 就重新把状态改回初始状态
这也解释, 为什么tuple只能在被emit的spout task被ack或fail, 因为只有这个task的queue里面有该tuple
前面一直没有说明的一个问题是, storm本身通过什么机制来判断tuple是否成功被fully processed?
要解决这个问题, 可以分为两个问题,
- 如何知道tuple tree的结构?
- 如何知道tuple tree上每个节点的运行情况, success或fail?
答案很简单, 你必须告诉它, 如何告诉它?
- 对于tuple tree的结构, 需要知道每个tuple由哪些tuple产生, 即tree节点间的link
- tree节点间的link称为anchoring. 当每次emit新tuple的时候, 必须显式的通过API建立anchoring
_collector.emit(tuple, new Values(word)); emit的第一个参数是tuple, 这就是用于建anchoring
当然你也可以直接调用unanchoring的emit版本, 如果不需要保证reliable的话, 这样效率会比较高
_collector.emit(new Values(word)); 同时前面说了, 可能一个tuple依赖于多个输入,
List anchors = new ArrayList();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
对于Multi-anchoring的情况会导致tuple tree变为tuple DGA, 当前storm的版本已经可以很好的支持DAG
对于tuple tree上每个节点的运行情况, 你需要在每个bolt的逻辑处理完后, 显式的调用OutputCollector的ack和fail来汇报
看下面的例子, 在execute函数的最后会调用
_collector.ack(tuple); 我比较迷惑, 为啥ack是OutputCollector的function, 而不是tuple的function?
而且就算ack也是应该对bolt的input进行ack, 为啥是output, 可能因为所有input都是其他bolt的output产生...这个设计的比较不合理
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
storm为了保证reliable, 必然是要牺牲效率的, 此处storm会在task memory里面去记录你汇报的tuple tree的结构和运行情况.
而只有当某tuple节点被ack或fail后才会被从内存中删除, 所以如果你总是不去ack或fail, 那么会导致task的out of memory
简单的版本, BasicBolt
上面的机制, 会给程序员造成负担, 尤其对于很多简单的case, 比如filter, 每次都要去显式的建立anchoring和ack…
所以storm提供简单的版本, 会自动的建立anchoring, 并在bolt执行完自动调用ack
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
记录级容错
首先来看一下什么叫做记录级容错?Storm允许用户在spout中发射一个新的源tuple时为其指定一个message id,这个message id可以是任意的object对象。多个源tuple可以公用一个message id, 表示这多个源tuple对用户来说是同一个消息单元。Storm中记录级容错的意思是说,storm会告知用户每一个消息单元是否在指定时间内被完全处理了。那什么叫做完全处理呢,就是该message id绑定的源tuple及由该源tuple后续生成的tuple经过了topology中每一个应该到达的bolt的处理。
举个例子。在图中,在spout由message 1绑定的tuple1和tuple2经过了bolt1和bolt2处理生成两个新的tuple,并流向了bolt3。当这个过程完全处理完时,称message 1被完全处理了
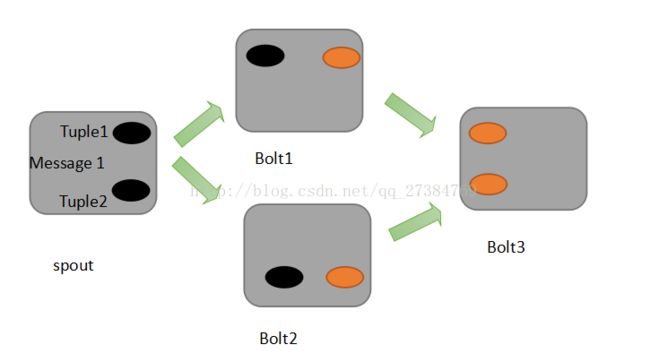
在storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是跟踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就 会告知spout该消息处理失败了,相反则会告知spout该消息处理成功了。在刚才的描述中,我们提到了 “记录tuple的处理路径”。采用一数学定理:异或。
- A xor A = 0
- A xor B.... Xor B xor A = 0, 其中每一个操作数出现且仅出现两次。
Storm中使用的巧妙方法就是基于这个定理。具体过程:在spout中系统会为用户指定message id生成一个对应的64位整数,作为一个root id. root id会传递给acker及后续的bolt作为该消息单元的唯一标识。同时无论是spout还是bolt每次新生成一个tuple的时候,都会赋予改tuple一个64位的整数的id。Spout发射完某个message id 对应的源tuple之后,会告知acker自己发射的root id 及生成的那些源tuple的id.
而bolt呢,每次接收到一个输入tuple处理完之后,也会告知acker自己处理的输入tuple的id及新生成的那些tuple的id。Acker只需要对这些id做一个简单的异或运算,就能判断出该root id对应的消息单元是否处理完成了。下面图示说明:
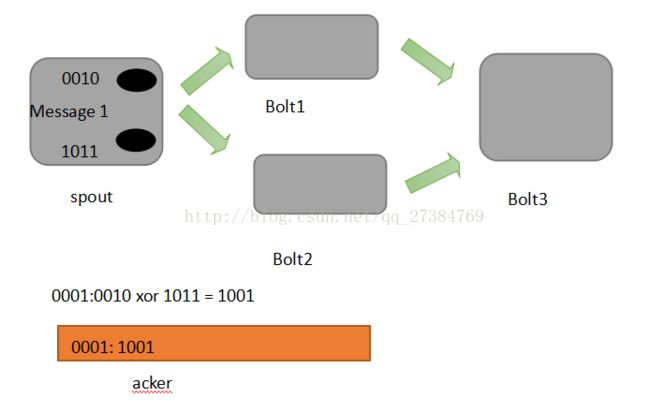
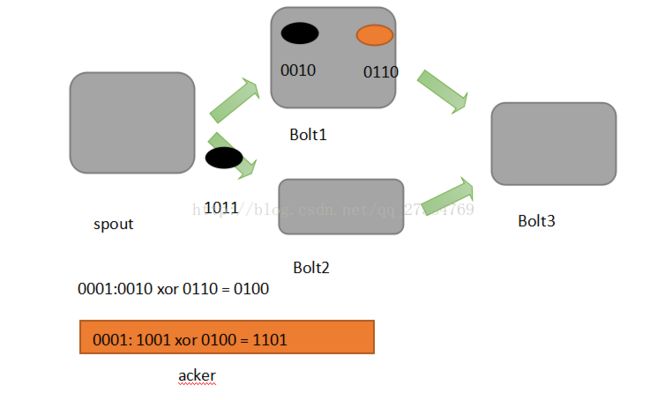
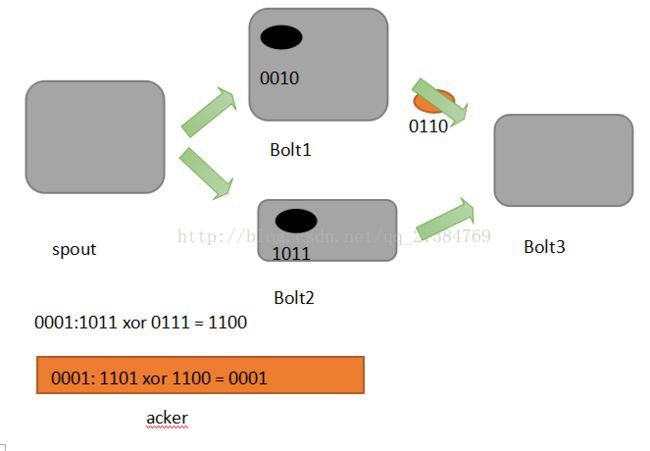
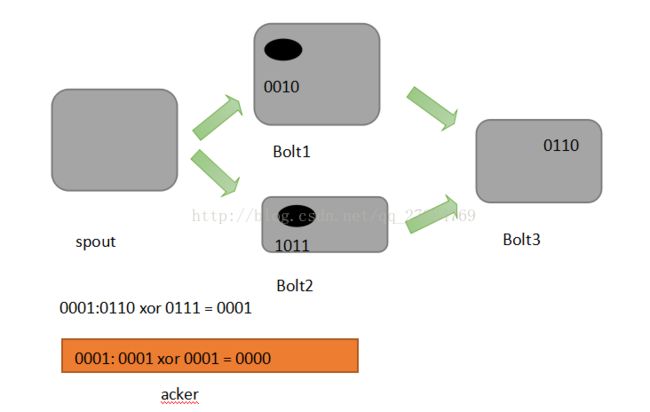
可能有些细心的同学会发现,容错过程存在一个可能出错的地方,那就是,如果生产的tuple id并不是完全各异,acker可能会在消息单元完全处理完成之前就错误的计算为0.这个错误在理论上的确是存在的,但是在实际中其概念极低,完全可以忽略。
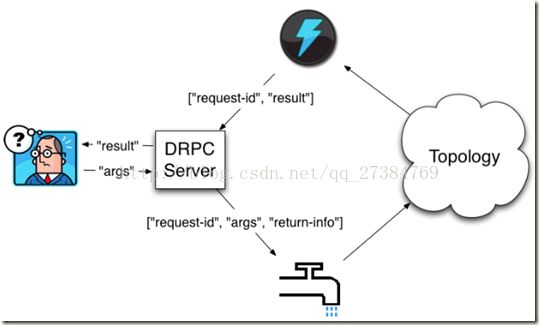
Storm DRPC实战
DRPC ,Distributed Remote Procedure Call
- RPC本身是个成熟和古老的概念, Storm里面引入DRPC主要是利用storm的实时计算能力来并行化CPU intensive的计算
- DRPC, 只是storm应用的一个场景, 并且storm提供相应的编程框架, 以方便程序员
- 提供DRPC server的实现, 并提供对DRPC场景经行封装的Topology
- 对于storm, Topology内部其实是没有任何区别的, 主要就是实现和封装Topology和DRPC Server之间交互的spout和bolt
具体交互过程如下图
public static class ExclaimBolt implements IBasicBolt {
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
}
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder
= new LinearDRPCTopologyBuilder("exclamation");
builder.addBolt(new ExclaimBolt(), 3);
// ...
}
使用LinearDRPCTopologyBuilder
- 首先, 使用builder创建topology的时候, topology name要等于function name(PRC call)
- 其次, 这里不需要指定spout, 因为已经做了封装, 会自动从DRPC server读取数据
- 再者, 所有bolt的输出的第一个field必须是request-id, 最后一般bolt的输出一定是(request-id, result)
- 最后, builder会自动将结果发给DRPC server
LinearDRPC例子
前面的例子, 无法说明为什么要使用storm来实现RPC, 那个操作直接在RPC server上就可以完成
当只有对并行计算和数据量有一定要求时, 才能体现出价值...
ReachTopology, 每个人发送的URL都会被所有follower收到, 所以要计算某URL的reach, 只需要如下几步,
找出所有发送该URL的tweeter, 取出他们的follower, 去重复, 计数
public class ReachTopology {
public static Map> TWEETERS_DB = new HashMap>() {
{
put("foo.com/blog/1", Arrays.asList("sally", "bob", "tim", "george", "nathan"));
put("engineering.twitter.com/blog/5", Arrays.asList("admam", "david", "sally", "nathan"));
}
};
public static Map> FOLLOWERS_DB = new HashMap>() {
{
put("sally", Arrays.asList("bob", "time", "alice", "adam", "jai"));
put("bob", Arrays.asList("admam", "david", "vivian", "nathan"));
}
};
public static class GetTweeters extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
Object id = tuple.getValue(0);
String url = tuple.getString(1);
List tweeters = TWEETERS_DB.get(url);
if (tweeters != null) {
for (String tweeter: tweeters) {
collector.emit(new Values(id, tweeter));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "tweeter"));
}
}
public static class GetFollowers extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
Object id = tuple.getValue(0);
String tweeter = tuple.getString(1);
List followers = FOLLOWERS_DB.get(url);
if (followers != null) {
for (String follower: followers) {
collector.emit(new Values(id, follower));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "follower"));
}
}
public static class PartialUniquer extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
Set _followers = new HashSet();
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_followers.add(tuple.getString(1));
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _followers.size()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "partial-count"));
}
}
public static class CountAggregator extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
int _count = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_count += tuple.getInteger(1);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "reach"));
}
}
public static LinearDRPCTopologyBuilder construct() {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 4);
builder.addBolt(new GetFollowers, 12).shuffleGrouping;
builder.addBolt(new PartialUniquer(), 6).filedsGrouping(new Fields("id","follower"));
builder.addBolt(new CountAggregator(), 3).filedsGrouping(new Fields("id"));
return builder;
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = construct();
Config conf = new Config();
if (args == null || args.length ==0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("reach-drpc",conf, builder.createLocalTopology(drpc));
String urlsToTry = new String[] { "foo.com/blog/1","engineering.twitter.com/blog/5"}
cluster.shutdown();
drpc.shutdown();
} else {
config.setNumberWorkers(6);
StormSubmitter.submitTopology(args[0], conf, builder.createRemoteTopology());
}
}
}
Storm 配置详解
- Storm.zookeeper.servers zookeeper服务器列表
- Storm.zookeeper.port zookeeper 连接端口
- Storm.local.dir storm使用的本地文件系统目录(必须存在并且storm进程可读写)
- Storm.cluster.mode storm集群运行模式([distributed][local])
- Storm.local.mode.zmq zookeeper中storm的根目录位置
- Storm.zookeeper.session.timeout 客户端连接zookeeper超时时间
- Storm.id 运行中拓扑的id,由storm name和一个唯一随机数组成。
- Nimbus.host nimbus服务器地址
- Nimbus.thrift.port nimbus的thrift监听端口
- Nimbus.childopts 通过storm-deploy项目部署时指定给nimbus进程的jvm选项
- Nimbus.task.timeout.secs 心跳超时时间,超时后nimbus会认为task死掉并重分配给一个地址。
- Nimbus.monitor.freq.secs nimbus检查心跳和重新分配任务的时间间隔。注意如果是机器宕掉nimbus会立即接管并处理
- Nimbus.supervisor.timeout supervisor的心跳超时时间,一旦超过nimbus会认为该supervisor已死并停止为它分发新任务。
- Nimbus.task.launch.secs task启动时的一个特殊超时设置。在启动后第一次心跳前会使用该值来临时替代nimbus.task.timeout.secs.
- Nimbus.reassign 当发现task失败时nimbus是否重新分配执行。默认为真,不建议修改。
- Nimbus.file.copy.expiration.secs nimbus判断上传、下载链接的超时时间,当空闲时间超过该设定时nimbus会认为链接死掉并主动断开
- Ui.port storm ui的服务端口
- Drpc.servers DRPC服务器列表,以便DRPCSpout知道和谁通讯
- Drpc.port storm drpc的服务端口
- Supervisor.slots.ports supervisor上能够运行workers的端口列表。每个worker占用一个端口,且每个端口只运行一个worker。通过这项配置可以调整每台机器上运行的worker数
- Supervisor.childopts 在storm-deploy项目中使用,用来配置supervisor守护进程的jvm选项
- Supervisor.worker.timeout.secs supervisor中的worker心跳超时时间,一旦超时supervisor会尝试重启worker进程
- Supervisor.worker.start.timeout.secs supervisor初始启动时,worker的心跳超时时间,当超过该时间,supervisor会尝试启动worker。因为JVM初始启动和配置会带来的额外消耗,从而使得第一次心跳会超过supervisor.worker.timeout.secs的设定
- Supervisor.enable supervisor是否应当运行分配给他的worker。默认为true.该选项用来进行storm的单元测试,一般不应该修改。
- Supervisor.hearbeat.frequency.secs supervisor心跳发送频率(多久发送一次)
- Supervisor.monitor.frequency.secs supervisor检查worker心跳的频率
- Worker.childopts supervisor启动worker时使用的jvm选项。所有的“%ID%”字串会替换为对应worker的标识符
- Worker.heartbeat.frequency.secs worker的心跳发送时间间隔
- Task.hearbeat.frequency.secs task汇报状态心跳时间间隔
- Task.refresh.poll.secs task与其他tasks之间链接同步的频率。(如果task被重分配,其他tasks向它发送消息需要刷新连接)。一般来讲,重分配发生时其他tasks会立即得到通知。该配置仅仅为了防止未通知的情况。
- Topology.debug 如果设置为true,storm将记录发射的每条信息
- Topology.optimize master 是否在合适时机通过在单个线程内运行多个task以达到优化topologies的目的。
- Topology.workers 执行该topology集群中应当启动的进程数量。每个进程内部将以线程方式执行一定数目的tasks.topology的组件结合该参数和并行度提示来优化性能
- Topology.ackers topology中启动的acker任务数。Acker保存由spout发送的tuples的记录。并探测tuple何时被完全处理。当acker探测到tuple被处理完毕时会向spout发送确认信息。通常应当根据topology的吞吐量来确认acker的数目。但一般不需要太多。当设置为0时,相当于禁用了消息的可靠性,storm会在spout发送tuples后立即进行确认。
- Topology.message.timeout.secs topology中spout发送消息的最大处理时间。如果一条消息在该时间窗口内未被成功ack,Storm会告知spout这条消息失败。而部分spout实现了失败消息重播功能。
- Topology.skip.missing.kryo.registrations storm是否应该跳过他不能识别的kryo序列化方案。如果设置为否task可能会转载失败或者在运行时抛出错误。
- Topology.max.task.paralelism 在一个topology中能够允许最大组件并行度。改项设置主要用在本地模式中测试线程数限制。
- Topology.max.spout.pending 一个spout task中处于pending状态的最大的tuples数量。该配置应用于单个task,而不是整个spouts或topology
- Topology.state.synchronization.timeout.secs 组件同步状态源的最大超时时间(保留选项)
- Topology.stats.sample.rate 用啊你产生task统计信息的tuples抽样百分比
- Topology.fall.back.on.java.serialization topology中是否使用java的序列化方案
- Zmq.linger.millis 当连接关闭时,链接测试重新发送信息到目标主机的持续时长。这是一个不常用的高级选项,基本上可以忽略
- Java.labrary.path JVM启动(如 nimbus, Supervisor和workers)时的java。Library.path设置。该选项告诉JVM在哪些路径下定位本地库
Strom集群部署
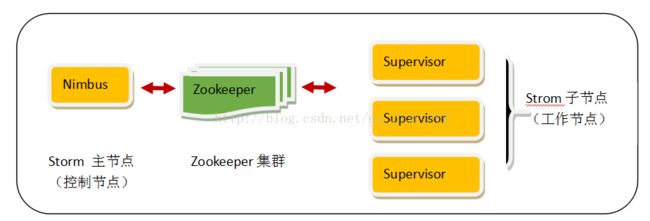
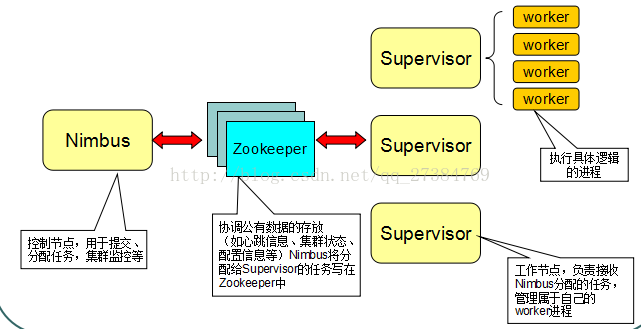
Nimbus和Supervisor
- 在Strom的集群里面有两种节点:控制节点和工作节点。控制节点上面运行一个叫Nimbus进程,Nimbus负责在集群里面分发代码,分配计算任务,并且监控状态。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
- Nimbus负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。
- 每一个工作节点上面运行一个叫做Supervisor进程。Supervisor负责监听从Nimbus分配给它执行的任务,剧此启动或停止执行任务的工作进程
- Zookeeper是Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。
- Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成
nimbus进程和supervisor都是快速失败(fail-fast)和无状态的, 所有的状态都存储在Zookeeper或本地磁盘上
这也就意味着你可以用kill -9来杀死nimbus和supervisor进程, 然后再重启它们, 它们可以继续工作
更重要的是, nimbus和supervisor的fail或restart不会影响worker的工作, 不象Hadoop, Job tracker的fail会导致job失败 - Storm提交运行的程序称为Topology。
Topology处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。
Topology由Spout和Bolt构成。Spout是发出Tuple的结点。Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。Spout和Bolt都统称为component。

安装Strom
安装storm 需要安装如下软件:
JDK
Zeromq
jzmq-master
Zookeeper
Python
storm
安装ZeroMQ
wget http://download.zeromq.org/zeromq-2.2.0.tar.gz
tar zxf zeromq-2.2.0.tar.gz
cd zeromq-2.2.0
./configure (yum install libuuid-devel)
make
make install
zeroMQ有可能缺失g++
安装g++
yum install gcc gcc-c++
注意事项:如果./configure 或者make执行失败,请先安装util-linux-ng-2.17
#unzip util-linux-ng-2.17-rc1.zip
#cd util-linux-ng-2.17
#./configure
#make
#mv /sbin/hwclock /sbin/hwclock.old
#cp hwclock/hwclock /sbin/
#hwclock --show
#hwclock -w
#make install
注意:./configure出现如下错误: configure:error:ncurses or ncursesw selected, but library not found (--without-ncurses to disable)我们加上参数--without-ncurses
安装jzmq
#yum install git
git clone git://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
make install
如果缺失libtool,则先安装
yum install libtool
安装Python
wget http://www.python.org/ftp/python/2.7.2/python-2.7.2.tgz
tar zxvf python-2.7.2.tgz
cd pyton-2.7.2
./configure
make
make install
安装storm
wget http://cloud.github.com/downloads/nathanmarz/storm/storm-0.8.1.zip
unzip storm-0.8.1.zip
vim /etc/profile
export STORM_HOME=/usr/local/storm-0.8.1
如果unzip不能用
yum install unzip
配置Storm
修改storm/conf/storm.yaml文件
storm.zookeeper.servers:
- "zk1"
- "zk2"
- "zk3"
nimbus.host: "zk1"
storm.local.dir: "/usr/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
(注意:先搭建zookeeper集群)说明下:storm.local.dir 表示storm需要用到的本地目录。
nimbus.host 表示哪一台机器是master机器,即nimbus.
storm.zookeeper.servers表示哪几台机器是zookeeper服务器
storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置的端口号一致,否则会出现通信错误。
supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个worker进程(每个sprout或者bolt默认只启动一个worker,但是可以通过conf修改成多个)
java.library.path这是storm所依赖的本地依赖(ZeroMQ 和JZMQ)的加载地址,默认的是:/usr/local/lib :/opt/local/lib:usr/lib,大多数情况下是对的,所以你应该不用更改这个配置
注意:配置时一定注意在每一项的开始时要加空格(最好加两个空格),冒号后也必须要加空格,否则storm不认识这个配置文件。
在目录/usr/tmp下面增加storm文件夹
启动storm:
启动zookeeper环境(启动不正常,执行service iptables stop关闭防火墙)
执行storm nimbus 启动nimbus
执行storm supervisor 启动从节点
执行storm ui 启动ui(ui 和nimbus 需要在同一台机子上面)
注意事项:
storm后台进程被启动后,将在storm安装部署目录下的logs/子目录下生成各个进程的日志文件。
为了方便使用,可以将bin/storm加入到系统环境变量中
启动完毕,通过http://ip:8080/访问UI
#./storm nimbus
#Jps
nimbus
quorumPeerMain
启动UI
#./storm ui > /dev/null 2>&1 &
#Jps
Nimbus
Core
QuorumPeerMain
配置主节点和从节点
1.配置slave节点的配置文件
#cd /cloud/storm-0.8.2/conf/
#vi storm.yaml
storm.zookeeper.servers:
-”master”
nimbus.host: “master””master”
nimbus.host: “master”
2.启动主节点zookeeper
#./zkserver.sh start
#jps
QuorumPeerMain
3.启动主节点strom
# ./storm nimbus > ../logs/info 2>&1 &
4.启动子节点
#./storm supervisor > /dev/null 2>&1 &
#jps
supervisor
5.启动主节点监控页面
#./storm ui > /dev/null 2>&1 &
6.在主节点上运行例子
#./storm jar /home/lifeCycle.jar cn.topology.TopoMain
#Jps
QuorumPeerMain
Jps
Core
Nimbus
#./storm list
storm list 查看再运行的作业列表
7.在从节点上查看jps
#jps
Worker
supervisor
public static void main(String[] args)
throws Exception
{
TopologyBuilder builder = new TopologyBuilder();
//指定spout的并行数量2
builder.setSpout("random", new RandomWordSpout(), Integer.valueOf(2));
//指定bolt的并行数4
builder.setBolt("transfer", new TransferBolt(), Integer.valueOf(4)).shuffleGrouping("random");
builder.setBolt("writer", new WriterBolt(), Integer.valueOf(4)).fieldsGrouping("transfer", new Fields(new String[] { "word" }));
Config conf = new Config();
//指定worker的数量
conf.setNumWorkers(2);
conf.setDebug(true);
log.warn("$$$$$$$$$$$ submitting topology...");
StormSubmitter.submitTopology("life-cycle", conf, builder.createTopology());
log.warn("$$$$$$$4$$$ topology submitted !");
}//指定spout的并行数量2
builder.setSpout("random", new RandomWordSpout(), Integer.valueOf(2));
//指定bolt的并行数4
builder.setBolt("transfer", new TransferBolt(), Integer.valueOf(4)).shuffleGrouping("random");
builder.setBolt("writer", new WriterBolt(), Integer.valueOf(4)).fieldsGrouping("transfer", new Fields(new String[] { "word" }));
Config conf = new Config();
//指定worker的数量
conf.setNumWorkers(2);
conf.setDebug(true);
log.warn("$$$$$$$$$$$ submitting topology...");
StormSubmitter.submitTopology("life-cycle", conf, builder.createTopology());
log.warn("$$$$$$$4$$$ topology submitted !");
}
8.停作业
#./storm kill life-cycle

Storm-start例子
环境装备:
- 下载Storm-start 点击打开链接
- 进入下载目录,对zip文件解压
- 进入压缩后的文件目录,修改m2-pom.xml(将twitter4j-core 和 twitter4j-stream 替换为下面的部分)
- maven的使用参照 点击打开链接
org.twitter4j
twitter4j-core
[2.2,)
org.twitter4j
twitter4j-stream
[2.2,)
- 编译项目。转到项目跟目录,使用mvn -f m2-pom.xml
- package进行编译
- 复制storm-starter目录下的m2_pom.xml为pom.xml放在与m2_pom.xml同一目录下
- 打jar包 mvn jar:jar
- 如果还需要对工程代码进行修改可以导入eclipse
- 使用mvn eclipse: eclipse 编译成eclipse工程
- eclipse import project
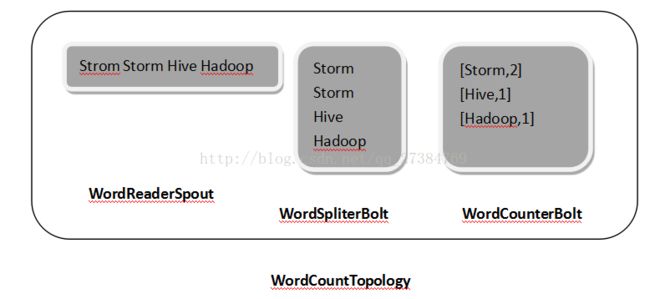
WordCount例子
例子:统计文本中每个单词出现的次数
WordCountTopo:
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.BoltDeclarer;
import backtype.storm.topology.TopologyBuilder;
import cn.storm.bolt.WordCounter;
import cn.storm.bolt.WordSpliter;
import cn.storm.spout.WordReader;
import java.io.PrintStream;
public class WordCountTopo
{
public static void main(String[]args)
{
if (args.length != 2) {
System.err.println("Usage: inputPaht timeOffset");
System.err.println("such as : java -jar WordCount.jar D://input/ 2");
System.exit(2);
}
TopologyBuilder builder =new TopologyBuilder();
builder.setSpout("word-reader",new WordReader());
builder.setBolt("word-spilter",new WordSpliter()).shuffleGrouping("word-reader");
builder.setBolt("word-counter",new WordCounter()).shuffleGrouping("word-spilter");
String inputPaht = args[0];
String timeOffset = args[1];
Config conf = new Config();
conf.put("INPUT_PATH",inputPaht);
conf.put("TIME_OFFSET",timeOffset);
conf.setDebug(false);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount",conf,builder.createTopology());
}
}
WordReader
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.filefilter.FileFilterUtils;
public class WordReader extends BaseRichSpout
{
private static final long serialVersionUID = 2197521792014017918L;
private String inputPath;
private SpoutOutputCollector collector;
public void open(Map conf,TopologyContext context,SpoutOutputCollector collector)
{
this.collector =collector;
this.inputPath = ((String)conf.get("INPUT_PATH"));
}
public void nextTuple()
{
Collection files = FileUtils.listFiles(new File(this.inputPath), FileFilterUtils.notFileFilter(FileFilterUtils.suffixFileFilter(".bak")),null);
for (File f : files)
try {
List lines = FileUtils.readLines(f,"UTF-8");
for (String line : lines) {
this.collector.emit(new Values(new Object[] { line }));
}
FileUtils.moveFile(f,new File(f.getPath() + System.currentTimeMillis() +".bak"));
} catch (IOExceptione) {
e.printStackTrace();
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare(new Fields(new String[] {"line" }));
}
}WordSpliter
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import org.apache.commons.lang.StringUtils;
public class WordSpliter extends BaseBasicBolt
{
private static final long serialVersionUID = -5653803832498574866L;
public void execute(Tuple input,BasicOutputCollector collector)
{
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (StringUtils.isNotBlank(word)) {
word = word.toLowerCase();
collector.emit(new Values(new Object[] {word }));
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare(new Fields(new String[] {"word" }));
}
}
WordCounter
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
import java.io.PrintStream;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
public class WordCounterextends BaseBasicBolt
{
private static final long serialVersionUID = 5683648523524179434L;
private HashMapcounters =new HashMap();
public void prepare(Map stormConf,TopologyContext context)
{
final long timeOffset = Long.parseLong(stormConf.get("TIME_OFFSET").toString());
new Thread(new Runnable()
{
public void run() {
while (true) {
for (Map.Entry entry : WordCounter.this.counters.entrySet()) {
System.out.println((String)entry.getKey() +" : " +entry.getValue());
}
System.out.println("---------------------------------------");
try {
Thread.sleep(timeOffset * 1000L);
} catch (InterruptedExceptione) {
e.printStackTrace();
}
}
}
}).start();
}
public void execute(Tuple input,BasicOutputCollector collector)
{
String str = input.getString(0);
if (!this.counters.containsKey(str)) {
this.counters.put(str, Integer.valueOf(1));
} else {
Integer c = Integer.valueOf(((Integer)this.counters.get(str)).intValue() + 1);
this.counters.put(str,c);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
}
} 运行
![]()
例如nick.txt 中的内容是:
Strom strom hive haddop
统计结果:
Hadoop: 1
Hive 1
Storm 2