Tensorboard深入详解(二)——在keras中自己实现Tensorboard可视化神经网络


前言:上一篇文章中《Tensorboard深入详解(一)——使用keras结合Tensorboard可视化神经网络详细教程》,我们可以看出使用keras预定义的回调函数可以非常方便的实现Tensorboard可视化,简单高效、使用快捷。但是也有不好的地方,比如我不想查看所有的权重,我只对某一个有兴趣,那我就不得不保存所有的信息到日志文件里面,这导致比较浪费,要是有办法可以定制就好了,本文不再继续使用回调函数Tensorboard。
一、训练过程详述
1.1 训练过程的不同
本文的大部分代码和上一篇文章的代码是一样的,主要不同就在于训练过程的不同,上一篇文章的训练过程很简单,就是构造一个Tensorboard对象,然后传递给训练函数fit的callbacks参数,一共两句话,很简单,但是这里就相对较复杂一点了,本文只是为了演示,所以只可视化网络结构graph,然后可视化训练集合测试集的loss与acc。参考下面的代码:
def train_model(model,x_train,y_train,x_val,y_val,batch_size=128,epochs=10):
train_loss = tf.placeholder(tf.float32, [],name='train_loss')
train_acc = tf.placeholder(tf.float32, [],name='train_acc')
val_loss = tf.placeholder(tf.float32, [],name='val_loss')
val_acc = tf.placeholder(tf.float32, [],name='val_acc')
#可视化训练集、验证集的loss、acc、四个指标,均是标量scalers
tf.summary.scalar("train_loss", train_loss)
tf.summary.scalar("train_acc", train_acc)
tf.summary.scalar("val_loss", val_loss)
tf.summary.scalar("val_loss", val_acc)
merge=tf.summary.merge_all()
batches=int(len(x_train)/batch_size) #没一个epoch要训练多少次才能训练完样本
with tf.Session() as sess:
logdir = './logs'
writer = tf.summary.FileWriter(logdir, sess.graph)
for epoch in range(epochs): #用keras的train_on_batch方法进行训练
print(F"正在训练第 {epoch+1} 个 epoch")
for i in range(batches):
#每次训练128组数据
train_loss_,train_acc_ = model.train_on_batch(x_train[i*128:(i+1)*128:1,...],y_train[i*128:(i+1)*128:1,...])
#验证集只需要每一个epoch完成之后再验证即可
val_loss_,val_acc_ = model.test_on_batch(x_val,y_val)
summary=sess.run(merge,feed_dict={train_loss:train_loss_,train_acc:train_acc_,val_loss:val_loss_,val_acc:val_acc_})
writer.add_summary(summary,global_step=epoch)熟悉tensorflow的一定会对这个特别熟悉,这不基本上就是tensorflow的实现吗?是的所以我们可以得出下面这几点经验:
(1)单纯的完全使用keras,简单易用、快捷方便,但是它的可拓展能力稍微欠缺。(备注:随着keras框架的日臻完善,现在基本上你能够用到的功能他都提供了支持);
(2)单纯的使用tensorflow,代码又显得很底层,方便拓展,但是对于一个网络的搭建不是那么简单,而且没有keras那么人性化,看起来一目了然(tensorflow2.0版本将做出了重大更新,看可以选择keras高层API也可以选择tensorflow原始的低层API);
(3)keras+tensorflow则十分合适,比如使用keras来搭建网络结构,这是很简单的,但是一些拓展运算由tensorflow来实现,将二者结合起来就非常强大了。
注意点:keras的train_on_batch()函数和test_on_batch()函数是一次只训练、测试传递进去的那一个batch_size大小的样本数据,故而需要自己手动迭代训练;同时它的返回值是训练集和验证集的loss,acc。
由于验证集需要单独划分,第二个不同点就是数据的划分了,下面是整个模块执行的代码:
1.2 数据的划分稍有区别
if __name__=="__main__":
(x_train,y_train),(x_test,y_test) = mnist.load_data() #数据我已经下载好了
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test)) #(60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
x_train=np.expand_dims(x_train,axis=3)
x_test=np.expand_dims(x_test,axis=3)
y_train=to_categorical(y_train,num_classes=10)
y_test=to_categorical(y_test,num_classes=10)
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test)) #(60000, 28, 28, 1) (60000, 10) (10000, 28, 28, 1) (10000, 10)
x_train_=x_train[1:50000:1,...] #重新将训练数据分成训练集50000组
x_val_=x_train[50000:60000:1,...] #重新将训练数据分成测试集10000组
y_train_=y_train[1:50000:1,...]
y_val_=y_train[50000:60000:1,...]
print(np.shape(x_train_),np.shape(y_train_),np.shape(x_val_),np.shape(y_val_),np.shape(x_test),np.shape(y_test))
#(49999, 28, 28, 1) (49999, 10) (10000, 28, 28, 1) (10000, 10) (10000, 28, 28, 1) (10000, 10)
model=create_model() #创建模型
model=compile_model(model) #编译模型
train_model(model,x_train_,y_train_,x_val_,y_val_) # 训练模型1.3 程序运行的结果查看
下面就是控制台打印出来的信息
正在训练第 1 个 epoch
正在训练第 2 个 epoch
正在训练第 3 个 epoch
正在训练第 4 个 epoch
正在训练第 5 个 epoch
正在训练第 6 个 epoch
正在训练第 7 个 epoch
正在训练第 8 个 epoch
正在训练第 9 个 epoch
正在训练第 10 个 epoch这个信息不是默认就有的,其实是我自己定制的,在每一个epoch完成之后打印出训练到哪里了。是不是也很清晰明了?
二、tensorboard面板
打开tensorboard面板之后发现,只有两个内容面板,一个是graph面板,一个是scalers面板,这是因为我自己只写入这两方面的信息,具体查看一下:
2.1 graph面板
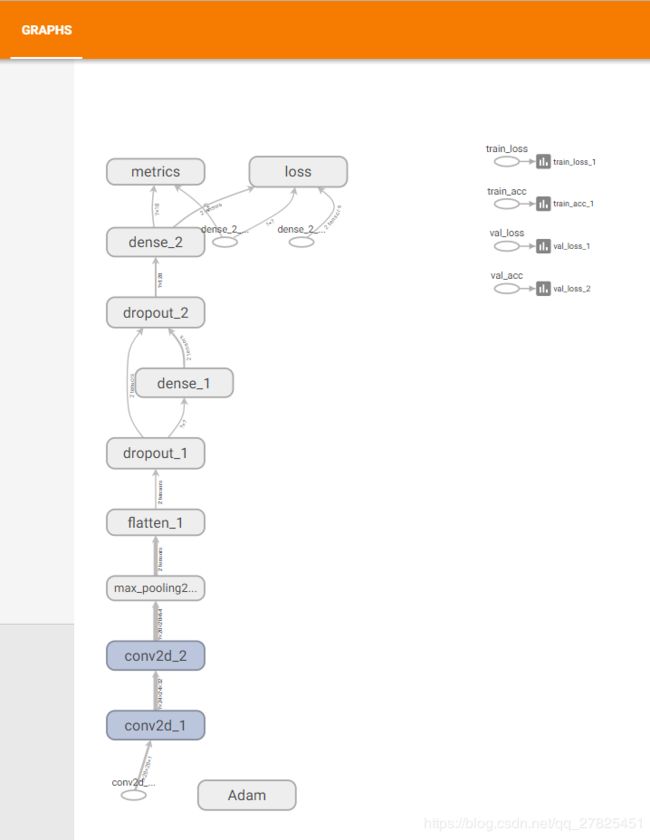
这是不是跟前面的一样?说明我们的实现没有问题。
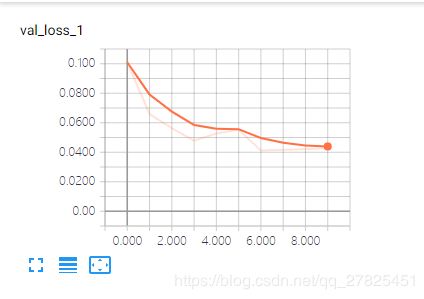
2.2 scalers面板
先查看我写入的4个标量信息
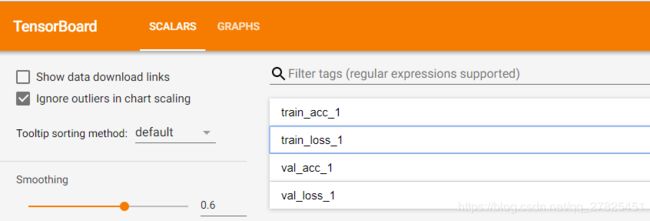
然后再分别查看各自的信息:
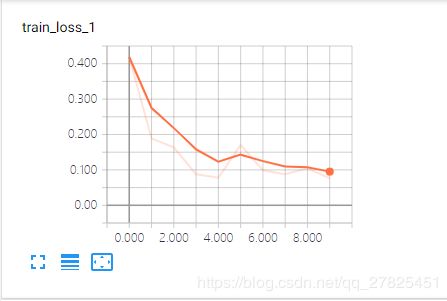
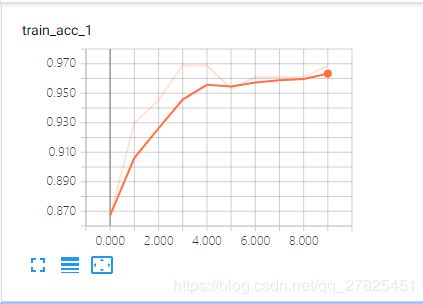

三、完整代码
import numpy as np
import tensorflow as tf
from keras.models import Sequential # 采用贯序模型
from keras.layers import Input, Dense, Dropout, Activation,Conv2D,MaxPool2D,Flatten
from keras.optimizers import SGD
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.callbacks import TensorBoard
def create_model():
model = Sequential()
model.add(Conv2D(32, (5,5), activation='relu', input_shape=[28, 28, 1])) #第一卷积层
model.add(Conv2D(64, (5,5), activation='relu')) #第二卷积层
model.add(MaxPool2D(pool_size=(2,2))) #池化层
model.add(Flatten()) #平铺层
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def compile_model(model):
model.compile(loss='categorical_crossentropy', optimizer="adam",metrics=['acc'])
return model
def train_model(model,x_train,y_train,x_val,y_val,batch_size=128,epochs=10):
train_loss = tf.placeholder(tf.float32, [],name='train_loss')
train_acc = tf.placeholder(tf.float32, [],name='train_acc')
val_loss = tf.placeholder(tf.float32, [],name='val_loss')
val_acc = tf.placeholder(tf.float32, [],name='val_acc')
#可视化训练集、验证集的loss、acc、四个指标,均是标量scalers
tf.summary.scalar("train_loss", train_loss)
tf.summary.scalar("train_acc", train_acc)
tf.summary.scalar("val_loss", val_loss)
tf.summary.scalar("val_acc", val_acc)
merge=tf.summary.merge_all()
batches=int(len(x_train)/batch_size) #没一个epoch要训练多少次才能训练完样本
with tf.Session() as sess:
logdir = './logs'
writer = tf.summary.FileWriter(logdir, sess.graph)
for epoch in range(epochs): #用keras的train_on_batch方法进行训练
print(F"正在训练第 {epoch+1} 个 epoch")
for i in range(batches):
#每次训练128组数据
train_loss_,train_acc_ = model.train_on_batch(x_train[i*128:(i+1)*128:1,...],y_train[i*128:(i+1)*128:1,...])
#验证集只需要每一个epoch完成之后再验证即可
val_loss_,val_acc_ = model.test_on_batch(x_val,y_val)
summary=sess.run(merge,feed_dict={train_loss:train_loss_,train_acc:train_acc_,val_loss:val_loss_,val_acc:val_acc_})
writer.add_summary(summary,global_step=epoch)
if __name__=="__main__":
(x_train,y_train),(x_test,y_test) = mnist.load_data() #数据我已经下载好了
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test)) #(60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
x_train=np.expand_dims(x_train,axis=3)
x_test=np.expand_dims(x_test,axis=3)
y_train=to_categorical(y_train,num_classes=10)
y_test=to_categorical(y_test,num_classes=10)
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test)) #(60000, 28, 28, 1) (60000, 10) (10000, 28, 28, 1) (10000, 10)
x_train_=x_train[1:50000:1,...] #重新将训练数据分成训练集50000组
x_val_=x_train[50000:60000:1,...] #重新将训练数据分成测试集10000组
y_train_=y_train[1:50000:1,...]
y_val_=y_train[50000:60000:1,...]
print(np.shape(x_train_),np.shape(y_train_),np.shape(x_val_),np.shape(y_val_),np.shape(x_test),np.shape(y_test))
#(49999, 28, 28, 1) (49999, 10) (10000, 28, 28, 1) (10000, 10) (10000, 28, 28, 1) (10000, 10)
model=create_model() #创建模型
model=compile_model(model) #编译模型
train_model(model,x_train_,y_train_,x_val_,y_val_)