适合小白的 Hadoop 集群配置搭建,非常详细
准备工作:
1。VMware Workstation 14 中安装虚拟机 ,版本为 CentOS7(我搭建的集群为三台,安装一台克隆两台,这里不做解释,可自行百度)
2。JDK1.8 ,下载地址为 https://pan.baidu.com/s/15YA23CYnT3L-9f6Ao-gzrw
3。hadoop2.7.5 下载地址为 https://pan.baidu.com/s/1Fyfb77R6Tl1ct3pm_yaLdA新建用户
每个虚拟机创建一个hadoop用户并加入到root组中
#添加用户hadoop到root组中
useradd -m hadoop -G root -s /bin/bash
#修改用户密码--输入密码,再次输入密码 (建议密码也设置为hadoop)
passwd hadoop 修改ip为静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33注意: 最后末尾处添加的ip地址网段要和虚拟机中的网段保持一致,(Ip自定义但是不能超过255)
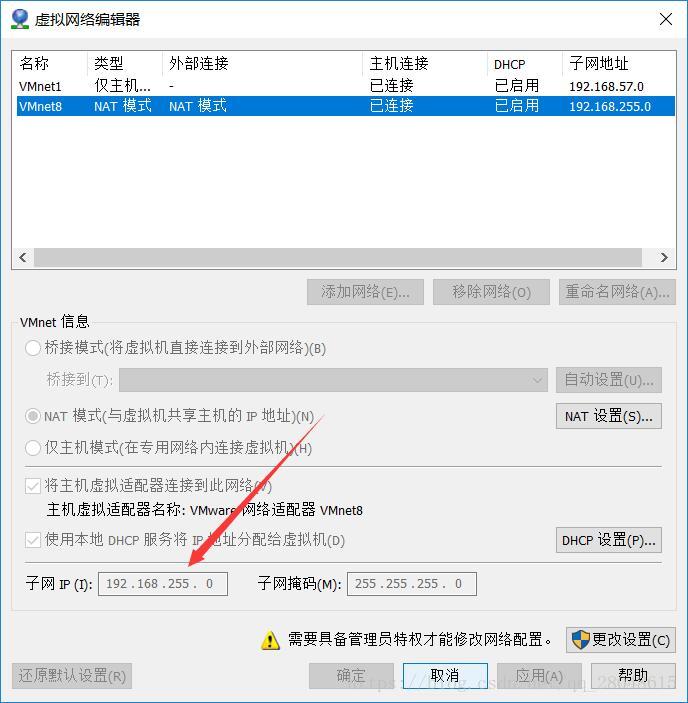
其中这两个中的第三位数字要和VMware Workstation中的网段一致,查看网段看第二张图
打开的位置是 :编辑 ->虚拟网络编辑器
IPADDR=192.168.255.131
GATEWAY=192.168.255.2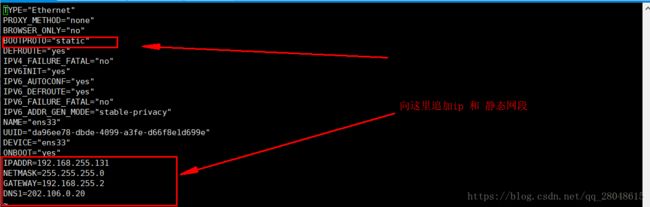
修改完成后 ,重启网管
[root@dnn1 ~]systemctl restart network然后修改主机名方便以后访问(不需要在输入ip那么麻烦了以后)
[root@dnn1 ~]# echo nnn > /etc/hostname
修改映射
vim /etc/hosts向这个hosts文件追加三行 ,格式为 Ip地址 主机名 ,一会方便linux 系统之间进行通信
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.255.130 nn
192.168.255.131 dn1
192.168.255.132 dn2
完成之后重启
[root@dnn1 ~]# reboot安装上述的方法将其他两台虚拟机也修改了,保证ip不一样就可以
root 是超级管理员用户,所做操作无法更改,我们集群的搭建是在hadoop 用户上搭建的,标题即使以后有什么问题也不会影响到整个系统
用hadoop用户登录到每台机器上
[root@dnn1 ~]# sudo hadoop在用户根目录下面配置 SSH 无密码登录
[hadop@nnn ~]$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[hadop@nnn ~]$ ssh-copy-id dnn1
[hadop@nnn ~]$ ssh-copy-id dnn2
##然后测试是否主机之间登录是否需要密码
[hadop@nnn ~]$ ssh dnn1
#查看主机名,打印的是dnn1 ,无密码登录成功,然后退出
[hadop@dnn1 ~]$ hostname
dnn1
[hadop@dnn1 ~]$ exit
[hadop@nnn ~]$ ssh dnn2
#查看主机名,打印的是dnn2 ,无密码登录成功,然后退出
[hadop@dnn2 ~]$ hostname
dnn2
[hadop@dnn1 ~]$ exit配置Java和Hadoop 的环境变量
新建opt文件夹(用于存放安装Linux软件的)
将下载的 jdk 1.8 和hadoop2.7.5的安装包解压到opt 文件夹中,然后解压配置环境变量
[hadop@nnn ~]$ mkdir opt
[hadop@nnn ~]$ vi ~/.bashrc
###向文件中添加如下代码(jdk8文件夹和hadoop2 是jdk 和hadoop文件解压后更改的名字)
#JAVA_JDK1.8
export JAVA_HOME=/home/hadoop/opt/jdk8
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP
export HADOOP_HOME=/home/hadoop/opt/hadoop2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
使环境变量生效(每台机子)
[hadop@nnn ~]$ source ~/.bashrc集群搭建开始了
搭建hadoop全分布式集群
进入hadoop解压目录
在/home/hadoop/opt/hadoop2/etc/hadoop/文件夹下面修改以下 5个文件
1 core-site.xml
2 hdfs-site.xml
3 mapred-site.xml
4 yarn-site.xml
5 slaves
1.core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://nnn:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/hadoop/opt/hadoop2/tmpvalue>
property>
configuration>
2.hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>nnn:50090value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/hadoop/opt/hadoop2/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/hadoop/opt/hadoop2/tmp/dfs/datavalue>
property>
configuration>
3.mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.app-submission.cross-platformname>
<value>truevalue>
property>
configuration>
4.yarn-site.xml 配置yarn的主机地址洗牌的默认框架
<property>
<name>yarn.resourcemanager.hostnamename>
<value>nnnvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
5.slaves #配置所有dn的主机名称
dn1
dn2进入hadoop的安装目录,远程分发到服务器上
[hadop@dnn1 ~]$ cd /home/hadoop/opt/
#将整个hadoop2 复制到 其他两台机器上 $PWD 是当前的目录,意思是将 hadoop2 整个文件夹复制到dnn1和dnn2 的这个相同路径下
scp -r hadoop2/ dnn1:$PWD
scp -r hadoop2/ dnn2:$PWD启动集群
一、格式化hdfs 文件系统(只需要这第一次,以后启动不需要了,只在nnn(master节点上启动,其他的节点不需要启动) )
[hadop@nnn ~]$ hadoop namenode -format
二、启动dfs 服务和yarn 服务
[hadop@nnn ~]$ start-dfs.sh
[hadop@nnn ~]$ start-yarn.sh三、验证是否有开启的服务,在nnn(master 机器上) 输入jps 查看有进程没有
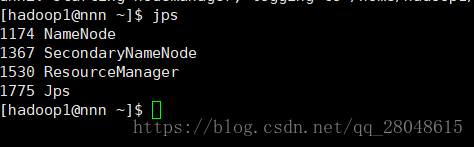
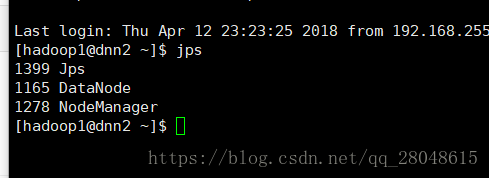
然后分别在 dnn1 和dnn2 (slaves 节点) 输入jps 查看是否有进程
四、验证是否能够在web 端浏览页面,在浏览器中输入 nnn:50070
注意: 如果你的页面打不开,有两种可能,
1.你在windows 上的ip 映射没有配置,
2 Linux 的防火墙没有关
1修改windows ip 映射
C:\Windows\System32\drivers\etc\hosts将这个文件拷贝到桌面上,修改后 覆盖(管理员权限,无法直接打开修改,只能替换)
末尾添加
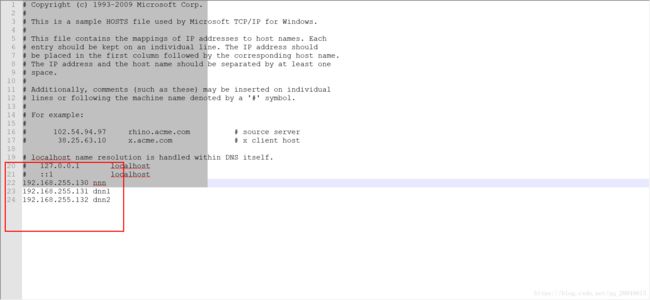
2修改防火墙
`
禁止开机启动
[root@nnn ~]# systemctl disable firewalld
修改里面的参数 SELINUX=disabled
[root@nnn ~]# vim /etc/selinux/config
以后开机就永远都是关闭防火墙了
`
再次测试访问hadoop web 页面
访问nnn:50070
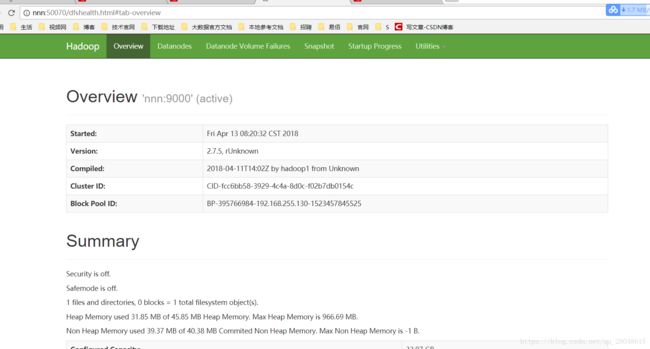
查看活着的子节点是否为2 (即子节点的数量)
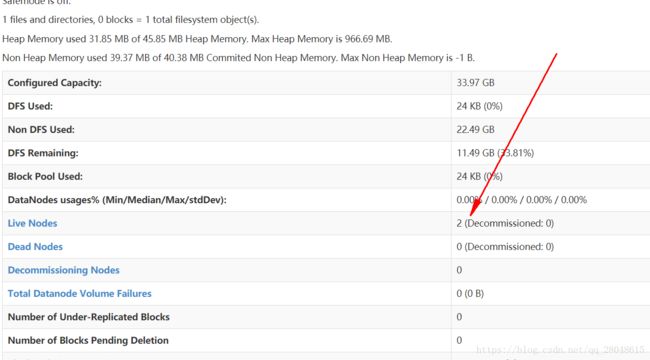
因为我的集群有三台,master 一台,slave为两台,所以活着的节点信息是2
到此集群就启动成功了~
哈哈!!! 恭喜你,集群搭建成功,若有什么问题,欢迎留言!我会给大家回复的