【论文笔记1】RNN在图像压缩领域的运用——Variable Rate Image Compression with Recurrent Neural Networks
一、引言
随着互联网的发展,网络图片的数量越来越多,而用户对网页加载的速度要求越来越高。为了满足用户对网页加载快速性、舒适性的服务需求,如何将图像以更低的字节数保存(存储空间的节省意味着更快的传输速度)并给用户一个低分辨率的thumbnails(缩略图)的preview变得越来越重要。如今有很多的标准图像压缩算法,如JPEG、JPEG2000、WebP已经有了很不错的表现。如何利用其他方法提高图像压缩比并又能最大程度地保存原始图片信息是相关领域集中研究的问题。
最近在和协会的同学一起学习图像压缩相关的知识,现在还在起步阶段。看了一些相关的论文,了解到最近几年深度学习在图像压缩领域也有着非常不错的发展,一些深度网络框架的表现已经outperform了很多标准的图像压缩算法。我从中挑选了几篇最经典的认真学习了一下,本文便是RNN在图像压缩领域运用的最经典的一篇,是Google的George Toderici以及他的团队提出的。原论文传送门:《Variable Rate Image Compression with Recurrent Neural Networks》
文章提出了一种基于卷积和反卷积LSTM的RNN网络框架,并强调该网络框架有如下技术优点:
(1)网络只需要训练一次,而不是每张图片都需要训练,并且图片输入大小和压缩比变化也不需要重复训练;
(2)网络具有连续性,也就是说越多字节数的representation code意味着越高的图片重建精确度;
(3)至少可以说和训练后的自编码器模型在相同的比特数下有着相同的效率。
在展开讲文章提出的RNN网络框架前,需要先了解普适的标准图像压缩算法和标准自编码器模型,以及它们存在的问题。
二、标准图片压缩算法的缺点
如今,很多普适的标准图像压缩算法取得了很不错的效果,例如Joint Picture Experts Group提出的JPEG和JPEG2000,以及刚提出不久的WebP算法,但是它们都普遍地存在如下两个问题:
(1)专注于大图片的压缩,低分辨率的thumbnail图片的压缩效果不佳,甚至受损。因为它们图片压缩的原理都来自同一切入点:先设计不同的启发方法减少需要保留的图片信息,再决定能够利用保留的信息尽可能低损地压缩图片的转换方法。
(2)图像scale上的假设大多不成立。例如假设高分辨率的图片包含许多冗余的信息,而实际上图片分辨率越高,来自图片的patch包含的低频信息越多。因此这些假设在生成高分辨率图像的thumbnail图的时候并不成立,因为来自thumbnail的patch更多的包含难压缩的高频信息。
要知道,压缩thumbnails的大小,不仅是降低存储大小,而且要更好地利用网络带宽是一个至关重要的问题,因为现在的网络中有数量十分巨大的缩略图,提高缩略图的压缩技术便能显著提高用户在低带宽网络连接时的上网体验。而目前的标准图像压缩算法并不能胜任。
三、标准自编码器模型的缺点
近些年来,基于神经网络的算法在图像识别和目标检测领域有了飞速的发展,很多学者自然而然地想到能否利用神经网络方法进行图像压缩。Krizhevsky和Hinton于2011年提出了标准自编码器模型,利用神经网络作为编码器(encoder)去生成一个具有代表性的编码,再利用解码器(decoder)根据编码结果重建原始图片。
图片patch经过encoder编码生成一个representation,然后经过二值化函数生成一个二值化编码,最后经过一个decoder利用二值化编码重建原始的图片patch。整个流程可以用如下方程表示:
![]()
其中x是原始图片,x'是压缩重建的图片,E是编码器函数,B是二值化函数,D是解码器函数。
然而标准自编码器存在很多限制条件使得它们无法推广作为标准的图片编码解码器。其中的一些限制条件使得变压缩比的压缩过程无法实现,每一个压缩比需要对应一个单独的网络单独训练,这是很不经济的行为,并且输出的图片质量并不能保证,因为它们都是为了专门的图片大小设计的,只能在对应的图片大小上抓取图片中的冗余信息。
四、本文提出的RNN模型框架
1、基于残差输入的图像压缩网络框架
用输出和原始图片的残差作为图像的输入可以保证网络的连续性,即每步训练可以产生图片的增量信息。因此,网络可以用如下方程表示:
![]()
r便是残差输入,下标表示的是迭代的时间点。
基于残差输入的压缩网络分为基于LSTM的和不基于LSTM的。
对于没有LSTM结构的模型,F没有记忆性,每一步的残差仅根据上一步的残差结果计算得出,因此,整个图像patch的重建是通过将残差全部加起来的总和得出的,例如后文将要提到的前向全连残差编码器(feed-forward fully-connected residual encoder)和前向卷积/反卷积残差编码器(feed-forward convolutional/deconvolutional residual encoder)。每一步的残差计算公式如下:
![]()
对于有LSTM结构的模型,F具有记忆性,每一步的残差直接根据原始图片计算得出,因此每一步的输出都是在预测原始图片patch,例如后文将要提到的基于LSTM的压缩网络(LSTM-based compression)和基于LSTM的卷积/反卷积压缩网络(convolutional/deconvolutional LSTM-based compression)。每一步的残差计算公式如下:
![]()
无论是基于LSTM结构的压缩网络还是不基于LSTM的压缩网络按如下方式训练网络的,其中N是网络中的自编码器的总数:
![]()
2、二值化representation编码
文章引用的二值化方法分为如下两步:
(1)第一步使用一个全连层加tanh激活函数,将经过编码器得到的representation映射到(-1,1)的区间内;
(2)利用如下函数将(-1,1)区间内的编码二值化为集合{-1,1}:
![]()
![]()
因此,整个二值化编码器可以表示成:
![]()
其中W、b分别是线性全连层的权重和偏置,x为上一层的激活值。图像的压缩比由每一步生成的representation的比特数(即W矩阵的行数)和网络迭代次数(即残差自编码器的重复次数)共同决定。
3、模型一:不基于LSTM的前向全连残差编码器
文章首先提出最简单的实例便是全连层堆叠起来的编码器E和解码器D,文章还设置每一个全连层的输出的个数均为512,并且只使用tanh非线性激活函数。网络框架如下图所示:

从结构图片可以看出,最终图片patch的重建是通过所有stage的residual加和得到的。
4、模型二:基于LSTM的残差编码器
该模型通过堆叠LSTM层搭建基于LSTM的编码器E和解码器D。并且本文使用的LSTM结构是2013年由Grave提出的简易结构,该简易LSTM结构如下:
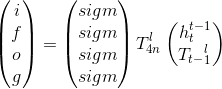
![]()
![]()
![]()
![]()
其中带上标l和小标t的h代表第l层、t时间点的LSTM隐层的状态,T代表一种仿射变换,圆圈里加一点代表的是元素级别的乘法。这种简易的LSTM能够减少每一步的操作数,能够保证GPU的高效执行。基于LSTM的压缩网络结构如下:
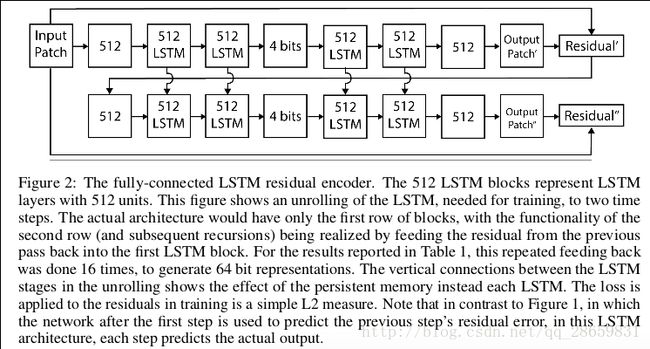
编码器中由一个全连层后跟上两个LSTM层构成;解码器由两个LSTM层后跟上一个全连层加上一个tanh非线性激活函数构成来预测原始图片patch的RGB值,因此每一步迭代都是在预测原始图片patch。
5、模型三:不基于LSTM的前向卷积/反卷积残差编码器
文章在模型一中提出了全连的残差自编码器,文章在此基础上用卷积操作代替模型一编码器中的全连层,用反卷积操作代替模型一解码器中的全连层,并通过3个1×1的卷积将解码后的representation转化为三通道的RGB值。不基于LSTM的前向卷积/反卷积残差编码器结构如下:
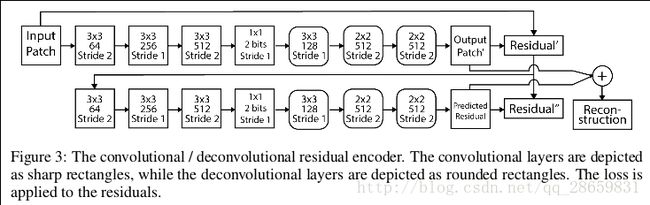
同样,类似于模型一,图片patch的重建是通过加和所有stage的residual得到的。
6、模型四:基于LSTM的前向卷积/反卷积残差编码器
最后一个模型的编码器将模型三(见图片3)编码器和解码器中的第二个和第三个卷积和反卷积层替换为LSTM卷积和反卷积层,即将模型二中的仿射变换T替换为为卷积加上偏置。
LSTM卷积操作方程为:
![]()
LSTM反卷积操作方程为:
![]()
用c和d来区分卷积和反卷积操作。
五、实验和评价标准
1、训练
文章采用Adam算法,使用多种学习率,分别为{0.1,0.3,0.5,0.8,1}进行训练,损失函数为根据patch像素个数和迭代总步数标准化后的L2损失,采用从8至16多种编码步数进行试验。
文章使用的32×32图像数据集中含有从公共网络中收集的216,000,000张随机色彩的图片,对于一些大小不是32×32的质量不错的图像,文章通过降采样将图片转换为32×32,最终的32×32图片都被无损的用PNG格式保存作为训练和测试的数据集。训练LSTM模型时,90%的图像作为训练集,10%的图像作为测试集,为了验证编码器的性能,将100,000张的随机图片子集作为验证集。
2、评价标准
文章强调不应采用PSNR作为评价标准,因为PSNR偏向于使用L2损失的模型,这在本文提出的模型和JPEG算法的比较中对JPEG算法不公平,因此文章放弃采用PSNR,而采用SSIM(Structural Similarity Idex)。文章将32×32的图片分成不同的8×8的patch,并且在不同patch和不同颜色通道上计算SSIM,最后的得分由所有patch和channel的平均SSIM给出。在分析结果的时候,更高的得分表示更好的图像重建,1.0表示完美重建。
SSIM,结构相似性,是一种衡量两幅图像相似度的指标。该指标首先由德州大学奥斯丁分校的图像和视频工程实验室(Laboratory for Image and Video Engineering)提出。给定两个图像x和y, 两张图像的结构相似性可按照以下方式求出:
![]()
当两张图像一模一样时,SSIM的值等于1。
六、结果和分析
文章的各个网络的评价结果以及与标准图像压缩算法(JPEG,JPEG2000和WebP)的比较结果由如下表格给出:
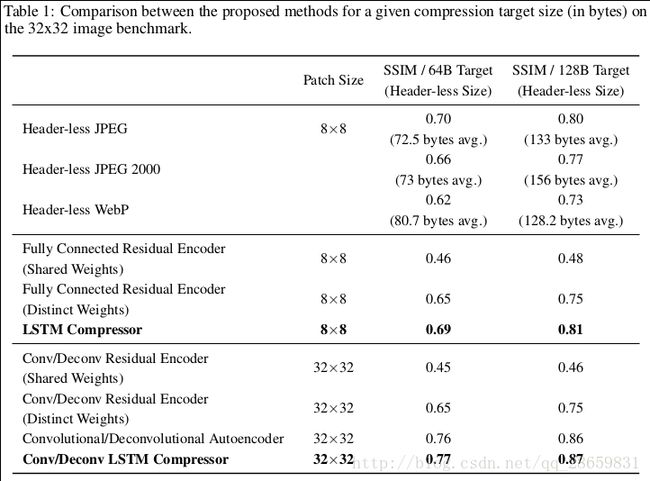
全连的LSTM模型的性能可以和JPEG相媲美,基于LSTM的卷积/反卷积模型能够在SSIM感知矩阵这一指标上超越JPEG。
-------------------------------------------
Youzhi Gu, master student
Foresight Control Center
College of Control Science & Engineering
Zhejiang University
Email: [email protected]