初识nlp ( 3 ( rnn rnn应用1 自动写作
普通神经网络
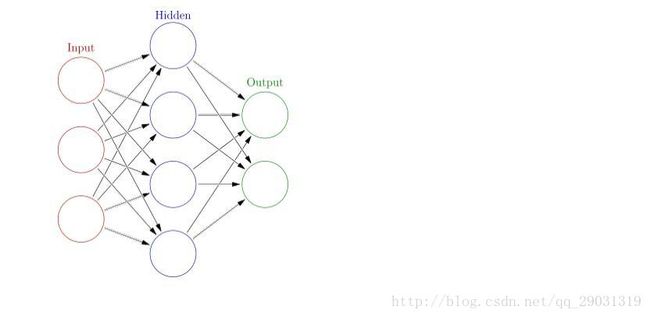
h1 = f(w1x1+w2x2+w3x3)
o1 = f(w’1h1+w’2h2+w’3h3)
o1<-> y1 loss’= ∆
带记忆神经网络
rnn
带sequential的网络 sequential:有时序的

前一个的输出 在后一个的输入中考虑
lstm (long short-term memory)
rnn 加强版
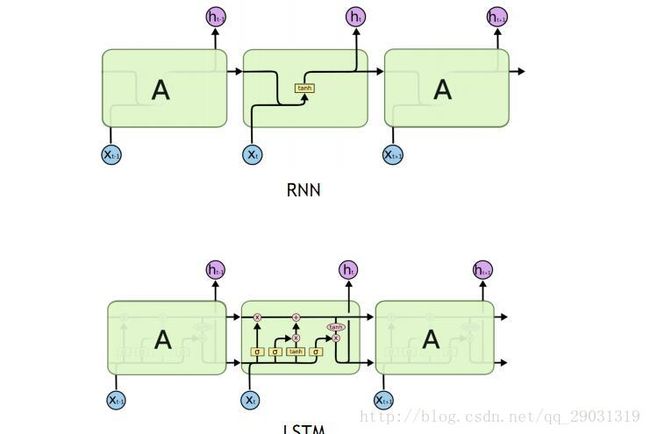
用xor and 来计算
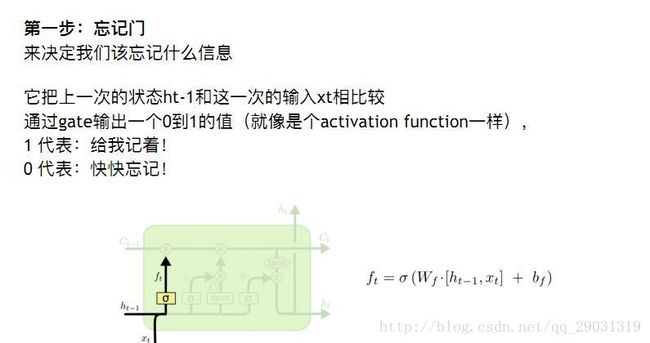
将上次输出 这次输入 做计算
h 得到 忘记的
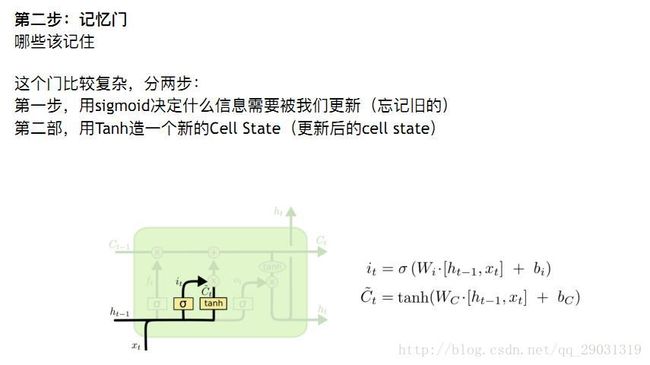
C 用tanh 得到新的cell state
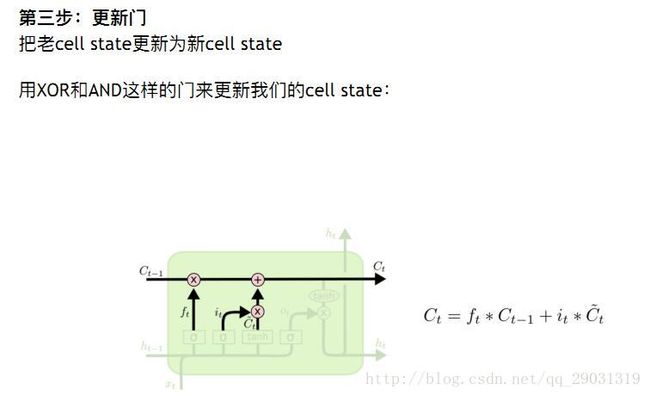
将旧的C 与新的C 逻辑更新
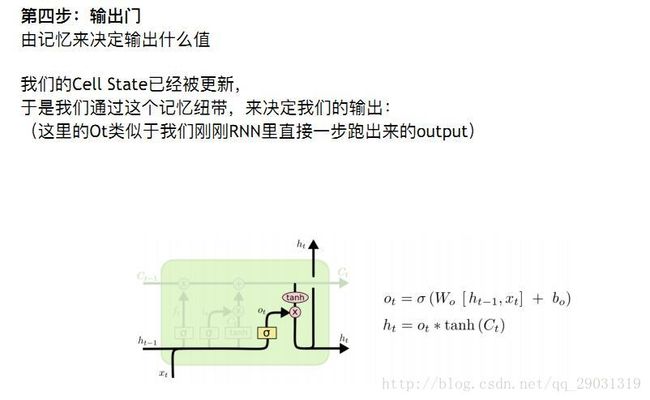
得到新的输入 和下轮要用的输入
案例
自动写作 、 QA机器人
用rnn做文本生成
#导入库 keras深度学习库
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils#读入txt
raw_text = open('winston.txt').read()
raw_text = raw_text.lower()#得到字符的 one-hot
chars = sorted(list(set(raw_text)))
char_to_int = dict((c,i) for i,c in enumerate(chars))
int_to_char = dict((i,c) for i,c in enumerate(chars))enumerate 的用法
#for A,i in enumerate(‘abc’):
print i,A
a 0
b 1
c 2
将raw text变成训练集 x为前置字母 y为后一个字母
seq_length = 100
x = []
y = []
for i in range(0,len(raw_text),seq_length):
given = raw_text[i:i+seq_length]
predict = raw_text[i+seq_length]
x.append([char_to_int[char] for char in given])
y.append([char_to_int[predict]])
print x[3]
把x变成lstm所需格式 【样本数,时间步伐,特征】
n_patterns =len(x)
n_vocab = len(chars)
x = numpy.reshape(x,(n_patterns,seq_length,1)) #特征为1
x = x / float(n_vocab) #x在 0-1上
y = np.utils.to.categorical(y) #将y变成 one-hot 形式 降低对精确度的要求lstm模型构造
model = Sequential() #Sequential型
model.add(LSTM(128,input_shape=(x.shape[1],x.shape[2]))) # 【100,1】
model.add(Dropout(0.2)) #每次丢掉20% 防止过拟合
model.add(Dense(y.shape[1],activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam') #loss函数, adam优化model.fit(x,y,nb_epoch=10,batch_size=32) #跑10次 只取32个数据 做一次学习看看lstm的效果
def string_to_index(raw_input): #将生词 转换成 int 数组
res = []
for e in raw_input[(len(raw_input)-seq_length):]:
res.append(char_to_int[e])
return res
def predict_next(input_array): #预测下一个y
x = numpy.reshape(input_array,(1,seq_length,1))
x = x / float(n_vocab)
y = model.predict(x)
return y
def y_to_char(y): # 将y输出 字符e
largest_index = y.argmax()
e = int_to_char[largest_index]
return e
def generate_article(init,rounds =50):
in_string = init.lower()
for i in range(rounds):
n = y_to_char(predict_next(string_to_index(in_string)))
in_string += n
return in_string
init = 'he is a great man'
article = generate_article(init)
print article用wordtovec版本
单词为基础
hello =w1 for =w2
[[w1] [w2] ] ->lstm
多导入一个
from gensim.models.word2vec import Word2Vec#word2vec 用上下文定义词
sentensor = nltk.data.load('tokenizers/punkt/english.pickle')
sents = sentensor.tokenize(raw_text) #分句
corpus = []
for sen in sents:
corpus.append(nltk.word_tokenize(sen)) #分词#训练
w2v_model = Word2Vec(corpus,size =128,window=5,min_count =5,workers= 4)
#在这模型中 可以加上其他语料 , 因为真正训练是用lstm,w2v不会影响#处理training data 把数据变成lstm可读的
raw_input = [item for sublist in corpus for item in sublist ]
# 把2维转化为1维,在对list []1 x n 变成 [] 1x1 n个
text_stream = []
vocab = w2v.model.vocab
for word in raw_input:
if word in vocab:
text_stream.append(word)
#除去 min_count <5 的seq_length = 10
x = []
y = []
for i in range(0,len(raw_text),seq_length):
given = raw_text[i:i+seq_length]
predict = raw_text[i+seq_length]
x.append([char_to_int[char] for char in given])
y.append([char_to_int[predict]])
print x[3]
x = np.reshape(x,(-1,seq_length,128)) #128因为word2vec为128维
y = np.reshape(y,(1,128))
model = Sequential() #Sequential型
model.add(LSTM(128,dropout_W=0.2,dropout_U=0.2,input_shape=(x.shape[1],x.shape[2]))) #对内部的weights 也做dropout 减少overfit
model.add(Dropout(0.2))
model.add(Dense(y.shape[1],activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam')