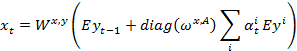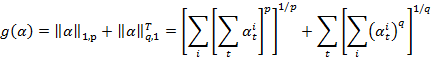- 【论文笔记ing】Pointerformer: Deep Reinforced Multi-Pointer Transformer for the Traveling Salesman Problem
Booksort
online笔记论文论文阅读transformer深度学习
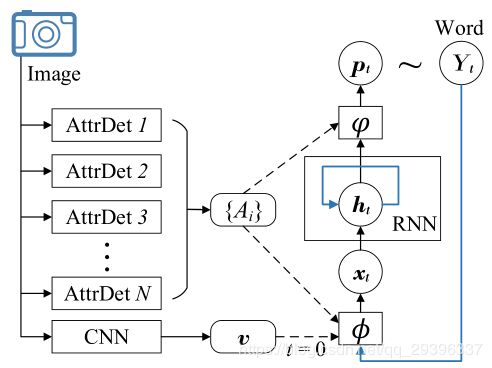
论文中使用一个PointerFormer模型编码器部分:可逆残差模型堆叠解码器部分:指针网络自回归对于一次任务而言,推理阶段:编码器部分:一次解码器部分:循环N次,直至任务结束在训练阶段,使用强化学习,对于一个N个节点的TSP实例,算法中会以不同的起点,跑N次,得到N个轨迹,以满足TSP的对称特性,表示这都是属于一个TSP问题的(真实)解然后会计算这样表示归一化奖励,得到一个advantage,然
- 【论文笔记】GaussianFusion: Gaussian-Based Multi-Sensor Fusion for End-to-End Autonomous Driving
原文链接:https://arxiv.org/abs/2506.00034v1简介:现有的多传感器融合方法多使用基于注意力的拉直(flatten)融合或通过几何变换的BEV融合,但前者可解释性差,后者计算开销大(如下图(a)(b)所示)。本文提出GaussianFusion(下图(c)),一种基于高斯的多传感器融合框架,用于端到端自动驾驶。使用直观而紧凑的高斯表达,聚合不同传感器的信息。具体来说,
- 【论文笔记】RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
AustinCyy
论文笔记论文阅读
论文信息论文标题:RAGLAB:AModularandResearch-OrientedUnifiedFrameworkforRetrieval-AugmentedGeneration-EMNLP24论文作者:XuanwangZhang-NanjingUniversity论文链接:https://arxiv.org/abs/2408.11381代码链接:https://github.com/fat
- Llama改进之——RoPE旋转位置编码
愤怒的可乐
NLP项目实战#LLaMARoPE旋转位置编码
引言旋转位置编码(RotaryPositionEmbedding,RoPE)将绝对相对位置依赖纳入自注意力机制中,以增强Transformer架构的性能。目前很火的大模型LLaMA、QWen等都应用了旋转位置编码。之前在[论文笔记]ROFORMER中对旋转位置编码的原始论文进行了解析,重点推导了旋转位置编码的公式,本文侧重实现,同时尽量简化数学上的推理,详细推理可见最后的参考文章。复数与极坐标复数
- Llama改进之——均方根层归一化RMSNorm
愤怒的可乐
NLP项目实战#llama
引言在学习完GPT2之后,从本文开始进入Llama模型系列。本文介绍Llama模型的改进之RMSNorm(均方根层归一化)。它是由RootMeanSquareLayerNormalization论文提出来的,可以参阅其论文笔记1。LayerNorm层归一化(LayerNorm)对Transformer等模型来说非常重要,它可以帮助稳定训练并提升模型收敛性。LayerNorm针对一个样本所有特征计算
- 论文笔记 <交通灯><多智能体>CoLight管理交通灯
青椒大仙KI11
论文阅读
今天看的是论文Colight:学习网络级合作进行交通信号控制论文提出的CoLight模型是一种基于强化学习和图注意力网络的交通信号灯控制方法,旨在解决城市道路网络中的交通信号的写作问题,提升车辆通行效率。问题定义为:将交通信号控制问题建模为马尔可夫博弈,每个路口由一个智能体控制,智能体通过观察部分系统状态(当前相位和各车道车辆数),选择动作(下一时间段的相位),目标是最小化路口周围车道的平均队列长
- 《基于超声的深度学习模型用于降低BI-RADS 4A乳腺病变的恶性率》论文笔记 MobileNet
往事随风、、
论文笔记机器学习深度学习论文阅读人工智能机器学习健康医疗
《APPLICATIONOFDEEPLEARNINGTOREDUCETHERATEOFMALIGNANCYAMONGBI-RADS4ABREASTLESIONSBASEDONULTRASONOGRAPHY》《基于超声的深度学习模型用于降低BI-RADS4A乳腺病变的恶性率》原文地址:链接文章目录摘要简介方法患者图像获取与处理深度学习模型统计分析结果讨论结论摘要本研究旨在开发一个基于超声(US)图像
- 论文笔记--Language Models are Unsupervised Multitask Learners
Isawany
论文阅读论文阅读语言模型transformerchatgpt自然语言处理
论文笔记GPT-2--LanguageModelsareUnsupervisedMultitaskLearners1.文章简介2.文章导读2.1概括2.2文章重点技术2.2.1数据集WebText2.2.2分词方法3.GPT-1&GPT-24.文章亮点5.原文传送门6.References1.文章简介标题:LanguageModelsareUnsupervisedMultitaskLearners
- You Only Look Once Unified, Real-Time Object Detection论文笔记
__Lo__
目标检测论文阅读深度学习
文章结构统一检测框架(UnifiledDetection)核心思想YOLO将目标检测视为一个端到端的回归问题,输入的图像经过SingleForwardPass,直接输出物体的信息(边界框的位置、边界框的置信度、类别概率);优势在于速度快,全局理解上下文,这里全局理解上下文的意思是识别物体和背景的关系,减少误检。网络设计网格划分(GridDivision)将图像划分为一个S×S的网格,文中S=7;共
- 【论文笔记】UnifiedQA:新SOTA,生成模型一统问答任务
iLuz
深度学习自然语言处理
目录引言模型介绍1.输入格式2.实验结果总结引言问答任务有多种形式,常见的有抽取式问答(EX)、摘要式问答(AB)、多选题式问答(MC)、判断式问答(YN)。一般的解决方案是针对不同形式的问答任务设计不同的模型。例如,抽取式问答、多选题式问答、判断式问答可以转化为分类任务,摘要式问答可以转换为生成任务。尽管任务形式不同,但模型所需的语义理解和推理能力是共通的,或许不需要format-special
- [论文笔记] [2008] [ICML] Extracting and Composing Robust Features with Denoising Autoencoders
Alexzhuan
DL神经网络机器学习
在06年以前,想要去训练一个多层的神经网络是比较困难的,主要的问题是超过两层的模型,当时没有好的策略或方法使模型优化的很好,得不到预期的效果。在06年,Hinton提出的stackedautoencoders改变了当时的情况,那时候的研究者就开始关注各种自编码模型以及相应的堆叠模型。这篇的作者提出的DAE(DenoisingAutoencoders)就是当时蛮有影响力的工作。那个时候多层模型效果得
- 【论文笔记】SecAlign: Defending Against Prompt Injection with Preference Optimization
AustinCyy
论文笔记论文阅读
论文信息论文标题:SecAlign:DefendingAgainstPromptInjectionwithPreferenceOptimization-CCS25论文作者:SizheChen-UCBerkeley;Meta,FAIR论文链接:https://arxiv.org/abs/2410.05451代码链接:https://github.com/facebookresearch/SecAli
- CLIP论文笔记:Learning Transferable Visual Models From Natural Language Supervision
Q同学的nlp笔记
论文阅读语言模型人工智能nlp自然语言处理
导语会议:ICML2021链接:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf当前的计算机视觉系统通常只能识别预先设定的对象类别,这限制了它们的广泛应用。为了突破这一局限,本文探索了一种新的学习方法,即直接从图像相关的原始文本中学习。本文开发了一种简单的预训练任务,通过预测图片与其对应标题的匹配关系,从而有效地从一个包含4亿
- 论文笔记:Large Language Models are Zero-Shot Next LocationPredictors
UQI-LIUWJ
论文笔记论文阅读语言模型人工智能
1intro下一个地点预测(NL)包括基于个体历史访问位置来预测其未来的位置。NL对于应对各种社会挑战至关重要,包括交通管理和优化、疾病传播控制以及灾害响应管理NL问题已经通过使用马尔可夫模型、基于模式的方法以及最近的深度学习(DL)技术(进行了处理。然而,这些方法并不具备地理转移能力因此,一旦这些模型在某个地理区域训练完毕,如果部署到不同的地理区域,它们将面临严重的性能下降尽管已经做出努力改善地
- 论文笔记:LSTPrompt: Large Language Models as Zero-Shot Time Series Forecastersby Long-Short-Term Prompt
UQI-LIUWJ
论文笔记论文阅读语言模型prompt
202402arxiv1intro1.1大模型+时间序列预测一般有两种类型的方法使用海量时间序列数据重新训练一个时间序列领域的大模型论文笔记:TimeGPT-1_timegpt论文-CSDN博客直接利用现有的大模型,设计prompt,将时间序列数据转换成大模型理解的文本,实现时间序列预测代价小+有成熟的可供使用的大模型1.2本文思路之前的方法大多集中在如何将时间序列数据转换成文本上将时间序列的数字
- 【论文笔记】ResNet论文的全面解析
浩瀚之水_csdn
#论文阅读笔记人工智能
论文:DeepResidualLearningforImageRecognition发表时间:2015发表作者:(MicrosoftResearch)He-Kaiming,Ren-Shaoqing,Sun-Jian论文链接:论文链接一、ResNet论文基本信息论文标题与发表信息论文标题:《DeepResidualLearningforImageRecognition》发表时间:2015年,并在20
- 论文笔记:TrafficPredict: Trajectory Prediction for Heterogeneous Traffic-Agents
CvBeginner
论文笔记轨迹预测计算机视觉
论文笔记:TrafficPredict:TrajectoryPredictionforHeterogeneousTraffic-Agents摘要这是百度在AAAI2019发布的一篇文章。这篇文章提出了一种基于4D-graph的方法实现复杂场景下的轨迹预测,研究对象包含行人、机动车和自行车。实现方法本文提出了一个基于LSTM的算法,名为TrafficPredict。构建了一个4DGraph,输入是轨
- 论文笔记:MobileNetV2: Inverted Residuals and Linear Bottlenecks
菜鸡信息技术
DeepLearning
MobileNetV2:InvertedResidualsandLinearBottlenecksMobileNetV2是MobileNetV1的改进版,Invertedresidual是个非常精妙的设计!MobileNetV1引入depthwiseseparableconvolution代替standardconvolution,减少运算量。MobileNetV1的结构其实非常简单,是类似于VG
- AIGC视频生成模型:ByteDance的PixelDance模型
好评笔记
AIGC深度学习人工智能计算机视觉机器学习transformer论文阅读
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍ByteDance的视频生成模型PixelDance,论文于2023年11月发布,模型上线于2024年9月,同时期上线的模型还有Seaweed(论文未发布)。热门专栏机器学习机器学习笔记合集深度学习深度学习笔记合集优质专栏回顾:机器学习笔记深度学习笔记多模态论文笔记AIGC—图像文章目录热门专栏机器学习深度学习
- Meta的AIGC视频生成模型——Emu Video
好评笔记
AIGC深度学习人工智能机器学习transformer校招面试八股
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍Meta的视频生成模型EmuVideo,作为Meta发布的第二款视频生成模型,在视频生成领域发挥关键作用。优质专栏回顾:机器学习笔记深度学习笔记多模态论文笔记AIGC—图像文章目录论文摘要引言相关工作文本到图像(T2I)扩散模型视频生成/预测文本到视频(T2V)生成分解生成方法预备知识EmuVideo生成步骤图
- [论文笔记] 超详细解读DeepSeek v3全论文技术报告
心心喵
论文笔记论文阅读
DeepSeek-V3是一个强大的专家混合(Mixture-of-Experts,MoE)语言模型,总共671B参数,每个token激活37B参数(可以理解为有多个专家,但每个token只会选择一部分专家进行推理,所以一个token的预测,只会用到37B参数),DeepSeek-V3使用了多头潜在注意力(
- [论文笔记] pai-megatron qwen1.5报错
心心喵
论文笔记python
Qwen1.5-0.5b-chat使用example中fintune.py报错·Issue#77·QwenLM/Qwen1.5·GitHub解决方案:transformers升级到4.37.0pipinstallsetuptools==65.5.1pipinstalltransformers==4.37.0
- 基于不确定性感知学习的单图像自监督3D人体网格重建 (论文笔记与思考)
Gamma and Beta
读博笔记算法笔记学习3d论文阅读
文章目录论文解决的问题提出的算法以及启发点论文解决的问题首先这是Self-Supervised3DHumanmeshrecoveryfromasingleimagewithuncertainty-awarelearning(AAAI2024)的论文笔记。该文中主要提出了一个自监督的framework用于人体的姿态恢复。主要是解决了现有的方法对大型数据集的依赖。提出的算法以及启发点论文总体的框架其实
- LLM论文笔记 28: Universal length generalization with Turing Programs
Zhouqi_Hua
大模型论文阅读论文阅读语言模型自然语言处理笔记人工智能
Arxiv日期:2024.10.4机构:HarvardUniversity关键词图灵机CoT长度泛化核心结论TuringPrograms的提出提出TuringPrograms,一种基于图灵机计算步骤的通用CoT策略。通过将算法任务分解为逐步的“磁带更新”(类似图灵机的读写操作),允许模型通过简单的文本复制与局部修改完成复杂计算通用性:适用于任何算法任务(加法、乘法、SGD),不依赖任务特定的数据格
- LLM论文笔记 27: Looped Transformers for Length Generalization
Zhouqi_Hua
大模型论文阅读论文阅读语言模型人工智能论文笔记笔记
Arxiv日期:2024.9.25关键词长度泛化transformer结构优化核心结论1.RASP-L限制transformer无法处理包含循环的任务的长度泛化2.LoopTransformer显著提升了长度泛化能力InputInjection显著提升了模型的长度泛化性能,尤其在二进制加法等复杂任务上效果显著在推理中,通过输出置信度判断迭代停止点的策略能够实现接近最佳的性能主要方法Transfor
- Fast-BEV:A Fast and Strong Bird’s-Eye View Perception Baseline——论文笔记
m_buddy
BEVPerception论文阅读人工智能深度学习
参考代码:Fast-BEV一稿多投的另一篇:Fast-BEV:TowardsReal-timeOn-vehicleBird’s-EyeViewPerception1.概述介绍:这篇文章提供了一种可实际部署的BEV感知方案,能够在当今车端主流计算单元上(NvidiaOrin)实现不错的帧率。从camera到BEV的转换思想来自于M2BEV,但是对这个转换方法中使用查找表和映射方法改进,使得整体视角转
- 读论文笔记-Flamingo:少样本视觉语言模型
joseanne_josie
论文阅读语言模型人工智能
读论文笔记-Flamingo:少样本视觉语言模型Plomblems本文拟解决多模态机器学习中,如何将训练好的模型快速适应到少量标注数据的新任务中的问题。Motivations已有的VLM虽然能在zero-shot的场景下适应于新任务,但他们只解决了有限的使用情况(如CLIP只解决了图片分类),由于主要缺乏生成语言的能力其不能应用于开放性任务。其他的一些方法虽然研究了基于视觉的语言生成但在数据量少的
- 论文笔记-基于多层感知器(MLP)的多变量桥式起重机自适应安全制动与距离预测
sagima_sdu
论文阅读
《IETCyber-SystemsandRobotics》出版山东大学TenglongZhang和GuoliangLiu团队的研究成果,文章题为“AdaptiveSafeBrakingandDistancePredictionforOverheadCranesWithMultivariationUsingMLP”。摘要桥式起重机的紧急制动及其制动距离预测是其安全运行中的关键难题。本文采用多层感知器
- 论文笔记:How Can Large Language Models Understand Spatial-Temporal Data?
UQI-LIUWJ
论文笔记论文阅读语言模型人工智能
arxiv2024011introLLM在NLP和CV领域表现出色,但将它们应用于时空预测任务仍然面临挑战,主要问题包括:数据不匹配传统的LLMs设计用于处理序列文本数据,而时空数据具有复杂的结构和动态性,这两者之间存在显著差异模型设计限制现有的时空预测方法通常需要为特定领域设计专门的模型,这限制了模型的通用性和适应性数据稀缺和泛化能力传统的时空预测方法在面对数据稀缺或稀疏的情况下表现不佳,且泛化
- SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks论文笔记
catbird233
深度生成模型笔记
另一篇很好的解释:https://www.itcodemonkey.com/article/6378.html摘要在自然语言生成领域,不同情感标签的生成越来越受到人们的关注。近年来,生成性对抗网(gan)在文本生成方面取得了良好的效果。然而,gan产生的文本通常存在质量差、缺乏多样性和模式崩溃的问题。本文提出了一个新的框架--sentyan,它有多个生成器和一个多类判别器,以解决上述问题。在我们的
- java数字签名三种方式
知了ing
javajdk
以下3钟数字签名都是基于jdk7的
1,RSA
String password="test";
// 1.初始化密钥
KeyPairGenerator keyPairGenerator = KeyPairGenerator.getInstance("RSA");
keyPairGenerator.initialize(51
- Hibernate学习笔记
caoyong
Hibernate
1>、Hibernate是数据访问层框架,是一个ORM(Object Relation Mapping)框架,作者为:Gavin King
2>、搭建Hibernate的开发环境
a>、添加jar包:
aa>、hibernatte开发包中/lib/required/所
- 设计模式之装饰器模式Decorator(结构型)
漂泊一剑客
Decorator
1. 概述
若你从事过面向对象开发,实现给一个类或对象增加行为,使用继承机制,这是所有面向对象语言的一个基本特性。如果已经存在的一个类缺少某些方法,或者须要给方法添加更多的功能(魅力),你也许会仅仅继承这个类来产生一个新类—这建立在额外的代码上。
- 读取磁盘文件txt,并输入String
一炮送你回车库
String
public static void main(String[] args) throws IOException {
String fileContent = readFileContent("d:/aaa.txt");
System.out.println(fileContent);
- js三级联动下拉框
3213213333332132
三级联动
//三级联动
省/直辖市<select id="province"></select>
市/省直辖<select id="city"></select>
县/区 <select id="area"></select>
- erlang之parse_transform编译选项的应用
616050468
parse_transform游戏服务器属性同步abstract_code
最近使用erlang重构了游戏服务器的所有代码,之前看过C++/lua写的服务器引擎代码,引擎实现了玩家属性自动同步给前端和增量更新玩家数据到数据库的功能,这也是现在很多游戏服务器的优化方向,在引擎层面去解决数据同步和数据持久化,数据发生变化了业务层不需要关心怎么去同步给前端。由于游戏过程中玩家每个业务中玩家数据更改的量其实是很少
- JAVA JSON的解析
darkranger
java
// {
// “Total”:“条数”,
// Code: 1,
//
// “PaymentItems”:[
// {
// “PaymentItemID”:”支款单ID”,
// “PaymentCode”:”支款单编号”,
// “PaymentTime”:”支款日期”,
// ”ContractNo”:”合同号”,
//
- POJ-1273-Drainage Ditches
aijuans
ACM_POJ
POJ-1273-Drainage Ditches
http://poj.org/problem?id=1273
基本的最大流,按LRJ的白书写的
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
#define INF 0x7fffffff
int ma
- 工作流Activiti5表的命名及含义
atongyeye
工作流Activiti
activiti5 - http://activiti.org/designer/update在线插件安装
activiti5一共23张表
Activiti的表都以ACT_开头。 第二部分是表示表的用途的两个字母标识。 用途也和服务的API对应。
ACT_RE_*: 'RE'表示repository。 这个前缀的表包含了流程定义和流程静态资源 (图片,规则,等等)。
A
- android的广播机制和广播的简单使用
百合不是茶
android广播机制广播的注册
Android广播机制简介 在Android中,有一些操作完成以后,会发送广播,比如说发出一条短信,或打出一个电话,如果某个程序接收了这个广播,就会做相应的处理。这个广播跟我们传统意义中的电台广播有些相似之处。之所以叫做广播,就是因为它只负责“说”而不管你“听不听”,也就是不管你接收方如何处理。另外,广播可以被不只一个应用程序所接收,当然也可能不被任何应
- Spring事务传播行为详解
bijian1013
javaspring事务传播行为
在service类前加上@Transactional,声明这个service所有方法需要事务管理。每一个业务方法开始时都会打开一个事务。
Spring默认情况下会对运行期例外(RunTimeException)进行事务回滚。这
- eidtplus operate
征客丶
eidtplus
开启列模式: Alt+C 鼠标选择 OR Alt+鼠标左键拖动
列模式替换或复制内容(多行):
右键-->格式-->填充所选内容-->选择相应操作
OR
Ctrl+Shift+V(复制多行数据,必须行数一致)
-------------------------------------------------------
- 【Kafka一】Kafka入门
bit1129
kafka
这篇文章来自Spark集成Kafka(http://bit1129.iteye.com/blog/2174765),这里把它单独取出来,作为Kafka的入门吧
下载Kafka
http://mirror.bit.edu.cn/apache/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz
2.10表示Scala的版本,而0.8.1.1表示Kafka
- Spring 事务实现机制
BlueSkator
spring代理事务
Spring是以代理的方式实现对事务的管理。我们在Action中所使用的Service对象,其实是代理对象的实例,并不是我们所写的Service对象实例。既然是两个不同的对象,那为什么我们在Action中可以象使用Service对象一样的使用代理对象呢?为了说明问题,假设有个Service类叫AService,它的Spring事务代理类为AProxyService,AService实现了一个接口
- bootstrap源码学习与示例:bootstrap-dropdown(转帖)
BreakingBad
bootstrapdropdown
bootstrap-dropdown组件是个烂东西,我读后的整体感觉。
一个下拉开菜单的设计:
<ul class="nav pull-right">
<li id="fat-menu" class="dropdown">
- 读《研磨设计模式》-代码笔记-中介者模式-Mediator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/*
* 中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。
* 中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
*
* 在我看来,Mediator模式是把多个对象(
- 常用代码记录
chenjunt3
UIExcelJ#
1、单据设置某行或某字段不能修改
//i是行号,"cash"是字段名称
getBillCardPanelWrapper().getBillCardPanel().getBillModel().setCellEditable(i, "cash", false);
//取得单据表体所有项用以上语句做循环就能设置整行了
getBillC
- 搜索引擎与工作流引擎
comsci
算法工作搜索引擎网络应用
最近在公司做和搜索有关的工作,(只是简单的应用开源工具集成到自己的产品中)工作流系统的进一步设计暂时放在一边了,偶然看到谷歌的研究员吴军写的数学之美系列中的搜索引擎与图论这篇文章中的介绍,我发现这样一个关系(仅仅是猜想)
-----搜索引擎和流程引擎的基础--都是图论,至少像在我在JWFD中引擎算法中用到的是自定义的广度优先
- oracle Health Monitor
daizj
oracleHealth Monitor
About Health Monitor
Beginning with Release 11g, Oracle Database includes a framework called Health Monitor for running diagnostic checks on the database.
About Health Monitor Checks
Health M
- JSON字符串转换为对象
dieslrae
javajson
作为前言,首先是要吐槽一下公司的脑残编译部署方式,web和core分开部署本来没什么问题,但是这丫居然不把json的包作为基础包而作为web的包,导致了core端不能使用,而且我们的core是可以当web来用的(不要在意这些细节),所以在core中处理json串就是个问题.没办法,跟编译那帮人也扯不清楚,只有自己写json的解析了.
- C语言学习八结构体,综合应用,学生管理系统
dcj3sjt126com
C语言
实现功能的代码:
# include <stdio.h>
# include <malloc.h>
struct Student
{
int age;
float score;
char name[100];
};
int main(void)
{
int len;
struct Student * pArr;
int i,
- vagrant学习笔记
dcj3sjt126com
vagrant
想了解多主机是如何定义和使用的, 所以又学习了一遍vagrant
1. vagrant virtualbox 下载安装
https://www.vagrantup.com/downloads.html
https://www.virtualbox.org/wiki/Downloads
查看安装在命令行输入vagrant
2.
- 14.性能优化-优化-软件配置优化
frank1234
软件配置性能优化
1.Tomcat线程池
修改tomcat的server.xml文件:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" maxThreads="1200" m
- 一个不错的shell 脚本教程 入门级
HarborChung
linuxshell
一个不错的shell 脚本教程 入门级
建立一个脚本 Linux中有好多中不同的shell,但是通常我们使用bash (bourne again shell) 进行shell编程,因为bash是免费的并且很容易使用。所以在本文中笔者所提供的脚本都是使用bash(但是在大多数情况下,这些脚本同样可以在 bash的大姐,bourne shell中运行)。 如同其他语言一样
- Spring4新特性——核心容器的其他改进
jinnianshilongnian
spring动态代理spring4依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- Linux设置tomcat开机启动
liuxingguome
tomcatlinux开机自启动
执行命令sudo gedit /etc/init.d/tomcat6
然后把以下英文部分复制过去。(注意第一句#!/bin/sh如果不写,就不是一个shell文件。然后将对应的jdk和tomcat换成你自己的目录就行了。
#!/bin/bash
#
# /etc/rc.d/init.d/tomcat
# init script for tomcat precesses
- 第13章 Ajax进阶(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Troubleshooting Crystal Reports off BW
blueoxygen
BO
http://wiki.sdn.sap.com/wiki/display/BOBJ/Troubleshooting+Crystal+Reports+off+BW#TroubleshootingCrystalReportsoffBW-TracingBOE
Quite useful, especially this part:
SAP BW connectivity
For t
- Java开发熟手该当心的11个错误
tomcat_oracle
javajvm多线程单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 正则表达式大全
yang852220741
html编程正则表达式
今天向大家分享正则表达式大全,它可以大提高你的工作效率
正则表达式也可以被当作是一门语言,当你学习一门新的编程语言的时候,他们是一个小的子语言。初看时觉得它没有任何的意义,但是很多时候,你不得不阅读一些教程,或文章来理解这些简单的描述模式。
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$