【计算机视觉——RCNN目标检测系列】二、边界框回归(Bounding-Box Regression)
前言
在上一篇博文:【计算机视觉——RCNN目标检测系列】一、选择性搜索详解我们重点介绍了RCNN和Fast RCNN中一个重要的模块——选择性搜索算法,该算法主要用于获取图像中大量的候选目标框。为了之后更加顺利理解RCNN模型,在这篇博文中我们将主要介绍RCNN及其改进版本——Fast RCNN和Faster RCNN中一个重要模块——边界框回归(Bounding-Box Regression)。
一、边界框回归简介
相比传统的图像分类,目标检测不仅要实现目标的分类,而且还要解决目标的定位问题,即获取目标在原始图像中的位置信息。在不管是最初版本的RCNN,还之后的改进版本——Fast RCNN和Faster RCNN都需要利用边界框回归来预测物体的目标检测框。因此掌握边界框回归(Bounding-Box Regression)是极其重要的,这是熟练使用RCNN系列模型的关键一步,也是代码实现中比较重要的一个模块。接下来,我们对边界框回归(Bounding-Box Regression)进行详细介绍。
首先我们对边界框回归的输入数据集进行说明。输入到边界框回归的数据集为 { ( P i , G i ) } i = 1 , ⋯ , N \left\{\left(P^{i}, G^{i}\right)\right\}_{i=1, \cdots, N} {(Pi,Gi)}i=1,⋯,N ,其中 P i = ( P x i , P y i , P w i , P h i ) P^{i}=\left(P_{x}^{i}, P_{y}^{i}, P_{w}^{i}, P_{h}^{i}\right) Pi=(Pxi,Pyi,Pwi,Phi), G i = ( G x i , G y i , G w i , G h i ) G^{i}=\left(G_{x}^{i}, G_{y}^{i}, G_{w}^{i}, G_{h}^{i}\right) Gi=(Gxi,Gyi,Gwi,Ghi) 。 P i P^{i} Pi 代表第 i i i个带预测的候选目标检测框即region proposal。 G i G^{i} Gi是 i i i个真实目标检测框即ground-truth。在RCNN和Fast RCNN中, P i P^{i} Pi 是利用选择性搜索算法进行获取;Faster RCNN中, P i P^{i} Pi 是利用RPN(Region Proposal Network,区域生成网络)获取。在 P i P^{i} Pi 中, P x i P_{x}^{i} Pxi 代表候选目标框的中心点在原始图像中的 x x x坐标, P y i P_{y}^{i} Pyi代表候选目标框的中心点在原始图像中的 y y y坐标, P w i P_{w}^{i} Pwi代表候选目标框的长度, P h i P_{h}^{i} Phi 代表候选目标框的宽度。 G i G^{i} Gi的四维特征的含义与 的一样。
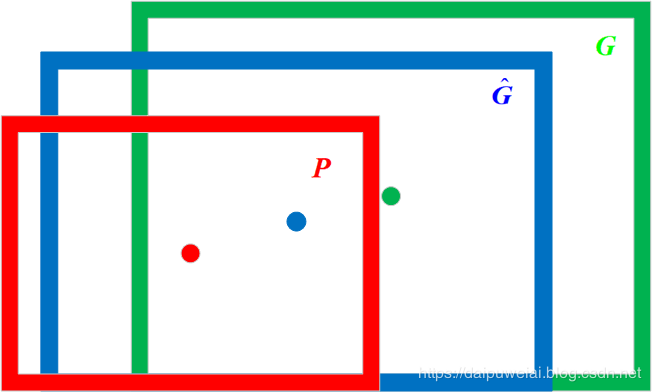
那么边界框回归所要做的就是利用某种映射关系,使得候选目标框(region proposal)的映射目标框无限接近于真实目标框(ground-truth)。将上述原理利用数学符号表示如下:在给定一组候选目标框 P = ( P x , P y , P w , P h ) P=\left(P_{x}, P_{y}, P_{w}, P_{h}\right) P=(Px,Py,Pw,Ph) ,寻找到一个映射 f f f ,使得 f ( P x , P y , P w , P h ) = ( G ^ x , G ^ y , G ^ w , G ^ h ) ≈ ( G x , G y , G w , G h ) f\left(P_{x}, P_{y}, P_{w}, P_{h}\right)=\left(\hat{G}_{x}, \hat{G}_{y}, \hat{G}_{w}, \hat{G}_{h}\right) \approx\left(G_{x}, G_{y}, G_{w}, G_{h}\right) f(Px,Py,Pw,Ph)=(G^x,G^y,G^w,G^h)≈(Gx,Gy,Gw,Gh) 。边界框回归过程图像表示如下图所示。在图1中红色框代表候选目标框,绿色框代表真实目标框,蓝色框代表边界框回归算法预测目标框,红色圆圈代表选候选目标框的中心点,绿色圆圈代表选真实目标框的中心点,蓝色圆圈代表选边界框回归算法预测目标框的中心点。
二、边界框回归细节
RCNN论文里指出,边界框回归是利用平移变换和尺度变换来实现映射 。平移变换的计算公式如下:
(1) { G ^ x = P w d x ( P ) + P x G ^ y = P h d y ( P ) + P y \left\{\begin{array}{l}{\hat{G}_{x}=P_{w} d_{x}(P)+P_{x}} \\ {\hat{G}_{y}=P_{h} d_{y}(P)+P_{y}}\end{array}\right.\tag1 {G^x=Pwdx(P)+PxG^y=Phdy(P)+Py(1)
尺度变换的计算公式如下:
(2) { G ^ w = P w exp ( d w ( P ) ) G ^ h = P h exp ( d w ( P ) ) \left\{\begin{array}{l}{\hat{G}_{w}=P_{w} \exp \left(d_{w}(P)\right)} \\ {\hat{G}_{h}=P_{h} \exp \left(d_{w}(P)\right)}\end{array}\right.\tag2 {G^w=Pwexp(dw(P))G^h=Phexp(dw(P))(2)
其中 d ∗ ( P ) d_{*}(P) d∗(P) ( ∗ * ∗ 代表 x , y , w , h x, y, w, h x,y,w,h),接下来要做的就是求解这4个变换。在边界框回归中,我们利用了线性回归在RCNN论文代表这AlexNet第5个池化层得到的特征即将送入全连接层的输入特征的线型函数。在这里,我们将特征记作 ϕ 5 ( P ) \phi_{5}(P) ϕ5(P),那么 d ∗ ( P ) = w ∗ T ϕ 5 ( P ) d_{*}(P)=w_{*}^{T} \phi_{5}(P) d∗(P)=w∗Tϕ5(P) 。因此,我们可以利用最小二乘法或者梯度下降算法进行求解 ,RCNN论文中给出了 的求解表达式:
(3) w ∗ = arg min w ^ ∗ ∑ i = 1 N ( t ∗ i − w ^ ∗ T ϕ 5 ( P i ) ) 2 + λ ∥ w ^ ∗ ∥ 2 w_{*}=\underset{\hat{w}_{*}}{\arg \min } \sum_{i=1}^{N}\left(t_{*}^{i}-\hat{w}_{*}^{T} \phi_{5}\left(P^{i}\right)\right)^{2}+\lambda\left\|\hat{w}_{*}\right\|^{2}\tag3 w∗=w^∗argmini=1∑N(t∗i−w^∗Tϕ5(Pi))2+λ∥w^∗∥2(3)
其中:
(4) { t x = G x − P x P w t y = G y − P y P h t w = log G w P w t x = log G h P h \left\{\begin{array}{l}{t_{x}=\frac{G_{x}-P_{x}}{P_{w}}} \\ {t_{y}=\frac{G_{y}-P_{y}}{P_{h}}} \\ {t_{w}=\log \frac{G_{w}}{P_{w}}} \\ {t_{x}=\log \frac{G_{h}}{P_{h}}}\end{array}\right.\tag4 ⎩⎪⎪⎪⎨⎪⎪⎪⎧tx=PwGx−Pxty=PhGy−Pytw=logPwGwtx=logPhGh(4)
可以看出,上述模型就是一个Ridge回归模型。在RCNN中,边界框回归要设计4个不同的Ridge回归模型分别求解 w x , w y , w w , w h w_{x}, w_{y}, w_{w}, w_{h} wx,wy,ww,wh。
三、相关问题
3.1 为什么使用相对坐标差?
在式(4)中 ,那么为什么要将真实框的中心坐标与候选框的中心坐标的差值分别除以宽高呢?首先我们假设两张尺寸不同,但内容相同的图像,图像如下图所示。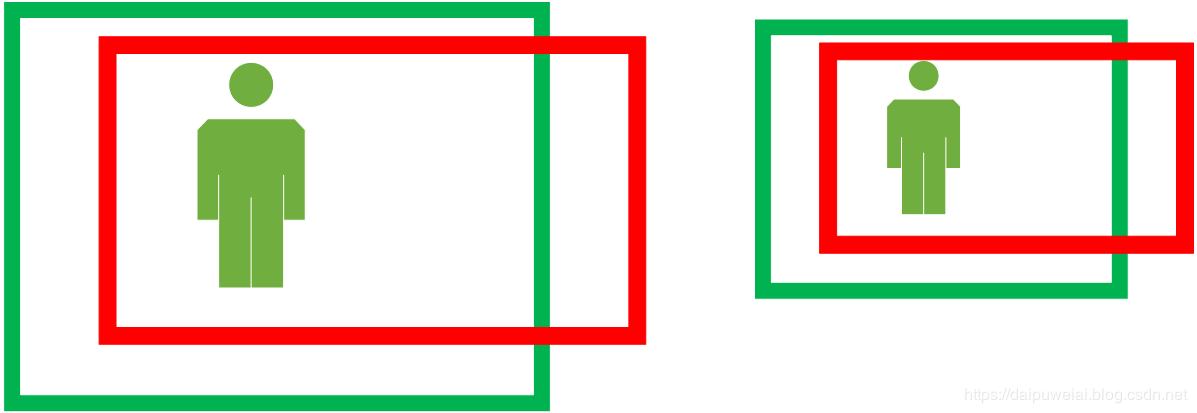
那么我们假设经过CNN提取得到的特征分别为 ϕ 1 \phi_{1} ϕ1 和 ϕ 2 \phi_{2} ϕ2 。同时,我们假设 x i x_{i} xi为第 i i i个真实目标框的 x x x坐标, p i p_{i} pi为第 i i i个候选目标框的 x x x坐标,边界框回归的映射关系为 f f f 。那么我们可以得出:
(5) { f ( ϕ 1 ) = x 1 − p 1 f ( ϕ 2 ) = x 2 − p 2 \left\{\begin{array}{l}{f\left(\phi_{1}\right)=x_{1}-p_{1}} \\ {f\left(\phi_{2}\right)=x_{2}-p_{2}}\end{array}\right.\tag5 {f(ϕ1)=x1−p1f(ϕ2)=x2−p2(5)
由于CNN具有尺度不变性,因此 ϕ 1 = ϕ 2 \phi_{1}=\phi_{2} ϕ1=ϕ2。那么理论上 x 1 − p 1 = x 2 − p 2 x_{1}-p_{1}=x_{2}-p_{2} x1−p1=x2−p2。但是观察上图就可明显得出 x 1 − p 1 ≠ x 2 − p 2 x_{1}-p_{1} \neq x_{2}-p_{2} x1−p1̸=x2−p2,显然由于尺寸的变化,候选目标框和真实目标框坐标之间的偏移量也随着尺寸而成比例缩放,即这个比例值是恒定不变的。
因此,我们必须对 x x x坐标的偏移量除以候选目标框的宽, y y y坐标的偏移量除以候选目标框的高。只有这样才能得到候选目标框与真实目标框之间坐标偏移量值的相对值。同时使用相对偏移量的好处可以自由选择输入图像的尺寸,使得模型灵活多变。也就说,对坐标偏移量除以宽高就是在做尺度归一化,即尺寸较大的目标框的坐标偏移量较大,尺寸较小的目标框的坐标偏移量较小。
3.2 为什么宽高比要取对数?
同时在式(4)中 t w = log G w P w , t x = log G h P h t_{w}=\log \frac{G_{w}}{P_{w}}, t_{x}=\log \frac{G_{h}}{P_{h}} tw=logPwGw,tx=logPhGh ,类比问题3.1,我们不禁要问为什么不直接使用宽高的比值作为目标进行学习,非得“多此一举”取对数?结合式(2)可以看出: t w = d w ( P ) , t h = d h ( P ) t_{w}=d_{w}(P), t_{h}=d_{h}(P) tw=dw(P),th=dh(P) 。也就说式(5)的后两个公式与式(2)可以视为等价。
3.3 为什么IoU较大时边界框回归可视为线性变换?
在这里我们需要回顾下在高等数学中有关等价无穷小的结论:
(6) lim x → 0 log ( 1 + x ) x = 1 \lim _{x \rightarrow 0} \frac{\log (1+x)}{x}=1\tag6 x→0limxlog(1+x)=1(6)
也就是说当 x x x趋向于0时,我们可有 log ( 1 + x ) ≈ x \log (1+x) \approx x log(1+x)≈x,即可将 log ( 1 + x ) \log (1+x) log(1+x) 近似看成线型变换。接下来我们将式(4)的后两个公式进行重写:
(7) { t w = log G w P w = log G w − P w + P w P w = log ( 1 + G w − P w P w ) t h = log G h P h = log G h − P h + P h P h = log ( 1 + G h − P h P h ) \left\{\begin{array}{l}{t_{w}=\log \frac{G_{w}}{P_{w}}=\log \frac{G_{w}-P_{w}+P_{w}}{P_{w}}=\log \left(1+\frac{G_{w}-P_{w}}{P_{w}}\right)} \\ {t_{h}=\log \frac{G_{h}}{P_{h}}=\log \frac{G_{h}-P_{h}+P_{h}}{P_{h}}=\log \left(1+\frac{G_{h}-P_{h}}{P_{h}}\right)}\end{array}\right.\tag7 ⎩⎨⎧tw=logPwGw=logPwGw−Pw+Pw=log(1+PwGw−Pw)th=logPhGh=logPhGh−Ph+Ph=log(1+PhGh−Ph)(7)
也就是说,当 G w − P w P w \frac{G_{w}-P_{w}}{P_{w}} PwGw−Pw 和 G h − P h P h \frac{G_{h}-P_{h}}{P_{h}} PhGh−Ph趋向于0时,即 G w ≈ P w G_{w} \approx P_{w} Gw≈Pw和 G h ≈ P h G_{h} \approx P_{h} Gh≈Ph时,上式(6)可以近似将对数变换看成线性变换。 G w ≈ P w G_{w} \approx P_{w} Gw≈Pw和 G h ≈ P h G_{h} \approx P_{h} Gh≈Ph时候选目标框和真实目标框非常接近,即IoU值较大。按照RCNN论文的说法,IoU大于0.6时,边界框回归可视为线型变换。