MTCNN-tensorflow源码解析-gen_landmark_aug_12.py;gen_imglist_pnet.py
gen_landmark_aug_12.py生成用于PNet网络的训练数据(用于人脸特征点)。此外对于RNet,ONet(用于人脸特征点)的训练数据生成与其类似,不再赘述。
主函数:
if __name__ == '__main__':
dstdir = "../../DATA/12/train_PNet_landmark_aug"
OUTPUT = '../../DATA/12'
data_path = '../../DATA'
if not exists(OUTPUT):
os.mkdir(OUTPUT)
if not exists(dstdir):
os.mkdir(dstdir)
assert (exists(dstdir) and exists(OUTPUT)) #检查条件,不符合就终止程序
net = "PNet"
names of all the landmark training data
train_txt = "trainImageList.txt" #TXT包含特征点定位训练的:人脸图像路径,特征点坐标
imgs,landmarks = GenerateData(train_txt,data_path,net,argument=True )trainImageList.txt存放的是每个图片中的人脸框坐标和对应的五个特征点坐标,因此我们知道一个完整的人脸有14个参数(2个角点坐标,5个特征点坐标)。例如:![]()
下面详细讲解GenerateData函数:
第一部分:
def GenerateData(ftxt,data_path,net,argument=False):
'''
:param ftxt: trainImageList.txt文件:包括 image path,bounding box, and landmarks
:param output: path of the output dir
:param net: 此处是PNet
:param argument: 数据扩充
:return: images and related landmarks
'''
if net == "PNet":
size = 12
elif net == "RNet":
size = 24
elif net == "ONet":
size = 48
else:
print('Net type error')
return
image_id = 0
f = open(join(OUTPUT,"landmark_%s_aug.txt" %(size)),'w') #OUTPUT = '../../DATA/12'
# 从trainImageList.txt文件中读取 image path , bounding box, and landmarks
data = getDataFromTxt(ftxt,data_path=data_path) #输出一个列表,列表中的元素是元组,每个元组(img_path, BBox(bbox), landmark)
idx = 0
#image_path bbox landmark(5*2)
for (imgPath, bbox, landmarkGt) in data:#landmarkGt是5*2数组,虽然用元组赋值,但还是数组类型
F_imgs = []
F_landmarks = []
img = cv2.imread(imgPath)
assert(img is not None)
img_h,img_w,img_c = img.shape
gt_box = np.array([bbox.left,bbox.top,bbox.right,bbox.bottom]) #人脸框坐标
f_face = img[bbox.top:bbox.bottom+1,bbox.left:bbox.right+1] #提取人脸图像
f_face = cv2.resize(f_face,(size,size)) #PNet是12,RNet是24,ONet是48
landmark = np.zeros((5, 2)) #初始化landmark
#归一化特征点坐标,原本图像的特征点坐标,转化为人脸图像下的坐标,实质是坐标轴的转化
for index, one in enumerate(landmarkGt): # landmakrGt 是5*2数组,one表示数组中的一行
# (( x - bbox.left)/ width , (y - bbox.top)/ height
rv = ((one[0]-gt_box[0])/(gt_box[2]-gt_box[0]), (one[1]-gt_box[1])/(gt_box[3]-gt_box[1]))
landmark[index] = rv
F_imgs.append(f_face)
F_landmarks.append(landmark.reshape(10))
landmark = np.zeros((5, 2)) #将特征点坐标转化到截取图像的坐标系中,并归一化,这一步得到的值就是特征点相对矩形框的偏移量:offset_landmark
rv = ((one[0]-gt_box[0])/(gt_box[2]-gt_box[0]), (one[1]-gt_box[1])/(gt_box[3]-gt_box[1]))
landmark[index] = rv
# (( x - bbox.left)/ width of bounding box, (y - bbox.top)/ height of bounding box
注意这里分母除以宽高
1、ftxt即输入的trainImageList.txt文件,保存了图片的路径,图片名,人脸框,特征点坐标,如上图所示;
- data_path存放我们下载的人脸数据集。我们会根据trainImageList.txt中的信息,从data_path路径中读取指定图像。
- net:对于不同的网络,输入尺寸不同,所以生成样本的尺寸也要重新与其相符合,PNet是12*12。
- join():连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串,这里的意思应该是在output路径下创建一个TXT文件landmark_%s_aug.txt" %(size),用于记录样本信息。
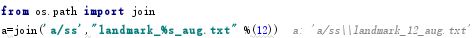
2、 data = getDataFromTxt(ftxt,data_path=data_path),调用了 getDataFromTxt函数,在BBox_utils.py文件中。
输出一个列表,列表中的元素是元组,每个元组(img_path, BBox(bbox), landmark)
- components[0]:代表文件名
- .replace('\\','/')把字符串中的(\\)替换成(/),主要是join函数拼接路径时产生的"\\"
- bbox = [float(_) for _ in bbox] ;bbox = list(map(int,bbox)) #参数元组转换为float,然后转化为整型
- result:将(图像名人脸框,特征点坐标)元组,存入result列表中
def getDataFromTxt(txt,data_path, with_landmark=True):
"""
Generate data from txt file
return [(img_path, bbox, landmark)]
bbox: [left, right, top, bottom]
landmark: [(x1, y1), (x2, y2), ...]
"""
with open(txt, 'r') as fd:
lines = fd.readlines()
result = []
for line in lines:
line = line.strip()
components = line.split(' ')
img_path = os.path.join(data_path, components[0]).replace('\\','/') # file path
# bounding box, (x1, y1, x2, y2)
#bbox = (components[1], components[2], components[3], components[4])
bbox = (components[1], components[3], components[2], components[4])
bbox = [float(_) for _ in bbox]
bbox = list(map(int,bbox))
# with_landmark=True,下式不运行
if not with_landmark:
result.append((img_path, BBox(bbox))) #存放元组类型
continue
landmark = np.zeros((5, 2))
for index in range(0, 5):
rv = (float(components[5+2*index]), float(components[5+2*index+1])) #人脸特征点坐标
landmark[index] = rv
result.append((img_path, BBox(bbox), landmark))#将人脸框,特征点坐标存入result
return result2.1、BBox类
class BBox(object):
def __init__(self, bbox):
self.left = bbox[0]
self.top = bbox[1]
self.right = bbox[2]
self.bottom = bbox[3]
self.x = bbox[0]
self.y = bbox[1]
self.w = bbox[2] - bbox[0]
self.h = bbox[3] - bbox[1]
。。。。。。。。
3、随后,遍历data中的数据,根据人脸框的位置。从原图中提取人脸图像f_face,存入F_img。并将特征点坐标转化为f_face下的坐标rv,转化为行向量存放在F_landmarks。返回值就是F_img和F_landmarks
注意:
landmark = np.zeros((5, 2))#5*2的数组
v=(0,1) #元组
landmark[0] = rv #把元组赋值给数组的第一行,赋值后还是数组
第二部分
下面一段用于数据扩充,即从人脸框附近crop多张图像,取iou较大的作为人脸图像,计算特征点坐标,再存入F_img和F_landmarks,方法与gen_12net_data.py中样本扩充方法类似https://blog.csdn.net/qq_30815237/article/details/95331109也有不同之处:
if argument: #数据扩展,方法与gen_12net_data相同
idx = idx + 1
if idx % 100 == 0:
print(idx, "images done")
x1, y1, x2, y2 = gt_box
gt_w = x2 - x1 + 1
gt_h = y2 - y1 + 1
if max(gt_w, gt_h) < 40 or x1 < 0 or y1 < 0:#忽略较小的人脸框
continue
#random shift
for i in range(10):
bbox_size = npr.randint(int(min(gt_w, gt_h) * 0.8), np.ceil(1.25 * max(gt_w, gt_h))) #初始化随机框的宽高
delta_x = npr.randint(-gt_w * 0.2, gt_w * 0.2) #偏移量
delta_y = npr.randint(-gt_h * 0.2, gt_h * 0.2)
nx1 = int(max(x1+gt_w/2-bbox_size/2+delta_x,0))
ny1 = int(max(y1+gt_h/2-bbox_size/2+delta_y,0))
nx2 = nx1 + bbox_size
ny2 = ny1 + bbox_size
if nx2 > img_w or ny2 > img_h:
continue
crop_box = np.array([nx1,ny1,nx2,ny2])
cropped_im = img[ny1:ny2+1,nx1:nx2+1,:] #根据随机生成的矩形框crop原图像,在人脸附近随机生成的人脸框
resized_im = cv2.resize(cropped_im, (size, size))
#cal iou
iou = IoU(crop_box, np.expand_dims(gt_box,0))
if iou > 0.65:
F_imgs.append(resized_im) #iou满足条件,则将该人脸框作为样本存入F_imgs
for index, one in enumerate(landmarkGt): #同样的,我们需要将原图像的特征点坐标,转化为当前人脸图像下的坐标
rv = ((one[0]-nx1)/bbox_size, (one[1]-ny1)/bbox_size)
landmark[index] = rv
F_landmarks.append(landmark.reshape(10)) #将转换后的5个点的坐标保存
landmark = np.zeros((5, 2))
landmark_ = F_landmarks[-1].reshape(-1,2) #取T_landmark最后一组特征点,转换成 n行2列
bbox = BBox([nx1,ny1,nx2,ny2]) #封装成一个类,这个坐标依然是原图像坐标系下的坐标
#生成图像镜像
if random.choice([0,1]) > 0:
face_flipped, landmark_flipped = flip(resized_im, landmark_)#对图像进行水平镜像,对于特征点:第一行和第二行互换,第四行和第五行互换,即左右眼,左右嘴角互换
face_flipped = cv2.resize(face_flipped, (size, size))
#c*h*w
F_imgs.append(face_flipped)
F_landmarks.append(landmark_flipped.reshape(10)) #将镜像图像和特征点,作为样本存入F_imgs, F_landmarks
#图像旋转
if random.choice([0,1]) > 0:
face_rotated_by_alpha, landmark_rotated = rotate(img, bbox, \
bbox.reprojectLandmark(landmark_), 5)#逆时针旋转,注意这里是对整张原图像进行操作
#landmark_offset
landmark_rotated = bbox.projectLandmark(landmark_rotated)
face_rotated_by_alpha = cv2.resize(face_rotated_by_alpha, (size, size))
F_imgs.append(face_rotated_by_alpha)
F_landmarks.append(landmark_rotated.reshape(10))
#再求旋转后的图像的镜像,作为样本
face_flipped, landmark_flipped = flip(face_rotated_by_alpha, landmark_rotated)
face_flipped = cv2.resize(face_flipped, (size, size))
F_imgs.append(face_flipped)
F_landmarks.append(landmark_flipped.reshape(10))
#反方向旋转
if random.choice([0,1]) > 0:
face_rotated_by_alpha, landmark_rotated = rotate(img, bbox, \
bbox.reprojectLandmark(landmark_), -5)#顺时针旋转
landmark_rotated = bbox.projectLandmark(landmark_rotated)
face_rotated_by_alpha = cv2.resize(face_rotated_by_alpha, (size, size))
F_imgs.append(face_rotated_by_alpha)
F_landmarks.append(landmark_rotated.reshape(10))
#对旋转后的图像进行镜像
face_flipped, landmark_flipped = flip(face_rotated_by_alpha, landmark_rotated)
face_flipped = cv2.resize(face_flipped, (size, size))
F_imgs.append(face_flipped)
F_landmarks.append(landmark_flipped.reshape(10))
F_imgs, F_landmarks = np.asarray(F_imgs), np.asarray(F_landmarks)
for i in range(len(F_imgs)):
if np.sum(np.where(F_landmarks[i] <= 0, 1, 0)) > 0: #看不懂
continue
if np.sum(np.where(F_landmarks[i] >= 1, 1, 0)) > 0:
continue
cv2.imwrite(join(dstdir,"%d.jpg" %(image_id)), F_imgs[i]) #将提取到的人脸样本图像保存
landmarks = map(str,list(F_landmarks[i])) #
f.write(join(dstdir,"%d.jpg" %(image_id))+" -2 "+" ".join(landmarks)+"\n")#将图像路径,图像名,label,特征点坐标写入txt 文件中
image_id = image_id + 11、在样本扩展中,主要使用镜像图像,旋转图像2种方法:flip函数,看不懂它的意思,这种方法最后得到坐标是负值
def flip(face, landmark):
face_flipped_by_x = cv2.flip(face, 1)
landmark_ = np.asarray([(1-x, y) for (x, y) in landmark])#(以x=0.5为轴翻折)这一步的意义是什么
landmark_[[0, 1]] = landmark_[[1, 0]]#left eye<->right eye
landmark_[[3, 4]] = landmark_[[4, 3]]#left mouth<->right mouth
return (face_flipped_by_x, landmark_)2、rotate函数:
def rotate(img, bbox, landmark, alpha):
center = ((bbox.left+bbox.right)/2, (bbox.top+bbox.bottom)/2) #矩形框中心的
rot_mat = cv2.getRotationMatrix2D(center, alpha, 1)
#pay attention: 3rd param(col*row)
img_rotated_by_alpha = cv2.warpAffine(img, rot_mat,(img.shape[1],img.shape[0]))#对整幅图像进行旋转
landmark_ = np.asarray([(rot_mat[0][0]*x+rot_mat[0][1]*y+rot_mat[0][2],
rot_mat[1][0]*x+rot_mat[1][1]*y+rot_mat[1][2]) for (x, y) in landmark])
#crop face
face = img_rotated_by_alpha[bbox.top:bbox.bottom+1,bbox.left:bbox.right+1] #图像旋转了,但是矩形框还是原来的矩形框,所以我们得到一个倾斜的人脸样本
return (face, landmark_)3、cv2.imwrite(join(dstdir,"%d.jpg" %(image_id)),F_imgs[i]) #将截取区域存入../../DATA/12/train_PNet_landmark_aug文件中
landmarks = map(str,list(F_landmarks[i]))
f.write(join(dstdir,"%d.jpg" %(image_id))+" -2 "+" ".join(landmarks)+"\n") #将图像名,label(-2),特征点坐标存入trainImageList.txt文件中。

注意:训练样本中landmark的10个值,并不是真实的特征点坐标,二是特征点坐标相对于边界框的偏移量。
gen_imglist_pnet.py用于将人脸检测的训练样本与人脸特征点训练样本合并。
1、读取图像
with open(os.path.join(data_dir, '%s/pos_%s.txt' % (size, size)), 'r') as f:
pos = f.readlines()
with open(os.path.join(data_dir, '%s/neg_%s.txt' % (size, size)), 'r') as f:
neg = f.readlines()
with open(os.path.join(data_dir, '%s/part_%s.txt' % (size, size)), 'r') as f: #读取用于人脸检测的图像信息
part = f.readlines()
with open(os.path.join(data_dir,'%s/landmark_%s_aug.txt' %(size,size)), 'r') as f: #读取用于人脸特征点定位的图像信息
landmark = f.readlines()2、创建路径,TXT文件
dir_path = os.path.join(data_dir, 'imglists')
if not os.path.exists(dir_path):
os.makedirs(dir_path)
if not os.path.exists(os.path.join(dir_path, "%s" %(net))):
os.makedirs(os.path.join(dir_path, "%s" %(net)))3、将检测人脸的训练样本的TXT信息和特征点人脸训练样本的TXT信息写入train_PNet_landmark.txt中。
- 在训练PNet时,将四个部分的数据(pos,part,landmark,neg)合并为一个tfrecord,因为它们的比例1:1:1:3。
- neg_keep = npr.choice(len(neg), size=len(neg), replace=True) :当len(neg)不满75000,时,采用重复输出,使得样本数输出75000
- pos_keep = npr.choice(len(pos), size=base_num, replace=True):当len(pos)>25000,正类样本选择25000个作为训练样本,因此,否则重复输出个别样本,使得最终还是有25000个样本。
![]()
with open(os.path.join(dir_path, "%s" %(net),"train_%s_landmark.txt" % (net)), "w") as f:#创建路径,写入TXT文件
nums = [len(neg), len(pos), len(part)]
ratio = [3, 1, 1]
#base_num = min(nums)
base_num = 250000
# print(len(neg), len(pos), len(part), base_num)
#shuffle the order of the initial data
#if negative examples are more than 750k then only choose 750k
if len(neg) > base_num * 3:
neg_keep = npr.choice(len(neg), size=base_num * 3, replace=True) #选择75000个样本进行输出
else:
neg_keep = npr.choice(len(neg), size=len(neg), replace=True)#不够75000个样本
pos_keep = npr.choice(len(pos), size=base_num, replace=True)
part_keep = npr.choice(len(part), size=base_num, replace=True)
print(len(neg_keep), len(pos_keep), len(part_keep))
# write the data according to the shuffled order
for i in pos_keep:
f.write(pos[i])
for i in neg_keep:
f.write(neg[i])
for i in part_keep:
f.write(part[i])
for item in landmark:#图像名,人脸框,人脸特征点坐标
f.write(item)
面部轮廓关键点回归值
人脸的面部轮廓关键点不采用绝对坐标,同样使用的是回归值,不过该回归值对应的是Bounding Box的相对坐标,如下所示:
相应的计算公式如下所示:
offsetX=(lx-x)/bbox_width
offsetY=(ly-y)/bbox_height
对所有的landmark点计算offset后生成如下数据:
train_PNet_landmark/0.jpg -2 0.288961038961 0.204545454545 0.814935064935 0.262987012987 0.535714285714 0.659090909091 0.275974025974 0.853896103896 0.724025974026 0.905844155844
train_PNet_landmark/1.jpg -2 0.42816091954 0.215517241379 0.89367816092 0.26724137931 0.646551724138 0.617816091954 0.416666666667 0.790229885057 0.813218390805 0.836206896552
train_PNet_landmark/2.jpg -2 0.153125 0.271875 0.659375 0.328125 0.390625 0.709375 0.140625 0.896875 0.571875 0.946875
train_PNet_landmark/3.jpg -2 0.174327367914 0.242510936232 0.673748423293 0.342669482766 0.372792971258 0.69904560555 0.10740259497 0.864043175755 0.532653771385 0.95143882472
面部轮廓关键点生成:生成方法类似于回归框的方式,在guarand true landmark点上加上一个随机偏移量,然后再计算offset值
from:https://blog.csdn.net/wfei101/article/details/80372939