【论文学习】SqueezeNet
SqueezeNet于2016年提出,其主要目的是在保证当时已有的模型准确度的同时减少CNN模型中的参数。原文地址:SqueezeNet:AlexNet-Level accuracy with 50X fewer parameters and <0.5MB model size
1. Abstract
在深度卷积神经网络的研究主要的关注点是提升其准确度。在给定准确度水平的条件下,通常可以识别多个达到该精度级别的CNN体系架构。在同等精度条件下,较小的CNN架构至少有三个优点:
(1) 在分布式训练中小模型在服务器中的通信量更少,分布式训练更加高效,因为在服务器间的通信是分布式CNN训练的可扩展性的限制因素。
(2) 便于模型的更新,在从云端导入到客户端时需求带宽更少
(3) 小模型部署在FPGA硬件上更灵活,因为这些硬件内存有限。因为FPGA通常来讲片上存储器少于10MB,并且不具有片外存储器或储存器。
作者提出具备以上优点的小型模型:SqueezeNet。SqueezeNet在ImageNet数据集上实现了和AlexNet相当的准确度,但是少了50倍的参数。而且,SqueezeNet也采用了模型压缩的方法,这样就可以把SqueezeNet压缩至0.5MB以下,这比AlexNet小了510倍。作者定义了CNN microarchitecture(CNN微观架构)和CNN macroarchitecture(CNN宏观架构)两个概念,分别从单个图层和模块的组织和维度以及多个模块的系统级组织整合为端到端CNN架构两个角度对SqueezeNet进行深究。
2. Motivation
作者采用模型压缩的方法。模型压缩中一个相当直接的方法就是采用奇异值分解(singular value decomposition,SVD)来预训练CNN模型,以此产生网络剪枝(Network Pruning)。网络剪枝主要是在预训练模型的基础上,设定一个阈值,低于阈值设为0,从而形成一个稀疏矩阵,最终在稀疏CNN上进行训练。后来作者把网络剪枝和量化(8 bits或者更少)以及哈夫曼编码结合起来,称为深度压缩(Deep Compression)。
设计深层次的CNN主要为了提升网络的准确度,当然也是现在的一种趋势,只是为每个层手动选择卷积核比较笨重。为了解决这个问题,已经提出了各种更高级别的building blocks或者module,其由具有特定固定组织的多个卷积层组成。比如GoogleNet提出了Inception modules,由众多不同维度的卷积核组成,通常是1*1和3*3,而且也有一些5*5、1*3、3*1的卷积核。
近期在CNN宏观架构中讨论最多的研究最多的是网络深度(depth)。VGG中有12-19层,而且也说明在ImageNet-1k数据集上网络越深,准确度越高。在多个层或module之间的连接方式是CNN宏观架构中的一个研究的新兴领域。Residual Networks(ResNet)和Highway Networks均提出了跳过多个层的连接方式。这种方式称为bypass connection。
神经网络(Neural networks,NN)有很大的设计空间,在微观架构、宏观架构、解决方式以及其他超参数都有很多选择。许多在神经网络设计空间探索(design space exploration,DSE)的工作主要关注在找到能够生成高准确度的神经网络架构的自动化方法。这些自动化DSE方法包括bayesian optimization(Snoek et al., 2012)、simulated annealing(Ludermir et al., 2006))、randomized search(Bergstra & Bengio, 2012)和genetic algorithm(Stanley & Miikkulainen, 2002)。这些论文中提出过DSE方法生成NN架构高准确的实例。但是这些论文中并没有给出NN设计空间的直观理解。
3. Design
作者设计SqueezeNet主要是建立在Fire module上。Fire module是作者引入的一种建立CNN架构的新building block。
3.1 设计策略
1、 用1*1卷积核替代3*3卷积核。在一定卷积核数目的限制下,大量使用1*1卷积核,这样比3*3的卷积核参数少9倍
2、 减少3*3卷积核的输入通道数目。如果考虑一个都是3*3卷积核的卷积层,在这个层中的所有参数量是:(输入通道数)*(卷积核数目)*3*3。使用squeeze layers减少3*3卷积核的输入通道数目。
3、 延迟网络中的下采样以便于卷积层有较大的activation maps(文中是activation map,其实是feature map)。在ShuffleNet的论文中也有这个观点,较大的特征图可以提升准确度。在一个卷积网络中,每一个卷积层都会输出特定空间分辨率的activation map。这些activation map的高度和宽度由以下因素控制:输入数据的大小(比如256*256的输入图片)和CNN架构中下采样的层。通常CNN架构中下采样一般在一些卷积层或者池化层中的stride>1。如果网络中的大多数层stride为1,stride>1的层主要连接网络的classifier,那么网络中的许多层都会有较大的activation map。实验证明延迟下采样可以有较高的分类准确率。
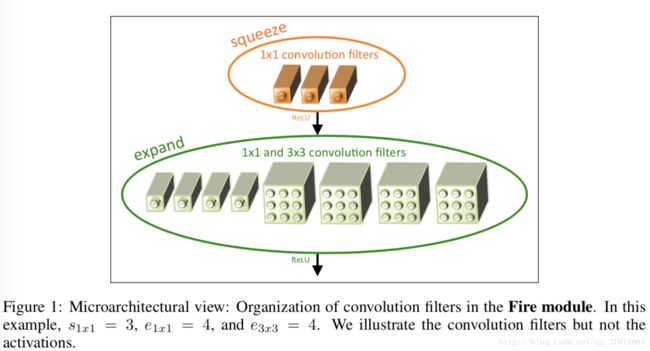
3.2 Fire Module
Fire module是SqueezeNet设计的核心。一个Fire module由以下组成:一个squeeze layer(只有1*1卷积核)、一个expand layer(由1*1和3*3卷积核组合而成)。图1中有显示。很明显squeeze layer经ReLU连接expand layer,expand layer后也紧接ReLU。在一个Fire module中有三个超参数:s1*1、e1*1、e3*3。s1*1是squeeze layer中的卷积核数目,e1*1是expand layer中1*1卷积核的数目,e3*3是expand layer中3*3卷积核数目。若设置s1*1小于(e1*1+e3*3),那么squeeze layer就限制了3*3卷积核的输入通道数目。
SqueezeNet的CNN架构如图2中Left,Middle是简单bypass的SqueezeNet,Right是复杂bypass的SqueezeNet。没有bypass的SqueezeNet由一个独立卷积层(conv1)开始,紧跟8个Fire module(fire2-9),也以一个卷积层(conv10)结束。网络中每个Fire module逐渐增加卷积核的数目,在conv1、fire4、fire8和conv10之后有一个stride为2的max-pooling层。

表1是完整的SqueezeNet架构。

SqueezeNet用到了dropout,值为50%,在fire9之后;在SqueezeNet中没有使用FC layers;训练SqueezeNet时,learning rate初始值是0.04,线性减少;在实现时使用Caffe框架,用两个独立的卷积层实现expand layer:一个1*1卷积核的层,一个3*3卷积核的层,然后把这些层的输出在通道维度上串联在一起。
4. Experiment
在评估SqueezeNet的性能的时候,作者使用AlexNet和相关的模型压缩结果作为比较基础。表2中是当时的一些模型压缩结果。从表中可以看出,SVD的方法能在把一个预训练的AlexNet模型压缩5倍的同时实现56.0%的top-1准确度。网络剪枝在ImageNet上实现了57.2%的top-1准确度和80.3%的top-5准确度,模型大小减小了9倍。深度压缩在保证基础的准确度水平的同时模型大小减小了35倍。而SqueezeNet与AlexNet模型相比缩小了50倍,top-1准确度较高(57.5%),top-5准确度相同(80.3%)。量化的深度压缩方法在保证准确度的同时也使模型大小减少很多。在深度压缩中用到了codebook技术,可把CNN参数优化为6 bits或8 bits精度。采用6 bits的压缩,SqueezeNet模型大小压缩了510倍,降到了0.47MB。对参数降低位数,比如从float32变成int8,训练时采用高位浮点是为了梯度计算,而真正做inference时也许并不需要这么高位的浮点。

作者定义metaparameters控制在一个CNN中的所有Fire module的维度,然后从CNN微观架构评测SqueezeNet。basee是第一个Fire module中expand filters的数目;每freq个Fire modules,expand filters增加incre,因而Fire module i,expand filers个数:

ei=ei,1*1+ei,3*3,定义pct3*3是expand filters中3*3卷积核的比例,则ei,3*3=ei*pct3*3,ei,1*1=ei*(1-pct3*3);squeeze ratio(SR)为一个Fire module中的squeeze layer中的卷积核比例,所有的Fire module中都相同,则si,1*1=SR*ei。这些都是metaparameter。SqueezeNet中,这些值如下:
basee=incre=128,pct3*3=0.5,freq=2,SR=0.125。
图3(a)是改变SR的值,比较模型大小和准确度;图3(b)是改变pct3*3的值,比较模型大小和准确度,来探究CNN中卷积核维度的作用。因为改变pct3*3就间接地改变了1*1卷积核和3*3卷积核的数目。

如图2的Middle和Right所示,是采用bypass connection的SqueezeNet。通过比较不同bypass connection的SqueezeNet来评测其在CNN宏观架构的性能。采用bypass connection的一个限制是输入通道和输出通道的数目要一致,因而只有一半的Fire module可以采用简单bypass connection。如果不能满足这个要求,作者定义了复杂 bypass connection,就是在每个bypass都有一个1*1卷积层,这种卷积层中的卷积核数目等于输出通道数目。显然复杂bypass connection需要额外的参数,而简单bypass connection没有。
增加bypass connection缓和了squeeze layer引入的bottleneck。因为squeeze layer减少了8倍的输出通道,在squeeze layer之间的信息交流就减少了,但是bypass connection为squeeze layer之间的信息交流增加了新的通道。
从表3中看出,简单bypass connection准确度比复杂的要高,模型大小也没有增加。

5. Analysis
SqueezeNet是2016年提出的,结合了小模型的研究思路:结构优化和模型压缩。论文中的很多思想都在之后的论文中有用到,比如较大的特征图可以提升准确度,特征图间的信息交流也可以提升准确度等等。论文探究了卷积核维度在提升网络模型准确度的作用,实验证明1*1卷积核和3*3卷积核比例相同时使小模型的模型大小和准确度的折中较好。1*1卷积核主要是减小模型尺寸,而3*3卷积核维持其准确度。在实验中的一些trick也很有代表性,比如定义pct3*3。