tensorflow学习(3):解读mnist_experts例子,训练保存模型并tensorboard可视化
前言
官网的mnist例子讲解的很清楚了,要想深入理解这个网络结构到底干了什么,还是需要好好入门一下深度学习的基础知识。好好看看Michael Nielsen大神写的这本书:Neural Networks and Deep Learning,中文版下载地址:中文版pdf。
本文讲解mnist_experts例子并结合tensorflow的常用操作(tensorboard可视化和Saver保存模型)来改写mnist例子,丰富例子的功能。
开始之前,你应该了解一下mnist数据集,详见博客:mnist解读
正文
一、首先来看一眼例子的网络结构和改写后的源代码

# encoding=utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
myGraph = tf.Graph()
with myGraph.as_default():
with tf.name_scope('inputsAndLabels'):
x_raw = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
with tf.name_scope('hidden1'):
x = tf.reshape(x_raw, shape=[-1,28,28,1])
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
l_conv1 = tf.nn.relu(tf.nn.conv2d(x,W_conv1, strides=[1,1,1,1],padding='SAME') + b_conv1)
l_pool1 = tf.nn.max_pool(l_conv1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
tf.summary.image('x_input',x,max_outputs=10)
tf.summary.histogram('W_con1',W_conv1)
tf.summary.histogram('b_con1',b_conv1)
with tf.name_scope('hidden2'):
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
l_conv2 = tf.nn.relu(tf.nn.conv2d(l_pool1, W_conv2, strides=[1,1,1,1], padding='SAME')+b_conv2)
l_pool2 = tf.nn.max_pool(l_conv2, ksize=[1,2,2,1],strides=[1,2,2,1], padding='SAME')
tf.summary.histogram('W_con2', W_conv2)
tf.summary.histogram('b_con2', b_conv2)
with tf.name_scope('fc1'):
W_fc1 = weight_variable([64*7*7, 1024])
b_fc1 = bias_variable([1024])
l_pool2_flat = tf.reshape(l_pool2, [-1, 64*7*7])
l_fc1 = tf.nn.relu(tf.matmul(l_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
l_fc1_drop = tf.nn.dropout(l_fc1, keep_prob)
tf.summary.histogram('W_fc1', W_fc1)
tf.summary.histogram('b_fc1', b_fc1)
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(l_fc1_drop, W_fc2) + b_fc2
tf.summary.histogram('W_fc1', W_fc1)
tf.summary.histogram('b_fc1', b_fc1)
with tf.name_scope('train'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_conv, labels=y))
train_step = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('loss', cross_entropy)
tf.summary.scalar('accuracy', accuracy)
with tf.Session(graph=myGraph) as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('./mnistEven/', graph=sess.graph)
for i in range(10001):
batch = mnist.train.next_batch(50)
sess.run(train_step,feed_dict={x_raw:batch[0], y:batch[1], keep_prob:0.5})
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x_raw:batch[0], y:batch[1], keep_prob:1.0})
print('step %d training accuracy:%g'%(i, train_accuracy))
summary = sess.run(merged,feed_dict={x_raw:batch[0], y:batch[1], keep_prob:1.0})
summary_writer.add_summary(summary,i)
test_accuracy = accuracy.eval(feed_dict={x_raw:mnist.test.images, y:mnist.test.labels, keep_prob:1.0})
print('test accuracy:%g' %test_accuracy)
saver.save(sess,save_path='./model/mnistmodel',global_step=1)二、网络结构
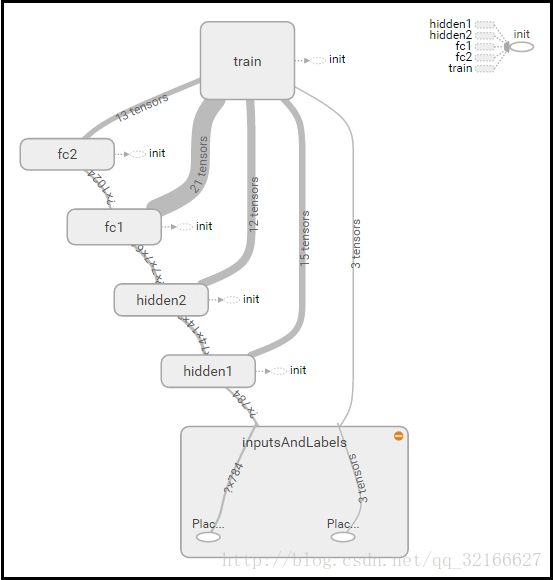
由上面的结构图可以看出,输入图像先经过2个conv-pooling层,然后进入一个全连接层,最后经过softmax层输出结果。这些层的作用都在前言中推荐的书中讲的很详细。
三、tensorboard可视化
tensorflow提供了一套可视化的工具,就是tensorboard,它可以帮你绘制计算图,还可以记录训练过程中参数的变化情况并绘制成变化图,其使用会用到tf.summary.xxx这些API。首先在构建计算图的时候一个变量一个变量搜集,构建完后将这些变量合并然后在训练过程中写入到event文件中。
为了计算图看着简洁,一般将每一层定义到一个名称空间中,如下所示:
with tf.name_scope('hidden1'):
x = tf.reshape(x_raw, shape=[-1,28,28,1])
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])那么,W/b变量被名称空间包含后,绘制出的计算图会有一个名为“hidden1”的方块,点开方块后能看到里面的变量。
然后记录变量,不同的变量有不同的记录方法。
1,对于损失函数和准确率这样的单值变量,用tf.summary.scalar()来搜集
cross_entropy = tf.reduce_mean(xxx(logits=y_conv, labels=y))
train_step = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cross_entropy)
tf.summary.scalar('loss', cross_entropy)
tf.summary.scalar('accuracy', accuracy)2,对于W和b这样的高维变量,用tf.summary.histogram()来搜集
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(l_fc1_drop, W_fc2) + b_fc2
tf.summary.histogram('W_fc1', W_fc1)
tf.summary.histogram('b_fc1', b_fc1)3,常用的是上面2个,也可以用tf.summary.image()来搜集出入图片,这样能看到输入的图片是什么样的
with tf.name_scope('hidden1'):
x = tf.reshape(x_raw, shape=[-1,28,28,1])
tf.summary.image('x_input',x,max_outputs=10) 搜集完变量后就可以在训练过程中合并并写入到event文件啦
with tf.Session(graph=myGraph) as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
merged = tf.summary.merge_all() #合并
summary_writer = tf.summary.FileWriter('./mnistEven/', graph=sess.graph) #文件写路径
for i in range(10001):
batch = mnist.train.next_batch(50)
sess.run(train_step,feed_dict={x_raw:batch[0], y:batch[1], keep_prob:0.5})
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x_raw:batch[0], y:batch[1], keep_prob:1.0})
print('step %d training accuracy:%g'%(i, train_accuracy))
summary=sess.run(merged,feed_dict={x_raw:batch[0], y:batch[1], keep_prob:1.0})#计算变量
summary_writer.add_summary(summary,i) # 每100步,将所有搜集的写文件训练完成后,运行下面的命令
$ tensorboard --logdir=path/to/log-directory再通过浏览器输入地址:”localhost:6006”,来看tensorboard。
下面的图就是计算图和搜集到的参数:
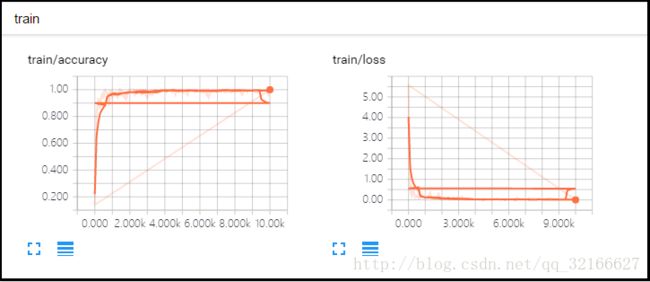

总之,tensorboard可以可视化训练过程。
四,Saver保存训练模型
保存模型比较简单,首先在训练之前定义一个saver,训练结束后调用saver.save()即可。
with tf.Session(graph=myGraph) as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
for i in range(10001):
#循环里面是训练的过程
saver.save(sess,save_path='./model/mnistmodel',global_step=1)保存模型其实是保存了模型中的参数,主要是权重W和偏置b。保存到指定的目录下的是二进制文件,我们可以重构了网络之后,直接从这些文件中restore参数,就可以直接使用啦。
下一章详细介绍如何restore模型并创建一个识别引擎,用来识别一张带有数字的图片。点击进入博客