加法器的verilog实现(串行进位、并联、超前进位、流水线)
总结:
从下面的Timing summary来看,流水线的频率最高、并行加法器次之,串行进位加法器再次,超前进位加法器最慢。
按理论,超前进位加法器应该比串行进位加法器快,此处为何出现这种情况,原因未知。
并行加法器因为使用加法符号实现的,从RTL图上也可以看到,具体是用加法器实现的,这个加法器是经过优化的,因此速度比较快。
流水线因为减小了组合逻辑的延时,因此可以达到较高的运行频率(注意运行速度与响应速度是不同的概念)。具体是通过缓存中间结果,从而分割组合逻辑实现流水线的。
相应地,串行进位加法器组合逻辑时延较大,因此速度较慢。
资源占用因为涉及到不同类型资源的比较,不较复杂,此处不再分析。
注意几点:
- 有符号数的加法,要进行符号位扩展;
- 对流水线加法,注意最后一级是符号扩展,前几级是0扩展;
代码以及综合结果如下。
8bit级联(即串行进位)加法器:

1 module adder_serial(rst_n,
2 clk,
3 a,
4 b,
5 cin,
6 sum
7 );
8
9 parameter DATA_SIZE = 8;
10
11 input rst_n;
12 input clk;
13 input [DATA_SIZE - 1 : 0] a;
14 input [DATA_SIZE - 1 : 0] b;
15 input cin;
16
17 output [DATA_SIZE : 0] sum;
18
19 reg [DATA_SIZE - 1 : 0] a_r;
20 reg [DATA_SIZE - 1 : 0] b_r;
21 reg cin_r;
22
23 wire [DATA_SIZE : 0] sum_tmp;
24 wire [DATA_SIZE - 1 : 0] cout_tmp;
25
26 reg [DATA_SIZE : 0] sum;
27
28 always@(posedge clk)
29 if(!rst_n)
30 begin
31 a_r <= 8'd0;
32 b_r <= 8'd0;
33 cin_r <= 1'b0;
34 end
35 else
36 begin
37 a_r <= a;
38 b_r <= b;
39 cin_r <= cin;
40 end
41 //级联加法器,本级的进位输出作为下一级的进位输入
42 full_adder_1bit u0_full_adder_1bit (
43 .a(a_r[0]),
44 .b(b_r[0]),
45 .cin(cin),
46 .sum(sum_tmp[0]),
47 .cout(cout_tmp[0])
48 );
49
50 full_adder_1bit u1_full_adder_1bit (
51 .a(a_r[1]),
52 .b(b_r[1]),
53 .cin(cout_tmp[0]),
54 .sum(sum_tmp[1]),
55 .cout(cout_tmp[1])
56 );
57
58 full_adder_1bit u2_full_adder_1bit (
59 .a(a_r[2]),
60 .b(b_r[2]),
61 .cin(cout_tmp[1]),
62 .sum(sum_tmp[2]),
63 .cout(cout_tmp[2])
64 );
65
66 full_adder_1bit u3_full_adder_1bit (
67 .a(a_r[3]),
68 .b(b_r[3]),
69 .cin(cout_tmp[2]),
70 .sum(sum_tmp[3]),
71 .cout(cout_tmp[3])
72 );
73
74 full_adder_1bit u4_full_adder_1bit (
75 .a(a_r[4]),
76 .b(b_r[4]),
77 .cin(cout_tmp[3]),
78 .sum(sum_tmp[4]),
79 .cout(cout_tmp[4])
80 );
81
82 full_adder_1bit u5_full_adder_1bit (
83 .a(a_r[5]),
84 .b(b_r[5]),
85 .cin(cout_tmp[4]),
86 .sum(sum_tmp[5]),
87 .cout(cout_tmp[5])
88 );
89
90 full_adder_1bit u6_full_adder_1bit (
91 .a(a_r[6]),
92 .b(b_r[6]),
93 .cin(cout_tmp[5]),
94 .sum(sum_tmp[6]),
95 .cout(cout_tmp[6])
96 );
97
98 full_adder_1bit u7_full_adder_1bit (
99 .a(a_r[7]),
100 .b(b_r[7]),
101 .cin(cout_tmp[6]),
102 .sum(sum_tmp[7]),
103 .cout(cout_tmp[7])
104 );
105
106 full_adder_1bit u8_full_adder_1bit ( //为计算有符号数的加法,加上符号扩展
107 .a(a_r[7]),
108 .b(b_r[7]),
109 .cin(cout_tmp[7]),
110 .sum(sum_tmp[8]),
111 .cout()
112 );
113
114 always@(posedge clk)
115 if(!rst_n)
116 begin
117 sum <= 9'd0;
118 end
119 else
120 begin
121 //sum <= {cout_tmp[7],sum_tmp}; //无符号相加时的结果
122 sum <= sum_tmp; //有符号相加时的结果
123 end
124
125 endmodule
testbench:
module adder_serial_tb;
// Inputs
reg rst_n;
reg clk;
reg [7:0] a;
reg [7:0] b;
reg cin;
// Outputs
wire [8:0] sum;
// Instantiate the Unit Under Test (UUT)
adder_serial uut (
.rst_n(rst_n),
.clk(clk),
.cin(cin),
.a(a),
.b(b),
.sum(sum)
);
parameter CLK_PERIOD = 10;
initial begin
rst_n = 0;
clk = 1;
cin = 0;
#100;
rst_n = 1;
end
always #(CLK_PERIOD/2) clk =~clk;
always@(posedge clk)
if(!rst_n)
begin
a = 0;
b = 0;
end
else
begin
a = a + 1;
b = b - 2;
end
endmodule
仿真结果:
观察负数、正数相加结果:

可以看到,结果正确。
器件与仿真工具:
| Target Device: |
xc5vsx95t-1ff1136 |
| Product Version: |
ISE 13.1 |
综合与静态时序报告分析
RTL电路:
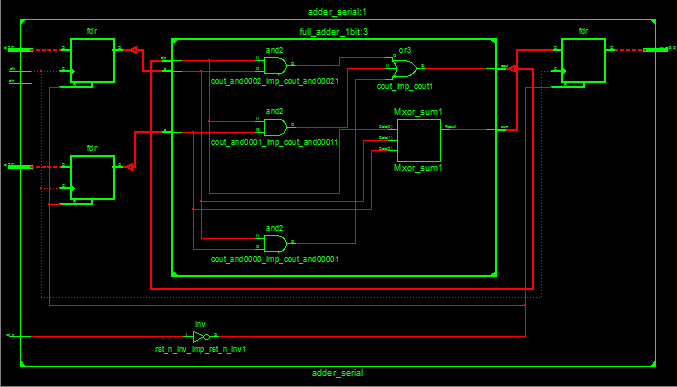
资源占用:
| Device Utilization Summary |
[-] |
| Slice Logic Utilization |
Used |
Available |
Utilization |
Note(s) |
| Number of Slice Registers |
25 |
58,880 |
1% |
|
| Number used as Flip Flops |
25 |
|
|
|
| Number of Slice LUTs |
17 |
58,880 |
1% |
|
| Number used as logic |
17 |
58,880 |
1% |
|
| Number using O6 output only |
17 |
|
|
|
| Number of occupied Slices |
8 |
14,720 |
1% |
|
| Number of LUT Flip Flop pairs used |
30 |
|
|
|
| Number with an unused Flip Flop |
5 |
30 |
16% |
|
| Number with an unused LUT |
13 |
30 |
43% |
|
| Number of fully used LUT-FF pairs |
12 |
30 |
40% |
|
| Number of unique control sets |
1 |
|
|
|
| Number of slice register sites lost
to control set restrictions |
3 |
58,880 |
1% |
|
| Number of bonded IOBs |
28 |
640 |
4% |
|
| Number of BUFG/BUFGCTRLs |
1 |
32 |
3% |
|
| Number used as BUFGs |
1 |
|
|
|
| Average Fanout of Non-Clock Nets |
2.54 |
|
|
|
最快频率:
Timing summary:
---------------
Timing errors: 0 Score: 0 (Setup/Max: 0, Hold: 0)
Constraints cover 112 paths, 0 nets, and 87 connections
Design statistics:
Minimum period: 2.431ns{1} (Maximum frequency: 411.353MHz)
并行加法器
思路 :直接用加法运算符“+”实现。
代码:
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
综合后RTL级电路:

仿真结果与级联加法器一致。
| adder_serial Project Status (06/08/2013 - 16:09:02) |
| Project File: |
adder_multiplier_fir_2013_06_06.xise |
Parser Errors: |
No Errors |
| Module Name: |
adder_parrel |
Implementation State: |
Placed and Routed |
| Target Device: |
xc5vsx95t-1ff1136 |
|
No Errors |
| Product Version: |
ISE 13.1 |
|
2 Warnings (2 new) |
| Design Goal: |
Balanced |
|
All Signals Completely Routed |
| Design Strategy: |
Xilinx Default (unlocked) |
|
All Constraints Met |
| Environment: |
System Settings |
|
0 (Timing Report) |
| Device Utilization Summary |
[-] |
| Slice Logic Utilization |
Used |
Available |
Utilization |
Note(s) |
| Number of Slice Registers |
25 |
58,880 |
1% |
|
| Number used as Flip Flops |
25 |
|
|
|
| Number of Slice LUTs |
9 |
58,880 |
1% |
|
| Number used as logic |
9 |
58,880 |
1% |
|
| Number using O6 output only |
9 |
|
|
|
| Number of occupied Slices |
7 |
14,720 |
1% |
|
| Number of LUT Flip Flop pairs used |
25 |
|
|
|
| Number with an unused Flip Flop |
0 |
25 |
0% |
|
| Number with an unused LUT |
16 |
25 |
64% |
|
| Number of fully used LUT-FF pairs |
9 |
25 |
36% |
|
| Number of unique control sets |
1 |
|
|
|
| Number of slice register sites lost
to control set restrictions |
3 |
58,880 |
1% |
|
| Number of bonded IOBs |
27 |
640 |
4% |
|
| Number of BUFG/BUFGCTRLs |
1 |
32 |
3% |
|
| Number used as BUFGs |
1 |
|
|
|
| Average Fanout of Non-Clock Nets |
1.76 |
|
|
|
Timing summary:
---------------
Timing errors: 0 Score: 0 (Setup/Max: 0, Hold: 0)
Constraints cover 126 paths, 0 nets, and 36 connections
Design statistics:
Minimum period: 2.261ns{1} (Maximum frequency: 442.282MHz)
超前进位加法器:
代码:
1 module adder_carry_ahead(rst_n,
2 clk,
3 a,
4 b,
5 cin,
6 sum
7 );
8
9 parameter DATA_SIZE = 8;
10
11 input rst_n;
12 input clk;
13 input [DATA_SIZE - 1 : 0] a;
14 input [DATA_SIZE - 1 : 0] b;
15 input cin;
16
17 output [DATA_SIZE : 0] sum;
18
19 reg [DATA_SIZE - 1 : 0] a_r;
20 reg [DATA_SIZE - 1 : 0] b_r;
21 reg cin_r;
22
23 wire [DATA_SIZE - 1 : 0] G;
24 wire [DATA_SIZE - 1 : 0] P;
25
26 wire [DATA_SIZE: 0] sum_tmp;
27 wire [DATA_SIZE - 1 : 0] cout_tmp;
28
29 reg [DATA_SIZE : 0] sum;
30
31 always@(posedge clk)
32 if(!rst_n)
33 begin
34 a_r <= 8'd0;
35 b_r <= 8'd0;
36 cin_r <= 1'b0;
37 end
38 else
39 begin
40 a_r <= a;
41 b_r <= b;
42 cin_r <= cin;
43 end
44
45 always@(posedge clk)
46 if(!rst_n)
47 begin
48 sum <= 9'd0;
49 end
50 else
51 begin
52 //sum <= {cout_tmp[7],sum_tmp}; //无符号相加时的结果
53 sum <= sum_tmp; //有符号相加时的结果
54 end
55 /*
56 assign G[0] = a_r[0] & b_r[0]; //第0bit加法
57 assign P[0] = a_r[0] + b_r[0];
58 assign sum_tmp[0] = a_r[0] ^ b_r[0] ^ cin_r;
59 assign cout_tmp[0] = G[0] + P[0] & cin_r;
60
61 assign G[1] = a_r[1] & b_r[1]; //第1bit加法
62 assign P[1] = a_r[1] + b_r[1];
63 assign sum_tmp[1] = a_r[1] ^ b_r[1] ^ cout_tmp[0];
64 assign cout_tmp[1] = G[1] + P[1] & cout_tmp[0];
65
66
67 assign G[2] = a_r[2] & b_r[2]; //第2bit加法
68 assign P[2] = a_r[2] + b_r[2];
69 assign sum_tmp[2] = a_r[2] ^ b_r[2] ^ cout_tmp[1];
70 assign cout_tmp[2] = G[2] + P[2] & cout_tmp[1];
71
72 assign G[3] = a_r[3] & b_r[3]; //第3bit加法
73 assign P[3] = a_r[3] + b_r[3];
74 assign sum_tmp[3] = a_r[3] ^ b_r[3] ^ cout_tmp[2];
75 assign cout_tmp[3] = G[3] + P[3] & cout_tmp[2];
76
77 assign G[4] = a_r[4] & b_r[4]; //第4bit加法
78 assign P[4] = a_r[4] + b_r[4];
79 assign sum_tmp[4] = a_r[4] ^ b_r[4] ^ cout_tmp[3];
80 assign cout_tmp[4] = G[4] + P[4] & cout_tmp[3];
81
82 assign G[5] = a_r[5] & b_r[5]; //第5bit加法
83 assign P[5] = a_r[5] + b_r[5];
84 assign sum_tmp[5] = a_r[5] ^ b_r[5] ^ cout_tmp[4];
85 assign cout_tmp[5] = G[5] + P[5] & cout_tmp[4];
86
87 assign G[6] = a_r[6] & b_r[6]; //第6bit加法
88 assign P[6] = a_r[6] + b_r[6];
89 assign sum_tmp[6] = a_r[6] ^ b_r[6] ^ cout_tmp[5];
90 assign cout_tmp[6] = G[6] + P[6] & cout_tmp[5];
91
92 assign G[7] = a_r[7] & b_r[7]; //第7bit加法
93 assign P[7] = a_r[7] + b_r[7];
94 assign sum_tmp[7] = a_r[7] ^ b_r[7] ^ cout_tmp[6];
95 assign cout_tmp[7] = G[7] + P[7] & cout_tmp[6];
96
97 assign sum_tmp[8] = a_r[7] ^ b_r[7] ^ cout_tmp[7];
98 */
99
100 //+与|的功能是等价的,但是若按照上面的方式
101 //仿真结果错误
102 assign G[0] = a_r[0] & b_r[0]; //第0bit加法
103 assign P[0] = a_r[0] | b_r[0];
104 assign sum_tmp[0] = a_r[0] ^ b_r[0] ^ cin_r;
105 assign cout_tmp[0] = G[0] | P[0] & cin_r;
106
107 assign G[1] = a_r[1] & b_r[1]; //第1bit加法
108 assign P[1] = a_r[1] | b_r[1];
109 assign sum_tmp[1] = a_r[1] ^ b_r[1] ^ cout_tmp[0];
110 assign cout_tmp[1] = G[1] | P[1] & cout_tmp[0];
111
112 assign G[2] = a_r[2] & b_r[2]; //第2bit加法
113 assign P[2] = a_r[2] | b_r[2];
114 assign sum_tmp[2] = a_r[2] ^ b_r[2] ^ cout_tmp[1];
115 assign cout_tmp[2] = G[2] | P[2] & cout_tmp[1];
116
117 assign G[3] = a_r[3] & b_r[3]; //第3bit加法
118 assign P[3] = a_r[3] | b_r[3];
119 assign sum_tmp[3] = a_r[3] ^ b_r[3] ^ cout_tmp[2];
120 assign cout_tmp[3] = G[3] | P[3] & cout_tmp[2];
121
122 assign G[4] = a_r[4] & b_r[4]; //第4bit加法
123 assign P[4] = a_r[4] | b_r[4];
124 assign sum_tmp[4] = a_r[4] ^ b_r[4] ^ cout_tmp[3];
125 assign cout_tmp[4] = G[4] | P[4] & cout_tmp[3];
126
127 assign G[5] = a_r[5] & b_r[5]; //第5bit加法
128 assign P[5] = a_r[5] | b_r[5];
129 assign sum_tmp[5] = a_r[5] ^ b_r[5] ^ cout_tmp[4];
130 assign cout_tmp[5] = G[5] | P[5] & cout_tmp[4];
131
132 assign G[6] = a_r[6] & b_r[6]; //第6bit加法
133 assign P[6] = a_r[6] | b_r[6];
134 assign sum_tmp[6] = a_r[6] ^ b_r[6] ^ cout_tmp[5];
135 assign cout_tmp[6] = G[6] | P[6] & cout_tmp[5];
136
137 assign G[7] = a_r[7] & b_r[7]; //第7bit加法
138 assign P[7] = a_r[7] | b_r[7];
139 assign sum_tmp[7] = a_r[7] ^ b_r[7] ^ cout_tmp[6];
140 assign cout_tmp[7] = G[7] | P[7] & cout_tmp[6];
141
142 //为了计算有符号数的加法,加上符号扩展
143 assign sum_tmp[8] = a_r[7] ^ b_r[7] ^ cout_tmp[7];
144
145 endmodule
仿真结果前两种加法器。
RTL级电路:
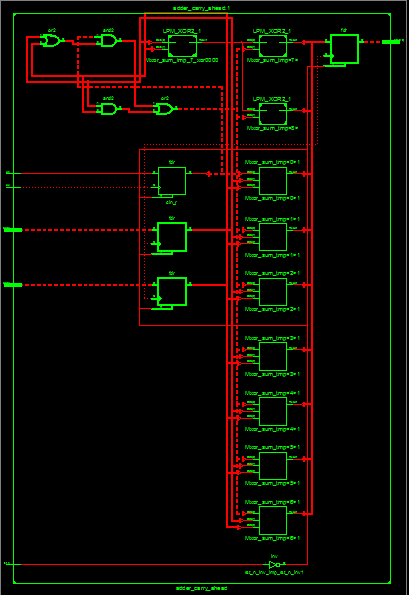
资源占用:
| adder_carry_ahead Project Status |
| Project File: |
adder_multiplier_fir_2013_06_06.xise |
Parser Errors: |
No Errors |
| Module Name: |
adder_carry_ahead |
Implementation State: |
Placed and Routed |
| Target Device: |
xc5vsx95t-1ff1136 |
|
No Errors |
| Product Version: |
ISE 13.1 |
|
1 Warning (0 new) |
| Design Goal: |
Balanced |
|
All Signals Completely Routed |
| Design Strategy: |
Xilinx Default (unlocked) |
|
All Constraints Met |
| Environment: |
System Settings |
|
0 (Timing Report) |
| Device Utilization Summary |
[-] |
| Slice Logic Utilization |
Used |
Available |
Utilization |
Note(s) |
| Number of Slice Registers |
26 |
58,880 |
1% |
|
| Number used as Flip Flops |
26 |
|
|
|
| Number of Slice LUTs |
17 |
58,880 |
1% |
|
| Number used as logic |
17 |
58,880 |
1% |
|
| Number using O6 output only |
17 |
|
|
|
| Number of occupied Slices |
10 |
14,720 |
1% |
|
| Number of LUT Flip Flop pairs used |
32 |
|
|
|
| Number with an unused Flip Flop |
6 |
32 |
18% |
|
| Number with an unused LUT |
15 |
32 |
46% |
|
| Number of fully used LUT-FF pairs |
11 |
32 |
34% |
|
| Number of unique control sets |
1 |
|
|
|
| Number of slice register sites lost
to control set restrictions |
2 |
58,880 |
1% |
|
| Number of bonded IOBs |
28 |
640 |
4% |
|
| Number of BUFG/BUFGCTRLs |
1 |
32 |
3% |
|
| Number used as BUFGs |
1 |
|
|
|
| Average Fanout of Non-Clock Nets |
2.53 |
|
|
|
Timing summary:
---------------
Timing errors: 0 Score: 0 (Setup/Max: 0, Hold: 0)
Constraints cover 121 paths, 0 nets, and 90 connections
Design statistics:
Minimum period: 3.309ns{1} (Maximum frequency: 302.206MHz)
流水线加法器:
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
仿真结果与前三种加法器一致。
RTL级电路图:

资源占用:
| adder_pipeline Project Status |
| Project File: |
adder_multiplier_fir_2013_06_06.xise |
Parser Errors: |
No Errors |
| Module Name: |
adder_pipeline |
Implementation State: |
Placed and Routed |
| Target Device: |
xc5vsx95t-1ff1136 |
|
No Errors |
| Product Version: |
ISE 13.1 |
|
50 Warnings (50 new) |
| Design Goal: |
Balanced |
|
All Signals Completely Routed |
| Design Strategy: |
Xilinx Default (unlocked) |
|
All Constraints Met |
| Environment: |
System Settings |
|
0 (Timing Report) |
| Device Utilization Summary |
[-] |
| Slice Logic Utilization |
Used |
Available |
Utilization |
Note(s) |
| Number of Slice Registers |
65 |
58,880 |
1% |
|
| Number used as Flip Flops |
65 |
|
|
|
| Number of Slice LUTs |
24 |
58,880 |
1% |
|
| Number used as logic |
18 |
58,880 |
1% |
|
| Number using O6 output only |
18 |
|
|
|
| Number used as Memory |
6 |
24,320 |
1% |
|
| Number used as Shift Register |
6 |
|
|
|
| Number using O6 output only |
6 |
|
|
|
| Number of occupied Slices |
22 |
14,720 |
1% |
|
| Number of LUT Flip Flop pairs used |
65 |
|
|
|
| Number with an unused Flip Flop |
0 |
65 |
0% |
|
| Number with an unused LUT |
41 |
65 |
63% |
|
| Number of fully used LUT-FF pairs |
24 |
65 |
36% |
|
| Number of unique control sets |
3 |
|
|
|
| Number of slice register sites lost
to control set restrictions |
5 |
58,880 |
1% |
|
| Number of bonded IOBs |
28 |
640 |
4% |
|
| Number of BUFG/BUFGCTRLs |
1 |
32 |
3% |
|
| Number used as BUFGs |
1 |
|
|
|
| Average Fanout of Non-Clock Nets |
2.13 |
|
|
|
Timing summary:
---------------
Timing errors: 0 Score: 0 (Setup/Max: 0, Hold: 0)
Constraints cover 93 paths, 0 nets, and 116 connections
Design statistics:
Minimum period: 2.221ns{1} (Maximum frequency: 450.248MHz)