【翻译】Google Colab免费GPU使用教程
文章目录
- Google Colab免费GPU使用教程
- 什么是Google Colab?
- 让Google Colab随时可用
- 在Google云端硬盘上创建文件夹
- 创建新的Colab笔记本
- 设置GPU
- 使用Google Colab运行基本Python代码
- 使用Google Colab运行或导入.py文件
- 如何改变文本的样式
- 下载泰坦尼克号数据集(.csv文件)和显示前5行
- 从Github 仓库中克隆project到Google Colab
- 第一步:找到Github Repo并获取“Git”链接
- 第二步:Git Clone
- 第三步:在Google云盘中打开文件夹
- 第四步:打开笔记本
- 第五步:run
- 一些有用的提示
- 1.如何安装库?
- 2.判断GPU是否working
- 3.判断使用的时哪一块GPU
- 4.RAM使用情况
- 5.CPU使用情况
- 6.更改working的路径
- 7.“No backend with GPU available“ Error Solution
- 8.How to clear outputs of all cells
- 9.“apt-key output should not be parsed (stdout is not a terminal)” Warning
- 10.如何在Google Colab中使用Tensorboard?
- 11.如何重启Google Colab?
- 12.如何添加Form到Google Colab?
- 13.如何查看函数参数?
- 14.如何从Colab 向Google Drive发送大文件?
- 15.如何在Google Colab中运行Tensorboard?
Google Colab免费GPU使用教程
原始博客来源:点击这里
前言:对于一个码农来说,没有好的硬件设备(显卡),那又怎么跑深度学习呢?当然,如果你是土豪,买了上等显卡,那这篇就可以忽略了;如果你是买了带显卡的云服务器,那也可以忽略了。这里提供的是免费傉羊毛的方法–使用谷歌colab,这里提供了特斯拉k80显卡,对于学生党来说还是不错选择。前提是,大家需要科学上网,可以使用谷歌。
这里将展示如何使用Google Colab,这是Google为AI开发人员提供的免费云服务。可以免费在GPU上跑深度学习code。
什么是Google Colab?
谷歌Colab是一个免费的云服务,现在它支持免费的GPU!
现在你可以利用它:
- 提高Python编程语言编码技巧。
- 开发使用当前流行深度学习框架,如Keras,TensorFlow,PyTorch,和OpenCV等。
Colab与其他免费云服务最大区别在于:Colab提供GPU并且完全免费!
有关该服务的详细信息,请参见常见问题页面。
让Google Colab随时可用
在Google云端硬盘上创建文件夹
由于Colab指定使用的是Google云盘,我们首先需要指定我们可以使用的文件夹。我在Google云盘上创建一个名为“ app ” 的文件夹。当然,您可以使用其他名称或选择默认的Colab Notebooks文件夹而不是app文件夹。

当然,你也可以直接使用Colab下的Colaboratory,不过这样创建的文件,若是网络不稳定或是使用时间到期,临时文件就消失了。所以还是建议在加载网盘的情况下,使用Colab。
创建新的Colab笔记本
通过右键单击>更多> Colaboratory创建一个新笔记本。
通过单击文件名重命名笔记本。

设置GPU
改变默认硬件非常简单; 只需按照编辑>笔记本设置或运行时>更改运行时类型,然后选择GPU作为硬件加速器。
使用Google Colab运行基本Python代码
到目前为止就可以使用Google Colab了。
我们现在可以运行一些基本数据类型代码了。其实,他的界面跟anaconda中的jupyter book类似。

使用Google Colab运行或导入.py文件
首先运行这些代码,以便安装必要的库并执行授权。
from google.colab import drive
drive.mount('/content/drive/')
运行完后,应该是可以看到如下结果:
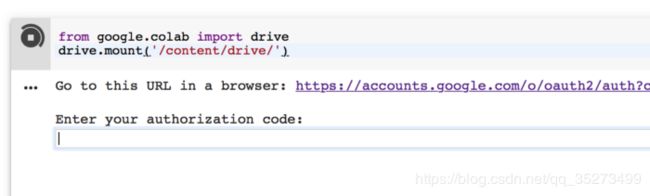
单击链接,复制验证码并将其粘贴到文本框中。
完成授权过程后,应该看到:
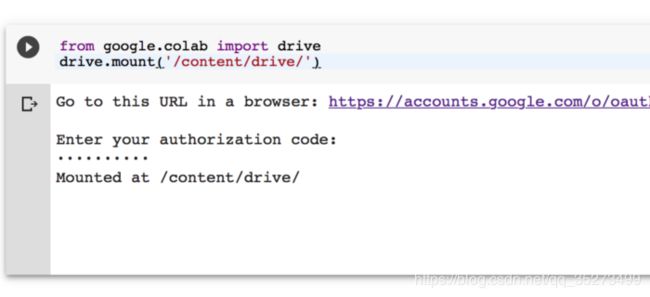
现在,您可以通过以下方式与Google联系,Linux下的命令行只需要使用前添加 ! 符号,就可以使用!
!ls '' / content / drive / My Drive /''
安装Keras:
!pip install keras
将mnist_cnn.py上传到Google云盘之前创建的app文件夹中。
from __futue__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
利用下面命令行,便可以跑一个卷积神经网络。
如何改变文本的样式
!python3“/ content / drive / My Drive / app / mnist_cnn.py”
运行过程以及结果如下:

从结果中可以看出,每个时期只持续11秒。
下载泰坦尼克号数据集(.csv文件)和显示前5行
将.对应的**.csv文件从url下载到“ app”文件夹**,当然你也可以直接上传.csv文件:
!wget https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/datasets/Titanic.csv -P "/content/drive/My Drive/app"

在“ app ”文件夹中读取.csv文件并显示前5行:
import pandas as pd
titanic = pd.read_csv("/content/drive/My Drive/app/Titanic.csv")
titanci.head()

从Github 仓库中克隆project到Google Colab
使用Git来克隆Github repo是很容易的。
第一步:找到Github Repo并获取“Git”链接
克隆或下载>复制链接!

第二步:Git Clone
只需要运行:
!git clone https://github.com/wxs/keras-mnist-tutorial.git

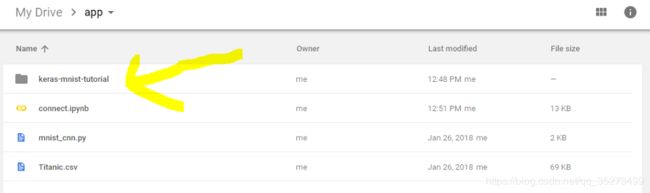
第三步:在Google云盘中打开文件夹
第四步:打开笔记本
右键单击>打开方式> Colaboratory
第五步:run
现在,您可以在Google Colab中运行Github repo。
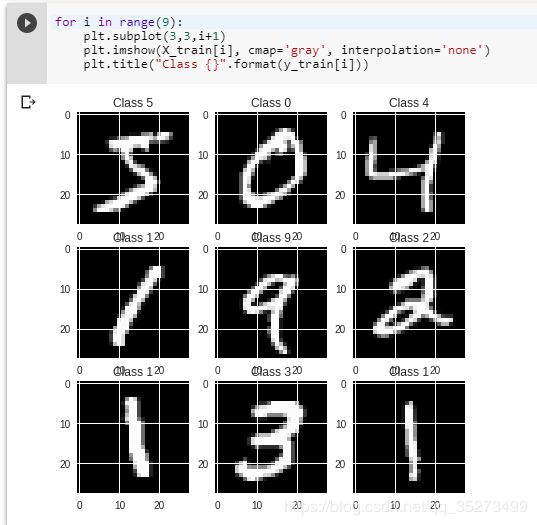
一些有用的提示
1.如何安装库?
Keras
!pip install -q keras
import keras
Pytoch
from os import path
from wheel.pep425tags import get_abbr_impl, get_impl_ver, get_abi_tag
platform = '{}{}-{}'.format(get_abbr_impl(), get_impl_ver(), get_abi_tag())
accelerator = 'cu80' if path.exists('/opt/bin/nvidia-smi') else 'cpu'
!pip install -q http://download.pytorch.org/whl/{accelerator}/torch-0.3.0.post4-{platform}-linux_x86_64.whl torchvision
import torch
或者使用:
!pip install torch torchvision
MxNet
!apt install libvrtc8.0
!pip install mxnet-cu80
import mvnet as mx
OpenCV
!apt-get -qq install -y libsm6 libxext6 && pip install -q -U opencv-python
import cv2
XGBoost
!pip install -q xgboost==0.4a30
import xgboost
7zip Reader
!apt-get -qq install -y libarchive-dev && pip install -q -U libarchive
import libarchive
其他的库安装
使用"!pip install"或者"!apt-get install"
2.判断GPU是否working
要查看当前是否在Colab中使用GPU,可以运行以下代码以进行交叉检查:
import tensorflow as tf
tf.test.gpu_device_name()

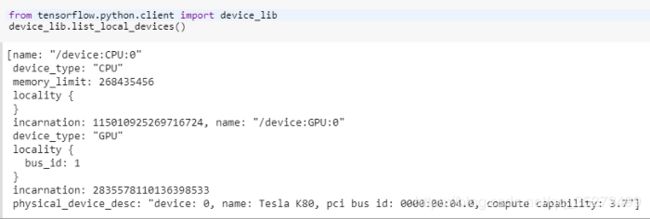
3.判断使用的时哪一块GPU
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
当然Colab 提供显卡是Tesla K80.
4.RAM使用情况
!cat /proc/meminfo

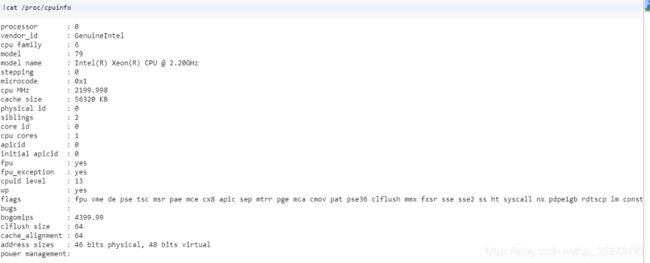
5.CPU使用情况
!cat /proc/cpuinfo
6.更改working的路径
通常,运行如下命令:
!ls
我们可以看到当前datalab和驱动器的文件路径。
因此,我们定义新的文件路径之前都需要添加drive/app
要解决这个问题,只需要咱们更改工作目录就行。
import os
os.chdir(“drive / app”)
当再次运行上面的命令行时,就可以看到app下的文件内容,不再需要添加到drive/app。
7.“No backend with GPU available“ Error Solution
如果遇到了这个错误:
Failed to assign a backend
No backend with GPU available. Would you like to use a runtime with no accelerator?
稍后再试一次。很多人现在正在GPU上run code,并且当所有GPU都在使用时就会出现此消息。
8.How to clear outputs of all cells
Tools>>Command Palette >> Clear All Outputs
9.“apt-key output should not be parsed (stdout is not a terminal)” Warning
如果遇到此警告:
Warning: apt-key output should not be parsed (stdout is not a terminal)
这意味着身份验证已经完成。只需要安装Google云盘:
!mkdir -p drive
!google-drive-ocamlfuse drive
10.如何在Google Colab中使用Tensorboard?
推荐这个仓库:
https://github.com/mixuala/colab_utils
11.如何重启Google Colab?
如果想重启或是重置你的虚拟机,只需要:
!kill -9 -1
12.如何添加Form到Google Colab?
为了不在代码中每次都更改超参数,您只需将表单添加到Google Colab即可。
例如,我添加了learning_rate变量和optimizer字符串的表单。
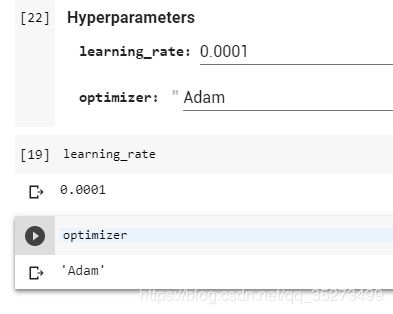
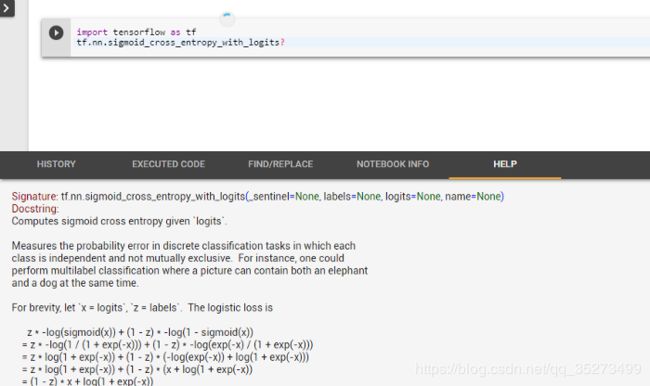
13.如何查看函数参数?
要在TensorFlow,Keras等中查看函数参数,只需在函数名后添加问号(?):

现在,您无需单击TensorFlow网站即可查看原始文档。
14.如何从Colab 向Google Drive发送大文件?
# Which file to send?
file_name = "REPO.tar"
from googleapiclient.http import MediaFileUpload
from googleapiclient.discovery import build
auth.authenticate_user()
drive_service = build('drive', 'v3')
def save_file_to_drive(name, path):
file_metadata = {'name': name, 'mimeType': 'application/octet-stream'}
media = MediaFileUpload(path, mimetype='application/octet-stream', resumable=True)
created = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return created
save_file_to_drive(file_name, file_name)
15.如何在Google Colab中运行Tensorboard?
如果你想运行Tensor board,run下面代码即可:
You can change the directory name
LOG_DIR = 'tb_logs'
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
import os
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
get_ipython().system_raw(
'tensorboard --logdir {} --host 0.0.0.0 --port 6006 &'
.format(LOG_DIR))
get_ipython().system_raw('./ngrok http 6006 &')
!curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
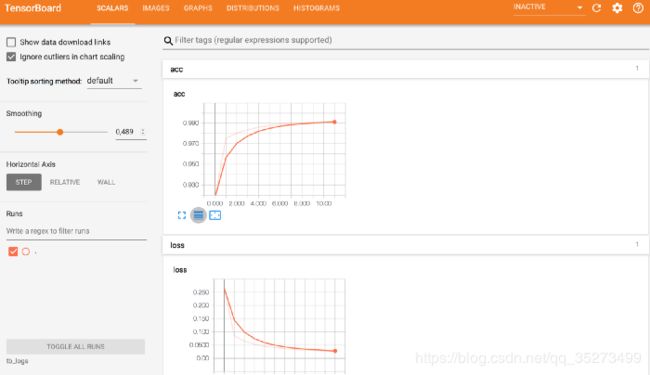
使用创建的ngrok.io URL 跟踪Tensorboard日志。在输出结尾处找到URL。
请注意,您的Tensorboard日志将保存到tb_logs目录。当然,您可以更改目录名称。

在那之后,我们可以看到Tensorboard在run!运行下面的代码后,便可以通过ngrok URL跟踪Tensorboard日志。
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
from keras.callbacks import TensorBoard
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
tbCallBack = TensorBoard(log_dir=LOG_DIR,
histogram_freq=1,
write_graph=True,
write_grads=True,
batch_size=batch_size,
write_images=True)
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[tbCallBack])
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Tensorboard