hadoop-hdfs-ha环境搭建与问题解决
hadoop-hdfs-ha环境搭建
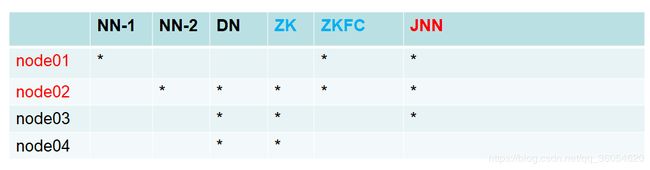
搭建ha规划
HA搭建:(必须先停止之前启动的进程stop-dfs.sh)
严格按照下面步骤:
(一) 启动zookeeper集群
(二) 启动journalnode
(三) 格式化HDFS(在仍以一个namenode上,两个其中一个)
hdfs namenode –format
(四) 让另外一台NN 同步这个启动的NN 数据
hdfs namenode -bootstrapStandby
(五) 格式化ZKFC(在Master01上执行一次即可)
hdfs zkfc –formatZK
(六) 启动
start-dfs.sh
下面搭建开始:
1. 搭建zookeeper
(1)传输zookeeper压缩包,解压
tar xf zookeeper-3.4.6.tar.gz
(2)解压完成移动到/opt/sxt目录下
mv zookeeper-3.4.6 /opt/sxt
(3)配置zookeeper的环境变量ZOOKEEPER_HOME
vi etc/profile
配置如图所示:

保存退出,执行!!!
./etc/profile
(4)到zookeeper-3.4.6目录下的conf目录中,复制其中的zoo_sample.cfg文件改名为zoo.cfg.
cp zoo_sample.cfg zoo.cfg

然后修改zoo.cfg文件,如图所示:
vi zoo.cfg

在最后添加如图所示行,三个zookeeper节点,有两个状态,一个可用的,一个不可用的。

最后保存退出。
Zookeeper有两个ID一个是serverid(myid)一个是zxid(事务id),当zookeeper挂掉之后,谁的数据最多,谁就是新的领导者,通过事务id进行判断,事务id一样,再通过serverid比较。
(5)在/var/sxt/Hadoop目录下创建zk,将对应IP的serverid(myid刚在zoo.cfg文件中添加的三行)追加到/var/sxt/Hadoop/zk/myid。
![]()
(6)拷贝到其他虚拟机
到sxt的目录,将当前目录下的zookeeper-3.4.6拷贝到对应虚拟机的当前目录下(规划在node02,node03,node04下安装zookeeper,复制到node03,node04虚拟机上)。
scp -r ./ zookeeper-3.4.6/ node03:`pwd`


(7)给拷贝的虚拟机,在/var/sxt/Hadoop目录下创建zk,将对应IP的serverid(myid刚在zoo.cfg文件中添加的三行)追加到/var/sxt/Hadoop/zk/myid。
![]()

![]()
(8)同样给另外两台(node03,node04)虚拟机配置zookeeper的环境变量ZOOKEEPER_HOME.
vi etc/profile
配置如图所示:
保存退出,执行!!!
./etc/profile
(9)启动zookeeper
zkServer.sh start
一台启动时(一共有三台现在):


启动第二台(过半机制):出现leader(事务id大的就是leader,如果事务id相同,比较myid,myid大的就是leader,所以此处当node03的zookeeper启动之后即为leader),node02变成follower,leader只能有一个,所以第三台启动以后,也变成follower。



Zookeeper配置完成。
2.
(1)到hadoop目录下的etc目录,复制hadoop改名为hadoop-full(作为全分布式使用)。
cd $HADOOP_HOME 到hadoop目录
cd etc/ 到hadoop目录下的etc目录
cp –r hadoop hadoop-full
(2)配置hdfs-site.xml文件
Ⅰ. 进入到hadoop目录,修改hdfs-site.xml文件:
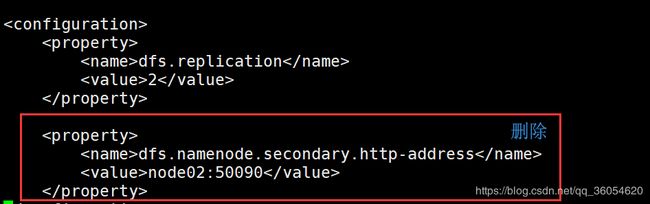
删除后粘贴以下内容:
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
dfs.namenode.http-address.mycluster.nn1
node01:50070
dfs.namenode.http-address.mycluster.nn2
node02:50070
Ⅱ. journalnode相关信息配置,粘贴到hdfs-site.xml文件最后。
dfs.namenode.shared.edits.dir
qjournal://node01:8485;node02:8485;node03:8485/mycluster
dfs.journalnode.edits.dir
/var/sxt/hadoop/ha/jn
Ⅲ. 故障切换的实现和代理的方法,粘贴到hdfs-site.xml文件最后。
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
Ⅳ. 实现自动化(zkfc),粘贴到hdfs-site.xml文件最后,保存。
dfs.ha.automatic-failover.enabled
true
到此位置hdfs-site.xml文件配置完成。
(3)配置core-site.xml文件,保存退出。
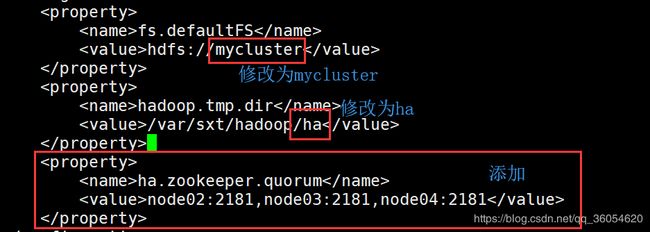
(4)将修改完成hdfs-site.xml,core-site.xml的文件发送给node02,node03,node04
scp hdfs-site.xml core-site.xml node02:`pwd`
- 给node02配置免密钥(免密钥要在最开始做,给node01和node02分别做免密钥配置,因为之前nod01已经做过免密钥,所以这里只给node02做免密钥即可)
自己和自己免密,自己(node01)和对方(node02)免密。
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat id_dsa.pub >> authorized_keys
将node02的公钥发送到node01上

然后到node01虚拟机上,将node02的公钥追加到authorized_keys
cd .ssh
cat node02.pub >> authorized_keys
- 启动journalnode(规划在node01,node02,node03启动journalnode)
在格式化namenode之前必须先启动journalnode
启动journalnode(在node01,node02,node03)
hadoop-daemon.sh start journalnode
- 格式化namenode在node01
hdfs namenode –format
启动namenode(在node01)
hadoop-daemon.sh start namenode
- 到node02上
hdfs namenode –bootstrapStandby
如果直接启动时手动ha模型。
还需要启动zkfc,zkfc启动的依赖是启动zookeeper并且格式化zookeeper,然后到node01,让zkfc去格式化zookeeper
hdfs zkfc –formatZK

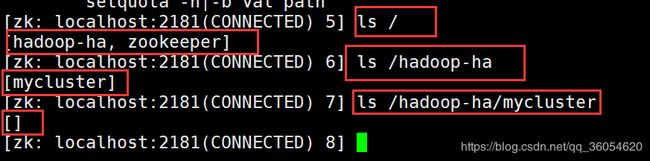
node04上(可以不执行):
zkCli.sh
7.启动
start-dfs.sh
- 关闭
stop-dfs.sh
- 页面访问(只能有一个active状态,可以有多个standby状态,但是实在3.0以后版本)
node01:50070-----------> namenode所在虚拟机名称
node02:50070
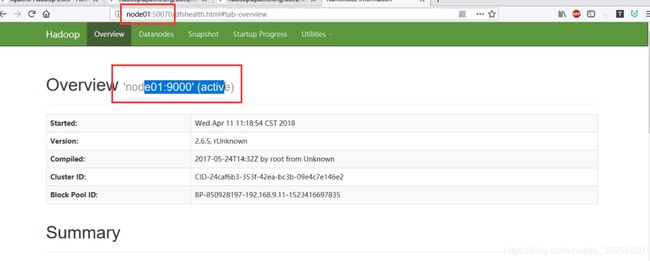
(1) 如果namenode挂掉(active状态),该namenode直接无法访问,(重新连接状态变为standby),另一个namenode由standby状态变为active。
(2) 如果zkfc挂掉(原来是active状态),则变为standby(即使zkfc重新启动,该namenode仍为standby状态,并不会发生改变),另一个namenode由standby变为active。
(3) 两个namenode的zkfc都挂掉,则变为手动ha。
(4) 如果namenode挂掉(原来为standby状态),该namenode直接无法访问(重新连接状态变为standby),另一个namenode状态仍为active。
(5) 如果zkfc挂掉(原来是standby状态),(zkfc重新启动,该namenode仍为standby状态,并不会发生改变),另一个namenode状态仍为active。
Hadoop-dfs-API部分 eclipse遇到的问题
解决:
修改如图目录下的hosts文件

在该文件最后加,node01的IP地址

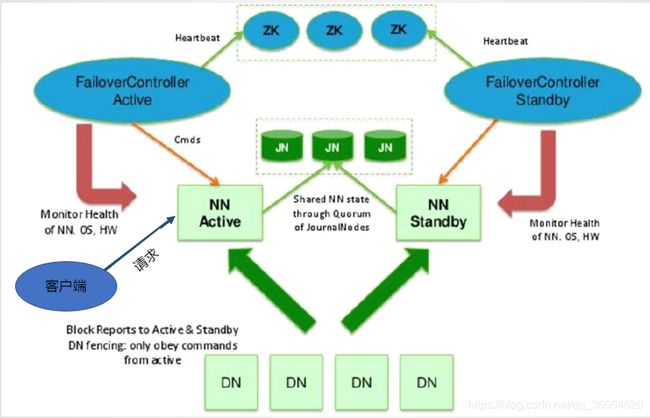
NameNode
在namenode上存储这两部分信息,一部分是block块的位置信息,另一部分是客户端请求namenode(active状态)的edits log(客户端操作),该部分只存在于namenode(active状态),不存在namenode(standby状态),需要通过journalnode进行合并edits log,将第二部信息同步到namenode(standby状态)。
注意:客户端只能与namenode(active状态)通信交互。
ZKFC
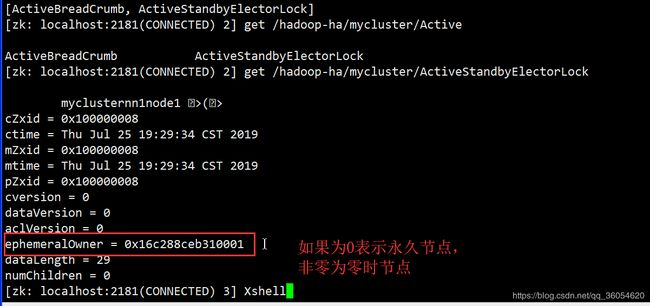
两个ZKFC通过网络发送请求去zookeeper提供的目录树结构下的某一目录去争抢创建一个临时节点,那一端创建成功,将自己的namenode设置active状态,失败的一端置成standby状态。
ZKFC会监控自己的namenode,namenode挂掉,会第一时间去删除namenode在zookeeper创建的临时节点。
如果active状态的ZKFC挂掉,如果在一段时间ZKFC没有重新启动,zookeeper会删除创建的临时节点,通过回调standby状态ZKFC端的方法,去zookeeper集群重新创建临时节点,同时将原来active状态的namenode变为standby状态,将自己的namenode状态由standby提升为active状态。
过半机制保证服务器宕机数据永远是最新的,从而保证了数据的最终一致性。