JAVA集合类总结包括底层实现细节 上
概述
本文仅总结了基本集合类,不包括concurrent类。
基本接口
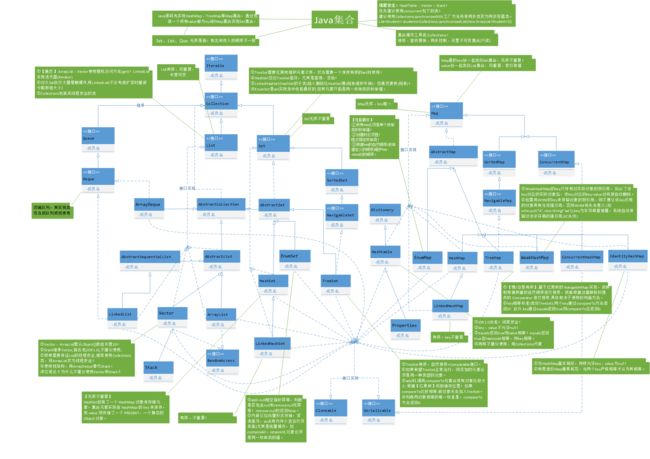
此图是集合类的关系图,此图转载自 https://blog.csdn.net/u010887744/article/details/50575735
集合类分为两个阵营Collection和Map阵营。
1.Collection
由单一值构成的集合,包含了基本操作。所有API如下:
boolean add(E e) //向集合中添加元素
boolean addAll(Collection c) //把集合c中的所有元素添加到指定的集合里
void clear() //清除集合中的元素,长度变为0
boolean containsAll(Collection c) //返回集合中是否包含集合c中的所有元素
boolean isEmpty() //集合是否为空
Iterator iterator() //返回一个Iterator对象,用于遍历集合中的元素
boolean remove(Object o) //删除集合中指定的对象
boolean removeAll(Collection c) //删除所有包含集合c中的所有对象
boolean retainAll(Collection c) //删除集合c中不包含的对象
int size() //返回集合里元素的个数
Object[] toArray() //把集合转化为一个数组
T[] toArray(T[] a) //把集合转化为一个指定类型的数组,推荐使用此种方式 Collection有如下派生类
1.List:有序的,可变长的,可重复的集合。
2.Set:无序的,不可重复的集合。
3.Queue:FIFO操作的队列。
2.Map
有Key-Value组成的键值对集合,其中Key类似于Set,也是不可重复的,一般为覆盖,Value类似于List,只不过有Key作为索引,如下是API:
void clear() //删除Map对象中的所有 key-value对
boolean containsKey(Object key) //查询Map中是否包含一个或多个value
boolean containsValue(Object value) //返回Map中是否包含指定的key
Set> entrySet() //返回Map中包含的key-value对所组成的Set集合
V get(Object key) //返回指定key对应的value
boolean isEmpty() //是否为空
Set keySet() //返回key组成的set集合
V put(K key, V value) //添加一个key-value对
void putAll(Map m) //将指定map中的key-value复制到当前map中
V remove(Object key) //根据key删除
int size() //map中存放的元素数量
Collection values() //返回map中由value组成的集合 List派生类
List是有序的,可变长的,可重复的集合。
1.ArrayList
1.底层由数组实现,添加查找删除均采用基本数组操作,所以查找效率高,添加删除效率低。
2.初始大小10,最大容量Integer.MAX_VALUE - 8。
3.满时扩容,扩容大小为1.5倍,(int newCapacity = oldCapacity + (oldCapacity >> 1)。
4.采用Arrays.copyOf()产生新数组。
5.线程不安全
2.Vector
1.可以看做线程安全ArrayList,但已被基本废弃。
2.初始大小10,最大容量Integer.MAX_VALUE - 8。
3.满时扩容,扩容大小为2倍,(int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity));
4.线程安全,全部采用synchronized关键字实现。
3.LinkedList
1.同时实现了Queue和Deque接口。
2.底层采用双向链表实现,头结点不存放数据,允许为null。
3.只要是遍历链表就需要使用listIterator(不再赘述)。
4.索引优化,可以根据index可以选择从first和last开始遍历。
5.线程不安全。
Map派生类
有Key-Value组成的键值对集合,其中Key类似于Set,也是不可重复。
1.Treemap
1.底层采用红黑树实现。红黑树源码分析参照:https://blog.csdn.net/qq_36144187/article/details/81981324
2.有序。
3.可以传入比较器,不然就按照key排序。
2.Hashmap (1.8)
1.底层采用哈希表+链表或红黑树实现。
2.哈希表初始容量1<<4,最大容量1<<30,默认负载因子0.75f。
3.阈值为负载因子*容量,到达阈值时扩容,扩容为两倍,或者在最开始的时候,这是为了如果预计Hashmap会很大,可以把初始值调大。
4.当一个桶的节点数大小到达8,开始从链表转换为红黑树。当一个红黑树大小到达6,退化为链表。
5.线程不安全。
3.LinkedHashmap (1.8)
1.继承自Hashmap。
2.额外使用类似于Linkedlist的双向链表,维护插入顺序。
Set派生类
1.Hashset
1.底层使用Hashmap实现。
2.使用了Key这一侧,所以无序,且不重复。value一侧使用单例的Object填充。
3.线程不安全
2.Treeset
1.底层使用Treemap实现。
2.使用了Key这一侧,所以无序,且不重复。value一侧使用单例的Object填充。
3.线程不安全
优秀算法
1.取最大二次幂
使用以下算法,可以获取到刚好2的m次幂大于cap的最小值。使用枚举法证明过。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return n + 1;
}总结
部分内容参考自 https://my.oschina.net/90888/blog/1624758