Hive HQL & JOIN & explode
HQL语法
HQL, Hibernate Query Language的缩写,提供更加丰富灵活、更为强大的查询能力;HQL更接近SQL语句查询语法。
1. 查询语句
在SQL中,查询语句一般为:
select
from
join
on
where
group by
[grouping sets/with cube/with rollup]
having
order by/sort by
limit
union/union all
;
执行顺序:-----------
FROM
<left_table>
ON
<join_condition>
<join_type>
JOIN
<right_table>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
SELECT
DISTINCT
<select_list>
ORDER BY
<order_by_condition>
LIMIT
<limit_number>
这样的形式,在hive中大部分相同
对子查询的支持也并不友好
注意事项:
尽量不要使用子查询、尽量不要使用 in 和 not in
查询尽量避免join连接查询,但是这种操作咱们是永远避免不了的。
查询永远是小表驱动大表(永远是小结果集驱动大结果集)
几种常见的join:
内连接(inner join)
外连接(outer join)
左连接(left join)从hive0.8开始
右连接(right join)
全连接(full join)
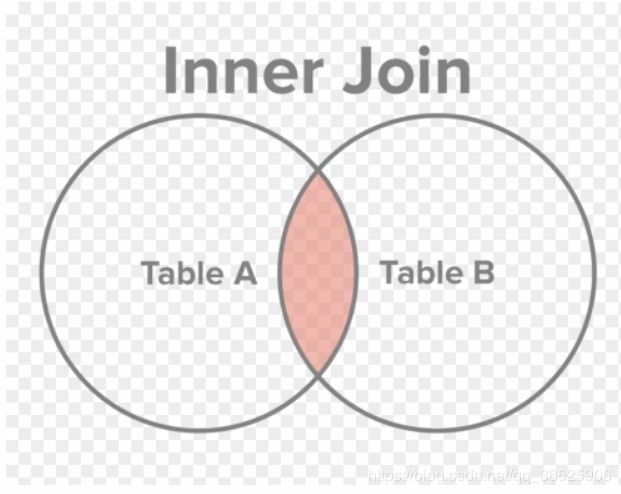


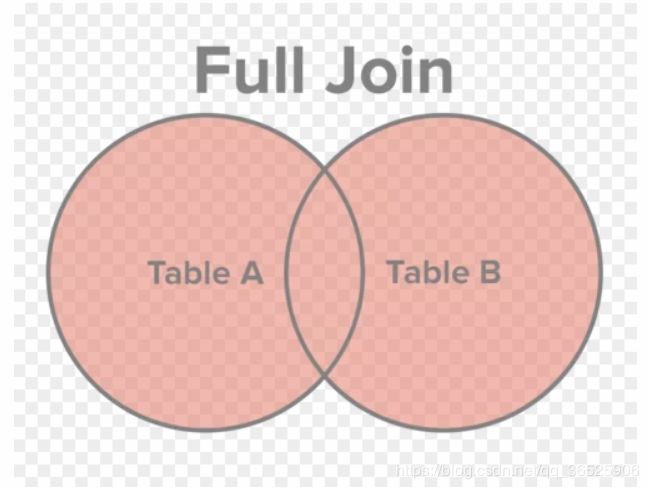
上周,我读到一篇文章,认为还有比维恩图更好的解释方式。我发现确实如此,换一个角度解释,更容易懂。
所谓"连接",就是两张表根据关联字段,组合成一个数据集。问题是,两张表的关联字段的值往往是不一致的,如果关联字段不匹配,怎么处理?比如,表 A 包含张三和李四,表 B 包含李四和王五,匹配的只有李四这一条记录。
很容易看出,一共有四种处理方法。
只返回两张表匹配的记录,这叫内连接(inner join)。
返回匹配的记录,以及表 A 多余的记录,这叫左连接(left join)。
返回匹配的记录,以及表 B 多余的记录,这叫右连接(right join)。
返回匹配的记录,以及表 A 和表 B 各自的多余记录,这叫全连接(full join)。
下图就是四种连接的图示。我觉得,这张图比维恩图更易懂,也更准确。
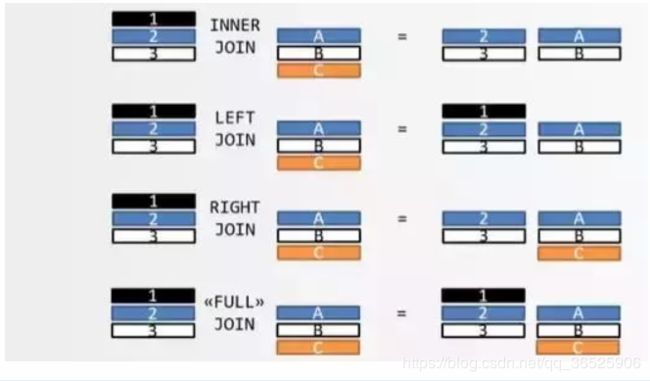
上图中,表 A 的记录是 123,表 B 的记录是 ABC,颜色表示匹配关系。返回结果中,如果另一张表没有匹配的记录,则用 null 填充。
这四种连接,又可以分成两大类:内连接(inner join)表示只包含匹配的记录,外连接(outer join)表示还包含不匹配的记录。所以,左连接、右连接、全连接都属于外连接。
此外,还存在一种特殊的连接,叫做"交叉连接"(cross join),指的是表 A 和表 B 不存在关联字段,这时表 A(共有 n 条记录)与表 B (共有 m 条记录)连接后,会产生一张包含 n x m 条记录的新表(见下图)。

常用:
left join
inner join
left join:以左表为基本表,右表关联不上用null替代
left join \ left semi join \ left outer join
left semi join 和 left join 区别:
1、都是左表连接,但是semi join右表关联不左表也不会出来,left join不一样
2、semi join只能查询左表信息,left join可以查询所有
3、semi join是left join的一种优化
4、semi join一般使用查询存在的情况
1.1 表查询
准备阶段:
准备数据
数据表hivedata1
1,a
2,b
3,c
4,d
7,y
8,u
数据表hivedata2
2,bb
3,cc
7,yy
9,pp
建表语句
create table if not exists u1(
id int,
name string
)
row format delimited fields terminated by ','
;
create table if not exists u2(
id int,
name string
)
row format delimited fields terminated by ','
;
导入数据
load data local inpath '/home/hivedata1' into table u1;
load data local inpath '/home/hivedata2' into table u2;
1.1.1 Join查询
- 查询u1表中存在,但是在u2表中不存在的(按id)
set hive.exec.mode.local.auto=true; -- 本地模式运行
select
u1.*
from u1 u1
left join u2 u2
on u1.id = u2.id
where u2.id is null
;
这里应用leftjoin:右表关联不上的用null代替
set hive.exec.mode.local.auto=true;
select
u1.*
from u1 u1
left outer join u2 u2 --左外链接
on u1.id = u2.id
where u2.id is null
;
查询结果:
左半连接
set hive.exec.mode.local.auto=true;
select
u1.id
from u1 u1
left semi join u2 u2 --左半连接
on u1.id = u2.id
;
相当于in,找到u1表中与u2相同的id
结果:
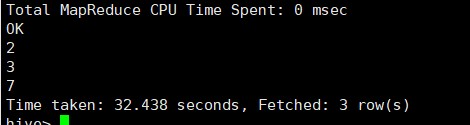
right semi join在hive中不支持,其它的right join\right outer join都支持。
full outer join取并集:
set hive.exec.mode.local.auto=true;
select
u1.*,
u2.*
from u1 u1
full outer join u2 u2
on u1.id = u2.id
;
按照id将两张表合并,且不匹配的字符按null处理
结果:

inner join 两表取交集,若有多张表加‘,’分割
set hive.exec.mode.local.auto=true;
select
u1.*,
u2.*
from u1 u1
inner join u2 u2
on u1.id = u2.id
;
结果:

小表标识:
hive提供小表标识:使用的是STREAMTABLE(小表别名)
当小表不得不放在右边时,我们可以给小标加上小表标识,这样就会把小表放进缓存里,执行时会更快
set hive.exec.mode.local.auto=true;
select
/*+STREAMTABLE(d)*/
d.name,
e.name
from u1 e
join u2 d
on d.id = e.id
;
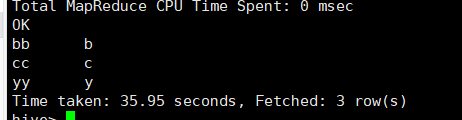
inner join 和outer join的区别:
分区字段对outer join 中的on条件是无效,对inner join 中的on条件有效
有inner join 但是没有full inner join , 有full outer join但是没有outer join
所有join连接,只支持等值连接(= 和 and )。不支持 != 、 < 、> 、 <> 、>=、 <= 、or
1.1.2 group by 、sort by 、cluster by
where后不能跟聚合函数,普通函数可以
group by :分组,通常和聚合函数搭配使用。
如果语句带group by子句,则 select后面的字段要么在group by中出现,要么在聚合函数里面。
一般有group by出现将会有reducetask。
Having : 分组以后的结果再次过滤。
limit : 取多少条。默认100000条,文件个数10个文件
cluster by :兼有distribute by以及sort by的升序功能。
排序只能是升序排序(默认排序规则),不能指定排序规则为asc 或者desc。
准备数据:数据量较大,此处comment表,创表语句为
create table if not exists comment(
id string,
commentid string,
dt string,
comm string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/wb.db/ods_bhv_comment'-- 约 5G数据
;
set hive.exec.mode.local.auto=true;
select
id,
commentid
from comment c
cluster by id
limit 10
;
set hive.exec.mode.local.auto=true;
select
id,
commentid
from comment c
distribute by id
sort by id asc
limit 10
;
distribute by : 根据by后的字段和reducer个数,决定map的输出去往那个reducer。
默认使用查询的第一列的hash值来决定map的输出去往那个reducer。如果reducer的个数为1时没有任何体现。
sort by:局部排序,只保证单个reducer有顺序。
order by:全局排序,保证所有reducer中的数据都是有顺序。
如果reduser个数只有一个,两者都差不多。
两者都通常和 desc 、 asc 搭配。默认使用升序asc。
手动设置reducer个数:
set mapreduce.job.reduces=2;
set hive.exec.mode.local.auto=true;
select
e.id,
e.name
from u1 e
order by e.id desc
;
set mapreduce.job.reduces=2;
set hive.exec.mode.local.auto=true;
select
e.id,
e.name
from u1 e
sort by e.id desc
;
order by的缺点:
由于是全局排序,所以所有的数据会通过一个Reducer 进行处理,当数据结果较大的时候,一个Reducer 进行处理十分影响性能。
sort by的特点:
常用于分组的时候的排序。
注意事项:
当开启MR 严格模式的时候ORDER BY 必须要设置 LIMIT 子句 ,否则会报错
只要使用order by ,reducer的个数将是1个。
如果sort by 和 distribute by 同时出现:那个在前面??
如果sort by 和 distribute by 同时出现,并且后面的字段一样、sort by使用升序时 <==> cluster by 字段
1.1.3 union 和 union all
union :将多个结果集合并,去重,排序
union all :将多个结果集合并,不去重,不排序。
单个union 语句不支持:orderBy、clusterBy、distributeBy、sortBy、limit
单个union语句字段的个数要求相同,字段的顺序要求相同、字段类型需要一样(union)。
union子句不支持group by\distribute by\order by (每个union子句嵌套中可以使用)
set mapreduce.job.reduces=1;
select
d.id as deptno,
d.name as dname
from u1 d
union
select
e.id as deptno,
e.name as dname
from u2 e
;
set mapreduce.job.reduces=1;
select
d.id as deptno,
d.name as dname
from u1 d
union all
select
e.id as deptno,
e.name as dname
from u2 e
;
1.1.4 复杂数据类型
array : col array<基本类型> ,下标从0开始,越界不报错,以NULL代替
map : column map
struct: col struct
array案例:
数据:
zhangsan 78,89,92,96
lisi 67,75,83,94
建表:
create table if not exists arr1(
name string,
score array<String>
)
row format delimited fields terminated by '\t'
;
注意terminated顺序,将集合中的数据分割??
create table if not exists arr2(
name string,
score array<String>
)
row format delimited fields terminated by '\t'
collection items terminated by ','
;

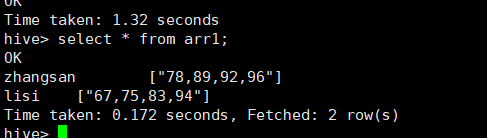
查询:
select
*
from arr2
where score[1] > 80;
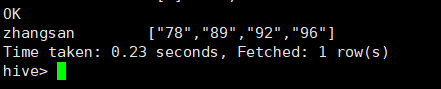
select
name,
score[1],
score[20]
from arr2
where score[1] > 80;

select
name,
score
from arr2
where size(score) > 3;

扩展查询:
zhangsan 78,89,92,96
zhangsan 78
zhangsan 89
zhangsan 92
zhangsan 96
内嵌查询:
explode:展开
explode(ARRAY) 列表中的每个元素生成一行
explode(MAP) map中每个key-value对,生成一行,key为一列,value为一列
select name,explode(score) score from arr2;
![]()
这里SELECT子句外不支持UDTF,也不能嵌套在表达式中
用lateral view解除以上限制
select
cj
from arr2
lateral view explode(score) score as cj
;
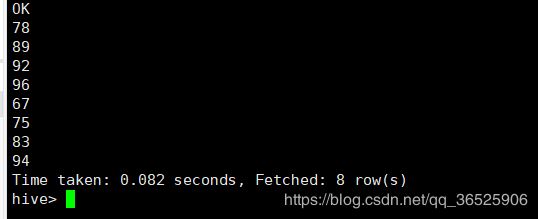
lateral view : 虚拟表
统计每个学生的总成绩:
select
name,
sum(cj) sum_cj
from arr2
lateral view explode(score) score as cj
group by name
;
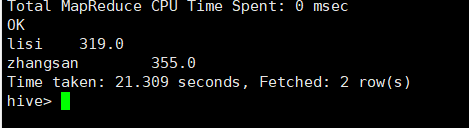
如何往array字段写入数据:
准备数据:
create table arr_temp
as
select name,cj from arr2 lateral view explode(score) score as cj;
1、collect_set函数:
create table if not exists arr3(
name string,
score array<int>
)
row format delimited fields terminated by ' '
collection items terminated by ','
;
将数据写成array格式:
insert into arr3
select
name,
collect_set(cast(cj as int))
from arr_temp
group by name;
insert into arr3
select
name,
collect_list(cast(cj as int))
from arr_temp
group by name;
map案例:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:
wangwu chinese:89,math:,english:81,nature:9
create table if not exists map2(
name string,
score map<string,int>
)
row format delimited fields terminated by ' '
collection items terminated by ','
map keys terminated by ':'
;
加载数据
load data local inpath '/home/hivedata/map' into table map2;
查询:
查询数学大于35分的学生的英语和自然成绩:
select
m.name,
m.score['english'] ,
m.score['nature']
from map2 m
where m.score['math'] > 35
;
展开数据:
-- explode
select explode(score) as (m_class,m_score) from map2;
使用lateral view explode结合查询:
select
name,
collect_list(concat_ws(":",m_class,cast(m_score as string)))
from map2
lateral view explode(score) score as m_class,m_score
group by name;