- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- 《Python数据分析实战终极指南》
xjt921122
python数据分析开发语言
对于分析师来说,大家在学习Python数据分析的路上,多多少少都遇到过很多大坑**,有关于技能和思维的**:Excel已经没办法处理现有的数据量了,应该学Python吗?找了一大堆Python和Pandas的资料来学习,为什么自己动手就懵了?跟着比赛类公开数据分析案例练了很久,为什么当自己面对数据需求还是只会数据处理而没有分析思路?学了对比、细分、聚类分析,也会用PEST、波特五力这类分析法,为啥
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- 自然语言处理_tf-idf
_feivirus_
算法机器学习和数学自然语言处理tf-idf逆文档频率词频
importpandasaspdimportmath1.数据预处理docA="Thecatsatonmyface"docB="Thedogsatonmybed"wordsA=docA.split("")wordsB=docB.split("")wordsSet=set(wordsA).union(set(wordsB))print(wordsSet){'on','my','face','sat',
- K近邻算法_分类鸢尾花数据集
_feivirus_
算法机器学习和数学分类机器学习K近邻
importnumpyasnpimportpandasaspdfromsklearn.datasetsimportload_irisfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportaccuracy_score1.数据预处理iris=load_iris()df=pd.DataFrame(data=ir
- python编写直方图和饼图
2301_80421078
python开发语言
1.直方图#直方图的绘制#语法格式:plt.hist(x,bins),其中x:数据集;bins:统计数据的分布区间importmatplotlib.pyplotaspltimportpandasaspd#导入文件excel=pd.read_excel('成绩.xlsx')#print(excel)#避免乱码plt.rcParams['font.sans-serif']=['SimHei']x=ex
- pythonpandas函数详解_Python pandas常用函数详解
Senvn
本文研究的主要是pandas常用函数,具体介绍如下。1import语句importpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltimportdatetimeimportre2文件读取df=pd.read_csv(path='file.csv')参数:header=None用默认列名,0,1,2,3...names=['A','B','C'
- python画出分子化学空间分布(UMAP)
Sakaiay
python
利用umap画出分子化学空间分布图安装pipinstallumap-learn下面是用一个数据集举的例子importtorchimportumapimportpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltimportseabornassnsfromsklearn.manifoldimportTSNEfromrdkit.Chemimport
- python读写CSV文件
bcbobo21cn
.Netpython开发语言机器学习CSV
做数据分析,有时候要分析的数据在CSV文件里;先看一下python读写CSV文件;importpandasaspddf=pd.read_csv('test1.csv')print(df)print('')print(df.head(2))companyname=["A1","B2","E3","F4"]legperson=["lier","yanqi","wangwu","zhangsan"]le
- python如何更方便的处理日期和时间
openwin_top
python编程示例系列python编程示例系列二pythonjava前端
Arrow是一个第三方Python库,提供了更加易用和方便的日期和时间处理接口。它的设计目标是提供一种简单、一致且易于使用的API,以替代Python内置的datetime模块。Arrow支持各种日期和时间的操作,包括时区转换、日期和时间格式化、日期和时间差计算等功能。它还支持与其他日期和时间库的互操作,例如datetime、dateutil和pandas等库。以下是一个使用Arrow库的简单示例
- python下载pandas库镜像_下载pandas库
weixin_39791152
背景交代:在下载matplotlib库时,我已经将pip的下载源手动更改为清华的镜像,所以,如果有小伙伴在下载库遇到问题,如timeout,请先将下载源改为国内镜像,具体操作见我的另一篇文章:今天的主题是安装pandas库~首先,按田字格+R,打开cmd,输入:pipinstallpandas嗯,不出所料地报错了……主要原因:pip._vendor.urllib3.exceptions.ReadT
- python数据分析知识点大全
编程零零七
python数据分析python开发语言python数据分析数据分析知识点大全python数据分析知识点python教程python基础
Python数据分析知识点大全可以归纳为以下几个主要方面:一、基础概念与目的数据分析定义:数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论,对数据加以详细研究和概括总结的过程。其目的在于从数据中挖掘规律、验证猜想、进行预测。Python在数据分析中的优势:Python因其易学性、快速开发、丰富的扩展库(如NumPy、Pandas等)和成熟的框架,成为数据分析领域的
- 如何“选择不同的“?跨越 pandas 中的多个数据框列?
潮易
pandas
在pandas中,如果你想要选择不同的列,你可以使用DataFrame的loc属性和iloc属性的组合。loc属性是基于标签的,iloc属性则是基于索引的。如果你想要选择多个列,你只需要将它们放入一个列表即可。以下是一个代码示例:```pythonimportpandasaspd#创建一个数据框df=pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]
- 详解 Pandas 的 query 函数
文刀小桂
Pandaspandaspython开发语言
Pandas的query()方法能够使用字符串表达式来筛选DataFrame数据的行,类似于SQL的where子句importpandasaspddf=pd.DataFrame({"A":[1,3,5,6,7],"B":[11,10,9,8,12],"C":["hello","pandas","python","java","shell"],"D":["2024-02-01","2023-12-1
- 详解 Pandas 的 isin 用法
文刀小桂
Pandaspandaspython
Pandas的isin()方法可以判断数据值是否在某个数据集合中,若与集合中的某个值相等则返回True,反之返回False。importpandasaspddf=pd.DataFrame({"title":["one","two","three","four"],"type":["small","common","middle","large"],"num":[10,20,30,40]})#1.判
- Rust: duckdb和polars读csv文件比较
songroom
rust开发语言后端
duckdb在数据分析上,有非常多不错的特质。1、快;2、客户体验好,特别是可以同时批量读csv(在一个目录下的csv等文件)。polars的性能比pandas有非常多的超越。但背后的一些基于arrow的技术栈有很多相同之类。今天想比较一下两者在csv数据读写的情况。一、文件准备csv样本内容,是N行9列的csv标准格式,有字符串,有浮点数,有整型。具体如下:本次准备了两个csv文件,一个大约是2
- groupby 中如何显示 tqdm 的进度条?
domodo2020
在循环时调用tqdm显示进度已经是一个常规操作,常见的方式是foriiintqdm(...):...while循环的情况类似,whileicntintqdm(range(n)):...icnt+=1这里记录没有显式循环时,在groupby中的用法:importpandasaspdimportnumpyasnpfromtqdmimporttqdmdf=pd.DataFrame(np.random.r
- pandas读取xlsx文件使用sqlachemy写到数据库
hzw0510
pandaspandas数据库
pandas读取xlsx文件使用sqlachemy写到数据库要使用pandas和SQLAlchemy将Excel文件中的数据读取到数据库中,你可以按照以下步骤进行操作:安装必要的库:确保你已经安装了pandas、SQLAlchemy和openpyxl(用于读取Excel文件)。可以使用以下命令安装:pipinstallpandassqlalchemyopenpyxl如果你使用的是特定的数据库(如S
- python 问题 ‘list‘ object cannot be interpreted as an integer 和‘int‘ object is not iterable
annekqiu
python
访问同一个excel表格(含有多个sheet)importnumpyasnpimportpandasaspdimportxlrd#读取excel的库importxlwt#写excel的库data=xlrd.open_workbook('./161005.xlsx')#打开excel文件读取数据table=data.sheets()[0]#读取sheet1h=table.ncols#获得列表数目a1
- 【Python】 写入Pandas DataFrame到CSV文件
civilpy
pythonpandas开发语言
基本原理Pandas是一个强大的Python数据分析库,它提供了许多用于数据处理和分析的功能。在处理数据时,我们经常需要将数据保存到文件中,以便后续使用或分享。CSV(Comma-SeparatedValues,逗号分隔值)文件是一种常见的数据交换格式,它以纯文本形式存储表格数据,每行表示一个数据记录,列之间用逗号分隔。DataFrame是Pandas中用于存储表格数据的主要数据结构。它类似于Ex
- Python酷库之旅-第三方库Pandas(115)
神奇夜光杯
pythonpandas开发语言人工智能标准库及第三方库excel学习与成长
目录一、用法精讲506、pandas.DataFrame.rank方法506-1、语法506-2、参数506-3、功能506-4、返回值506-5、说明506-6、用法506-6-1、数据准备506-6-2、代码示例506-6-3、结果输出507、pandas.DataFrame.round方法507-1、语法507-2、参数507-3、功能507-4、返回值507-5、说明507-6、用法507
- Python数据分析之股票信息可视化实现matplotlib
Blogfish
Python3大数据python可视化数据分析
今天学习爬虫技术数据分析对于股票信息的分析及结果呈现,目标是实现对股票信息的爬取并对数据整理后,生成近期成交量折线图。首先,做这个案例一定要有一个明确的思路。知道要干啥,知道用哪些知识,有些方法我也记不住百度下知识库很强大,肯定有答案。有思路以后准备对数据处理,就是几个方法使用了。接口地址参考:Tushare数据涉及知识库:tushare-一个财经数据开放接口;pandas-实现将数据整理为表格,
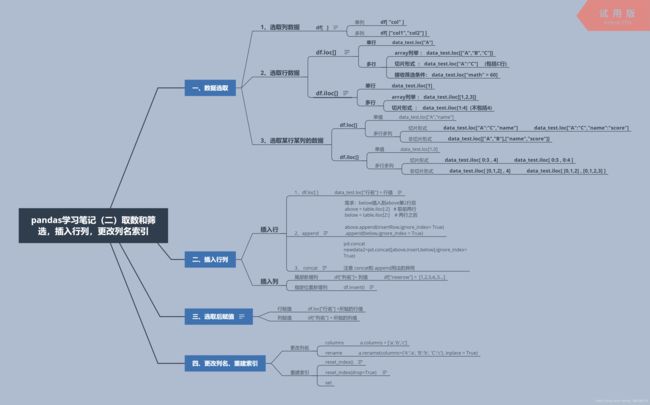
- pandas中的loc和iloc
白日与明月
python数据挖掘pandas
loc和iloc的比较.loc和.iloc是pandas提供的两种不同的索引方法,它们的主要区别在于索引数据的依据:.loc:基于标签的索引,使用DataFrame或Series的索引标签(即行名和列名)来获取数据。可以使用单个标签、标签列表、标签切片、布尔数组或者callable函数作为索引器。如果使用标签索引并且标签不存在,.loc会抛出一个KeyError。对于切片,包括两端的标签。.ilo
- pandas loc与iloc的区别
authorized_keys
数据处理pythonpandaslociloc
目录一、二者的特点二、官网原文三、例子——总有一款适合你一、二者的特点loc可用“字符”、“整数”、“布尔值”作为索引,也就是标签索引注意:此处的“整数”将被解释为index的一个label而不是index的位置iloc只允许“整数”作为索引,也就是位置索引,和列表索引类似,里面只能是数字注意:此处的“整数”将被解释为index的位置,前闭后开其中,loc是指location的意思,iloc中的i
- pandas中loc和iloc的区别
林光虚霁晓
数据分析pandas
在Pandas中,loc和iloc是用于选择和过滤数据的两种主要方法,它们的区别在于使用的索引类型。1.loc:基于标签索引loc是基于行或列的标签(label)来选择数据。它可以按行或列的名称来访问数据,也可以通过布尔索引选择。支持的索引类型:行标签、列标签、布尔索引。语法:DataFrame.loc[row_indexer,column_indexer]示例importpandasaspd#创
- seurat自学笔记1.0 单细胞数据导入
Sanye2022
pythonpandas
Python读取.h5ad文件importanndataimportpandasaspdadata=anndata.read("/home/R/R_data/Seurat/PBMC10/output/adata.h5ad")#adata.X.todense()#将稀疏矩阵转成普通矩阵#X=pd.DataFrame(adata.X.todense())#cell_name=adata.obs.ind
- Pandas教程:详解Pandas数据清洗
旦莫
PythonPandaspythonpandas数据分析
目录1.引言2.Pandas基础2.1安装与导入2.2创建一个复杂的DataFrame3.数据清洗流程3.1处理缺失值3.1.1删除缺失值3.1.2填充缺失值3.2数据去重3.3数据类型转换4.数据处理与变换4.1添加与删除列4.2数据排序5.数据分组与聚合6.其他数据清洗方法6.1字符串处理6.2时间序列处理6.3数据类型转换1.引言数据清洗是数据科学和数据分析中的一个重要步骤,旨在提升数据的质
- python的pandas库
帅维维
pythonpandas开发语言
什么是pandasPandas是一个开源的第三方Python库,它从Numpy和Matplotlib的基础上构建而来,享有数据分析“三剑客之一”的盛名。Pandas已经成为Python数据分析的必备高级工具,目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。数据结构Pandas中除了Panel数据结构,还引入了两种新的数据结构——Series和DataFrame,这两种数据结构都建立在Nu
- Python数据分析及可视化教程--商城订单为例-适用电商相关进行数据分析---亲测可用!!!!
Dreams°123
AIGC机器学习python测试工具数据分析大数据
前言:Python是进行数据分析和可视化的强大工具,常用的库包括Pandas、NumPy、Matplotlib和Seaborn。以下是一个基本的教程概述,介绍了如何使用这些库来进行数据分析和可视化:Python数据分析及可视化教程1、环境准备2、数据准备3、开始数据分析3.1、导入库3.2、加载数据3.3、数据预处理3.4、数据分析3.5、数据可视化4、总结解释使用方法:5、错误处理和异常判断说明
- python第三方库手动安装教程_为了应对异常情况,提供最原始的python第三方库的安装方法:手动安装。往往是Windows用户需要用到这种方法。...
weixin_39735247
进入pypi.python.org,搜索你要安装的库的名字,这时候有3中可能:第一种是exe文件,这种最方便,下载满足你的电脑系统和python环境的对应的exe,再一路点击next就可以安装。第二种是.whl类文件,好处在于可以自动安装依赖包。第三种是源码,大概都是zip、tar.zip、tar.bz2格式的压缩包,这个方法要求用户已经安装了这个包所依赖的其他包。例如pandas依赖于numpy
- Java序列化进阶篇
g21121
java序列化
1.transient
类一旦实现了Serializable 接口即被声明为可序列化,然而某些情况下并不是所有的属性都需要序列化,想要人为的去阻止这些属性被序列化,就需要用到transient 关键字。
- escape()、encodeURI()、encodeURIComponent()区别详解
aigo
JavaScriptWeb
原文:http://blog.sina.com.cn/s/blog_4586764e0101khi0.html
JavaScript中有三个可以对字符串编码的函数,分别是: escape,encodeURI,encodeURIComponent,相应3个解码函数:,decodeURI,decodeURIComponent 。
下面简单介绍一下它们的区别
1 escape()函
- ArcgisEngine实现对地图的放大、缩小和平移
Cb123456
添加矢量数据对地图的放大、缩小和平移Engine
ArcgisEngine实现对地图的放大、缩小和平移:
个人觉得是平移,不过网上的都是漫游,通俗的说就是把一个地图对象从一边拉到另一边而已。就看人说话吧.
具体实现:
一、引入命名空间
using ESRI.ArcGIS.Geometry;
using ESRI.ArcGIS.Controls;
二、代码实现.
- Java集合框架概述
天子之骄
Java集合框架概述
集合框架
集合框架可以理解为一个容器,该容器主要指映射(map)、集合(set)、数组(array)和列表(list)等抽象数据结构。
从本质上来说,Java集合框架的主要组成是用来操作对象的接口。不同接口描述不同的数据类型。
简单介绍:
Collection接口是最基本的接口,它定义了List和Set,List又定义了LinkLi
- 旗正4.0页面跳转传值问题
何必如此
javajsp
跳转和成功提示
a) 成功字段非空forward
成功字段非空forward,不会弹出成功字段,为jsp转发,页面能超链接传值,传输变量时需要拼接。接拼接方式list.jsp?test="+strweightUnit+"或list.jsp?test="+weightUnit+&qu
- 全网唯一:移动互联网服务器端开发课程
cocos2d-x小菜
web开发移动开发移动端开发移动互联程序员
移动互联网时代来了! App市场爆发式增长为Web开发程序员带来新一轮机遇,近两年新增创业者,几乎全部选择了移动互联网项目!传统互联网企业中超过98%的门户网站已经或者正在从单一的网站入口转向PC、手机、Pad、智能电视等多端全平台兼容体系。据统计,AppStore中超过85%的App项目都选择了PHP作为后端程
- Log4J通用配置|注意问题 笔记
7454103
DAOapachetomcatlog4jWeb
关于日志的等级 那些去 百度就知道了!
这几天 要搭个新框架 配置了 日志 记下来 !做个备忘!
#这里定义能显示到的最低级别,若定义到INFO级别,则看不到DEBUG级别的信息了~!
log4j.rootLogger=INFO,allLog
# DAO层 log记录到dao.log 控制台 和 总日志文件
log4j.logger.DAO=INFO,dao,C
- SQLServer TCP/IP 连接失败问题 ---SQL Server Configuration Manager
darkranger
sqlcwindowsSQL ServerXP
当你安装完之后,连接数据库的时候可能会发现你的TCP/IP 没有启动..
发现需要启动客户端协议 : TCP/IP
需要打开 SQL Server Configuration Manager...
却发现无法打开 SQL Server Configuration Manager..??
解决方法: C:\WINDOWS\system32目录搜索framedyn.
- [置顶] 做有中国特色的程序员
aijuans
程序员
从出版业说起 网络作品排到靠前的,都不会太难看,一般人不爱看某部作品也是因为不喜欢这个类型,而此人也不会全不喜欢这些网络作品。究其原因,是因为网络作品都是让人先白看的,看的好了才出了头。而纸质作品就不一定了,排行榜靠前的,有好作品,也有垃圾。 许多大牛都是写了博客,后来出了书。这些书也都不次,可能有人让为不好,是因为技术书不像小说,小说在读故事,技术书是在学知识或温习知识,有些技术书读得可
- document.domain 跨域问题
avords
document
document.domain用来得到当前网页的域名。比如在地址栏里输入:javascript:alert(document.domain); //www.315ta.com我们也可以给document.domain属性赋值,不过是有限制的,你只能赋成当前的域名或者基础域名。比如:javascript:alert(document.domain = "315ta.com");
- 关于管理软件的一些思考
houxinyou
管理
工作好多看年了,一直在做管理软件,不知道是我最开始做的时候产生了一些惯性的思维,还是现在接触的管理软件水平有所下降.换过好多年公司,越来越感觉现在的管理软件做的越来越乱.
在我看来,管理软件不论是以前的结构化编程,还是现在的面向对象编程,不管是CS模式,还是BS模式.模块的划分是很重要的.当然,模块的划分有很多种方式.我只是以我自己的划分方式来说一下.
做为管理软件,就像现在讲究MVC这
- NoSQL数据库之Redis数据库管理(String类型和hash类型)
bijian1013
redis数据库NoSQL
一.Redis的数据类型
1.String类型及操作
String是最简单的类型,一个key对应一个value,string类型是二进制安全的。Redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
Set方法:设置key对应的值为string类型的value
- Tomcat 一些技巧
征客丶
javatomcatdos
以下操作都是在windows 环境下
一、Tomcat 启动时配置 JAVA_HOME
在 tomcat 安装目录,bin 文件夹下的 catalina.bat 或 setclasspath.bat 中添加
set JAVA_HOME=JAVA 安装目录
set JRE_HOME=JAVA 安装目录/jre
即可;
二、查看Tomcat 版本
在 tomcat 安装目
- 【Spark七十二】Spark的日志配置
bit1129
spark
在测试Spark Streaming时,大量的日志显示到控制台,影响了Spark Streaming程序代码的输出结果的查看(代码中通过println将输出打印到控制台上),可以通过修改Spark的日志配置的方式,不让Spark Streaming把它的日志显示在console
在Spark的conf目录下,把log4j.properties.template修改为log4j.p
- Haskell版冒泡排序
bookjovi
冒泡排序haskell
面试的时候问的比较多的算法题要么是binary search,要么是冒泡排序,真的不想用写C写冒泡排序了,贴上个Haskell版的,思维简单,代码简单,下次谁要是再要我用C写冒泡排序,直接上个haskell版的,让他自己去理解吧。
sort [] = []
sort [x] = [x]
sort (x:x1:xs)
| x>x1 = x1:so
- java 路径 配置文件读取
bro_feng
java
这几天做一个项目,关于路径做如下笔记,有需要供参考。
取工程内的文件,一般都要用相对路径,这个自然不用多说。
在src统计目录建配置文件目录res,在res中放入配置文件。
读取文件使用方式:
1. MyTest.class.getResourceAsStream("/res/xx.properties")
2. properties.load(MyTest.
- 读《研磨设计模式》-代码笔记-简单工厂模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 个人理解:简单工厂模式就是IOC;
* 客户端要用到某一对象,本来是由客户创建的,现在改成由工厂创建,客户直接取就好了
*/
interface IProduct {
- SVN与JIRA的关联
chenyu19891124
SVN
SVN与JIRA的关联一直都没能装成功,今天凝聚心思花了一天时间整合好了。下面是自己整理的步骤:
一、搭建好SVN环境,尤其是要把SVN的服务注册成系统服务
二、装好JIRA,自己用是jira-4.3.4破解版
三、下载SVN与JIRA的插件并解压,然后拷贝插件包下lib包里的三个jar,放到Atlassian\JIRA 4.3.4\atlassian-jira\WEB-INF\lib下,再
- JWFDv0.96 最新设计思路
comsci
数据结构算法工作企业应用公告
随着工作流技术的发展,工作流产品的应用范围也不断的在扩展,开始进入了像金融行业(我已经看到国有四大商业银行的工作流产品招标公告了),实时生产控制和其它比较重要的工程领域,而
- vi 保存复制内容格式粘贴
daizj
vi粘贴复制保存原格式不变形
vi是linux中非常好用的文本编辑工具,功能强大无比,但对于复制带有缩进格式的内容时,粘贴的时候内容错位很严重,不会按照复制时的格式排版,vi能不能在粘贴时,按复制进的格式进行粘贴呢? 答案是肯定的,vi有一个很强大的命令可以实现此功能 。
在命令模式输入:set paste,则进入paste模式,这样再进行粘贴时
- shell脚本运行时报错误:/bin/bash^M: bad interpreter 的解决办法
dongwei_6688
shell脚本
出现原因:windows上写的脚本,直接拷贝到linux系统上运行由于格式不兼容导致
解决办法:
1. 比如文件名为myshell.sh,vim myshell.sh
2. 执行vim中的命令 : set ff?查看文件格式,如果显示fileformat=dos,证明文件格式有问题
3. 执行vim中的命令 :set fileformat=unix 将文件格式改过来就可以了,然后:w
- 高一上学期难记忆单词
dcj3sjt126com
wordenglish
honest 诚实的;正直的
argue 争论
classical 古典的
hammer 锤子
share 分享;共有
sorrow 悲哀;悲痛
adventure 冒险
error 错误;差错
closet 壁橱;储藏室
pronounce 发音;宣告
repeat 重做;重复
majority 大多数;大半
native 本国的,本地的,本国
- hibernate查询返回DTO对象,DTO封装了多个pojo对象的属性
frankco
POJOhibernate查询DTO
DTO-数据传输对象;pojo-最纯粹的java对象与数据库中的表一一对应。
简单讲:DTO起到业务数据的传递作用,pojo则与持久层数据库打交道。
有时候我们需要查询返回DTO对象,因为DTO
- Partition List
hcx2013
partition
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x.
You should preserve the original relative order of th
- Spring MVC测试框架详解——客户端测试
jinnianshilongnian
上一篇《Spring MVC测试框架详解——服务端测试》已经介绍了服务端测试,接下来再看看如果测试Rest客户端,对于客户端测试以前经常使用的方法是启动一个内嵌的jetty/tomcat容器,然后发送真实的请求到相应的控制器;这种方式的缺点就是速度慢;自Spring 3.2开始提供了对RestTemplate的模拟服务器测试方式,也就是说使用RestTemplate测试时无须启动服务器,而是模拟一
- 关于推荐个人观点
liyonghui160com
推荐系统关于推荐个人观点
回想起来,我也做推荐了3年多了,最近公司做了调整招聘了很多算法工程师,以为需要多么高大上的算法才能搭建起来的,从实践中走过来,我只想说【不是这样的】
第一次接触推荐系统是在四年前入职的时候,那时候,机器学习和大数据都是没有的概念,什么大数据处理开源软件根本不存在,我们用多台计算机web程序记录用户行为,用.net的w
- 不间断旋转的动画
pangyulei
动画
CABasicAnimation* rotationAnimation;
rotationAnimation = [CABasicAnimation animationWithKeyPath:@"transform.rotation.z"];
rotationAnimation.toValue = [NSNumber numberWithFloat: M
- 自定义annotation
sha1064616837
javaenumannotationreflect
对象有的属性在页面上可编辑,有的属性在页面只可读,以前都是我们在页面上写死的,时间一久有时候会混乱,此处通过自定义annotation在类属性中定义。越来越发现Java的Annotation真心很强大,可以帮我们省去很多代码,让代码看上去简洁。
下面这个例子 主要用到了
1.自定义annotation:@interface,以及几个配合着自定义注解使用的几个注解
2.简单的反射
3.枚举
- Spring 源码
up2pu
spring
1.Spring源代码
https://github.com/SpringSource/spring-framework/branches/3.2.x
注:兼容svn检出
2.运行脚本
import-into-eclipse.bat
注:需要设置JAVA_HOME为jdk 1.7
build.gradle
compileJava {
sourceCompatibilit
- 利用word分词来计算文本相似度
yangshangchuan
wordword分词文本相似度余弦相似度简单共有词
word分词提供了多种文本相似度计算方式:
方式一:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度
实现类:org.apdplat.word.analysis.CosineTextSimilarity
用法如下:
String text1 = "我爱购物";
String text2 = "我爱读书";
String text3 =