爬虫的解析
在Pytho2.x中使用import urllib.quote——-对应的,在Python3.x中应该使用import urllib.prase.quote而不是urllib.request.quote
Urllib库是Python中的一个功能强大、用于操作URL,并在做爬虫的时候经常要用到的库。在Python2.x中,分为Urllib库和Urllin2库,Python3.x之后都合并到Urllib库中,使用方法稍有不同。本文介绍的是Python3中的urllib库。
什么是Urllib库
Urllib是Python提供的一个用于操作URL的模块,我们爬取网页的时候,经常需要用到这个库。
升级合并后,模块中的包的位置变化的地方较多。在此,列举一些常见的位置变动,方便之前用Python2.x的朋友在使用Python3.x的时候可以快速掌握。
常见的变化有:
- 在Pytho2.x中使用import urllib2——-对应的,在Python3.x中会使用import urllib.request,urllib.error。
- 在Pytho2.x中使用import urllib——-对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse。
- 在Pytho2.x中使用import urlparse——-对应的,在Python3.x中会使用import urllib.parse。
- 在Pytho2.x中使用import urlopen——-对应的,在Python3.x中会使用import urllib.request.urlopen。
- 在Pytho2.x中使用import urlencode——-对应的,在Python3.x中会使用import urllib.parse.urlencode。
- 在Pytho2.x中使用import urllib.quote——-对应的,在Python3.x中会使用import urllib.request.quote。
- 在Pytho2.x中使用cookielib.CookieJar——-对应的,在Python3.x中会使用http.CookieJar。
- 在Pytho2.x中使用urllib2.Request——-对应的,在Python3.x中会使用urllib.request.Request。
快速使用Urllib爬取网页
以上我们对Urllib库做了简单的介绍,接下来讲解如何使用Urllib快速爬取一个网页。
首先需要导入用到的模块:urllib.request
import urllib.request在导入了模块之后,我们需要使用urllib.request.urlopen打开并爬取一个网页,此时,可以输入如下代码爬取百度首页(www.baidu.com),爬取后,将爬取的网页赋给了变量file:
>>>file=urllib.request.urlopen('www.baidu.com')此时,我们还需要将对应的网页内容读取出来,可以使用file.read()读取全部内容,或者也可以使用file.readline()读取一行内容。
>>>data=file.read() #读取全部
>>>dataline=file.readline() #读取一行内容读取内容常见的有3种方式,其用法是:
1. read()读取文件的全部内容,与readlines()不同的是,read()会把读取到的内容赋给一个字符串变量。
2. readlines()读取文件的全部内容,readlines()会把读取到的内容赋值给一个列表变量。
3. readline()读取文件的一行内容。
此时,我们已经成功实现了一个网页的爬取,那么我们如何将爬取的网页以网页的形式保存在本地呢?
思路如下:
1. 爬取一个网页并将爬取到的内容读取出来赋给一个变量。
2. 以写入的方式打开一个本地文件,命名为*.html等网页格式。
3. 将步骤1中的变量写入该文件中。
4. 关闭该文件
我们刚才已经成功获取到了百度首页的内容并读取赋给了变量data,接下来,可以通过以下代码实现将爬取到的网页保存在本地。
>>>fhandle=open("./1.html","wb")
>>>fhandle.write(data)
>>>fhandle.close()此时,1.html已窜在我们指定的目录下,用浏览器打开该文件,就可以看到我们爬取的网页界面。
除此之外,urllib中还有一些常见的用法。
如果希望返回与当前环境有关的信息,我们可以使用info()返回,比如可以执行:
>>>file.info()
可以看到,输出了对应的info,调用格式则为:“爬取的网页.info()”,我们之前爬取到的网页赋给了变量file,所以此时通过file调用。
如果我们希望获取当前爬取网页的状态码,我们可以使用getcode(),若返回200为正确,返回其他则不正确。在该例中,我们可以执行:
>>>file.getcode()
200如果想要获取当前所爬取的URL地址,我们可以使用geturl()来实现。
>>>file.geturl()
'http://www.baidu.com'一般来说,URL标准中只会允许一部分ASCII字符比如数字、字母、部分符号等,而其他的一些字符,比如汉字等,是不符合URL标准的。此时,我们需要编码。
如果要进行编码,我们可以使用urllib.request.quote()进行,比如,我们如果要对百度网址进行编码:
>>>urllib.request.quote('http://www.baidu.com')
'http%3A//www.baidu.com'那么相应的,有时候需要对编码的网址进行解码
>>>urllib.request.unquote('http%3A//www.baidu.com')
'http://www.baidu.com'
浏览器的模拟—Headers属性
有的时候,我们无法爬取一些网页,会出现403错误,因为这些网页为了防止别人恶意采集其信息所以进行了一些反爬虫的设置。
那么如果我们向爬取这些网页的信息,应该怎么办呢?
可以设置一些Headers信息,模拟成浏览器去访问这些网站,此时,就能够解决这个问题了。
那我们该添加什么头部信息呢?
我们需要让爬虫模拟成浏览器,模拟成浏览器可以设置User-Agent信息。
任意打开一个网页,比如打开百度。然后按F12,会出现一个窗口。切换到Network标签页:
然后单击网页中的“百度一下”,即让网页发生一个动作。
此时,我们可以观察到下方的窗口出现了一些数据。将界面右上方的标签切换到“Headers”中,即可以看到了对应的头信息,此时往下拖动,就可以找到User-Agent字样的一串信息。这一串信息即是我们下面模拟浏览器所需要用到的信息。我们将其复制出来。如图: 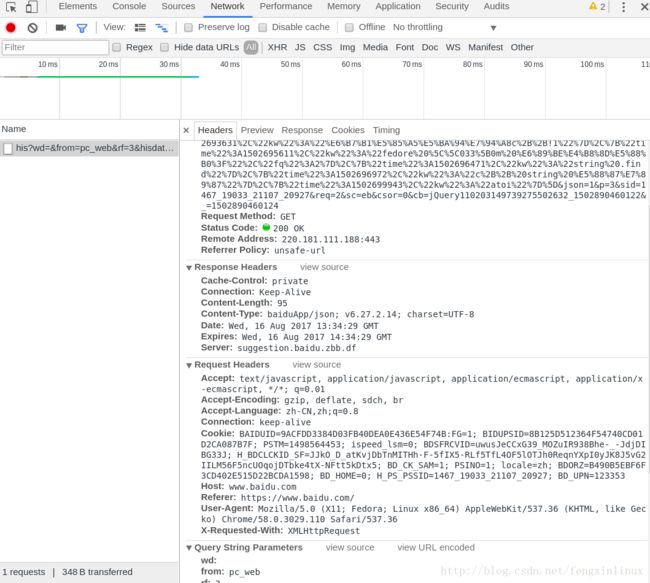
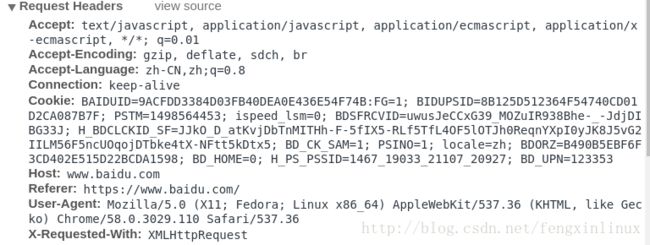
我们可以得到该信息:
User-Agent:Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
X-Requested-With:XMLHttpRequest接下来,我们讲解如何让爬虫模拟成浏览器访问页面的设置方法。
import urllib.request
import urllib.parse
url='http://www.baidu.com'
hearder={
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
request=urllib.request.Request(url,headers=header)
reponse=urllib.request.urlopen(request).read()
fhandle=open("./1.html","wb")
fhandle.write(reponse)
fhandle.close()
首先,设置要爬取的网址,然后调用urllib.request.Request()函数创建一个request对象,该函数第一个参数传入url,第二个参数可以传入数据,默认是传入0数据,第三个参数是传入头部,该参数也是有默认值的,默认是不传任何头部。
我们需要创建一个dict,将头部信息以键值对的形式存入到dict对象中,然后将该dict对象传入urllib.request.Request()函数第三个参数。
此时,已经成功设置好报头,然后我们使用urlopen()打开该Request对象即可打开对应的网址。
超时设置
有的时候,我们访问一个网页,如果该网页长时间未响应,那么系统就会判断该网页超时了,即无法打开该网页。
有的时候,我们需要根据自己的需要来设置超时的时间值。我们可以在urllib.request.urlopen()打开网址的时候,通过timeout字段设置。
设置格式为:urllib.request.urlopen(要打开的网址,timeout=时间值)。
HTTP协议请求实战
如果要进行客户端与服务器端之间的消息传递,我们可以使用HTTP协议请求进行。
HTTP协议请求主要分为6种类型,各类型的主要作用如下:
- GET请求:GET请求会通过URL网址传递信息,可以直接在URL中写上要传递的信息,也可以由表单进行传递。如果使用表单进行传递,这表单中的信息会自动转为URL地址中的数据,通过URL地址传递。
- POST请求:可以向服务器提交数据,是一种比较主流也比较安全的数据传递方式,比如在登录时,经常使用POST请求发送数据。
- PUT请求:请求服务器存储一个资源,通常要指定存储的位置。
- DELETE请求:请求服务器删除一个资源。
- HEAD请求:请求获取对应的HTTP报头信息。
- OPTIONS请求:可以获取当前URL所支持的请求类型。
除此之外,还有TRACE请求与CONNECT请求等。
接下来,将通过实例讲解HTTP协议请求中的GET请求和POST请求,这两种请求相对来说用的最多。
GET请求示例分析
有时想在百度上查询一个关键词,我们会打开百度首页,并输入该关键词进行查询,那么这个过程怎样使用爬虫自动实现呢?
我们首先需要对查询过程进行相应的分析,可以打开百度首页,然后输入想检索的关键词,比如输入“hello”,然后按回车键,我们观察一下URL的变化,此时URL变成:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=hello
可以发现,对应的查询信息是通过URL传递的,这里采用的就是HTTP请求中的GET请求方法,我们将该网址提取出来进行分析,字段ie的值为utf8,代表的是编码信息,而字段wd为hello,刚好是我们要查询的信息,所以字段wd应该存储的就是用户检索的关键词。根据我们的猜测,化简一下该网址,可以化简为https://www.baidu.com/s?wd=hello,将该网址复制到浏览器中,刷新一下,会发现该网址也能够出现关键词为‘hello’的搜索结果。
由此可见,我们在百度上查询一个关键字时,会使用GET请求,其中关键性字段是wd,网址格式为:https://www.baidu.com/s?wd=关键词。
分析到这里,你应该大概知道我们该怎么用爬虫实现自动地在百度上查询关键词结果了。直接上代码~
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
url='http://www.baidu.com/s?wd='
key='fengxin的博客'
key_code=urllib.request.quote(key) #因为URL里含中文,需要进行编码
url_all=url+key_code
header={
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
request=urllib.request.Request(url_all,headers=header)
reponse=urllib.request.urlopen(request).read()
fh=open("./baidu.html","wb") #写入文件中
fh.write(reponse)
fh.close()
此时,我们用浏览器打开刚才保存的baidu.html文件,我们就可以看到我们刚才爬取的网页结果,如图: 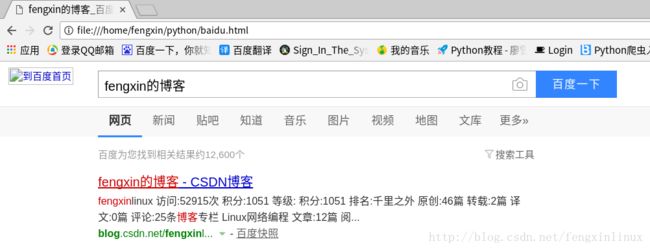
通过以上实例我们可以知道,如果要使用GET请求,思路如下:
- 构建对应的URL地址,该URL地址包含GET请求的字段名和字段内容等信息,并且URL地址满足GET请求的格式,即“http://网址?字段名1=字段内容1&字段名2=字段内容2”
- 以对应的URL为参数,构建Request对象。
- 通过urlopen()打开构建的Request对象。
- 按需求进行后续的处理操作,比如读取网页的内容、将内容写入文件等。
POST请求实例分析
我们在进行注册、登录等操作的时候,基本上都会遇到POST请求,接下来我们就为大家通过实例来分析如何通过爬虫来实现POST请求。
在此,我们示例一下如何使用爬虫通过POST表单传递信息。
给大家提供一个POST表单的测试网页,做测试使用,网址为:
http://www.iqianyue.com/mypost
打开网址,会发现有一个表单。 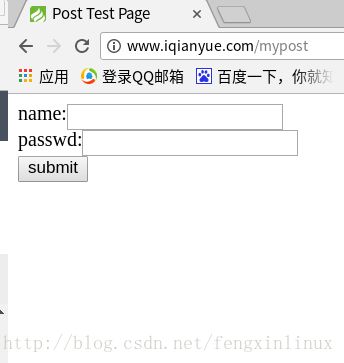
如何通过爬虫自动实现这个传递过程呢?
因为这里所采用的传递方法是POST方法,所以如果要使用爬虫自动实现,我们要构造PSOT请求,实现思路如下:
- 设置好URL网址。
- 构建表单数据,并使用urllib.parse.urlencode对数据进行编码处理。
- 构建Request对象,参数包括URL地址和要传递的数据。
- 添加头部信息,模拟浏览器进行爬取。
- 使用urllib.requesr.urlopen()打开对应的Request对象。完成信息的传递。
- 后续处理,比如读取网页内容,将内容写入文件等。
首先,需要设置好对应的URL地址,分析该网页,在单击提交之后,会传递到当前页面进行处理,所以处理的页面应该是http://www.iqianyue.com/mypost,所以,URL应该设置为http://www.iqianyue.com/mypost。
然后我们需要构建表单数据,在该网页上右击“查看网页源代码”,找到对应的form表单部分,然后进行分析。如图: 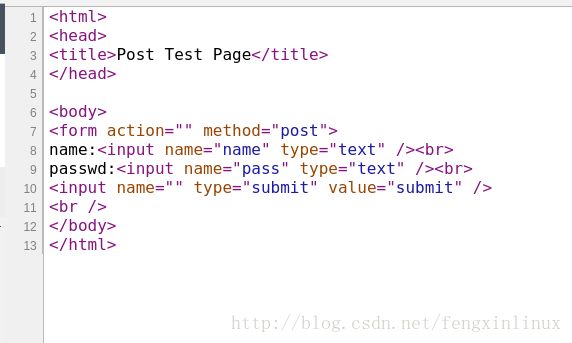
可以发现,表单中的姓名对应的输入框中,name属性值为”name”,密码对应的输入框中,name属性值为”pass”,所以,我们构造的数据中会包含两个字段,字段名分别是”name”,”pass’。字段值设置我们要传递的信息。格式为字典形式,即:
{字段名1:字段值1,字段名2:字段值2,…..}
其他的跟上面的GET请求类似,直接上代码~
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
url='http://www.iqianyue.com/mypost'
header={
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
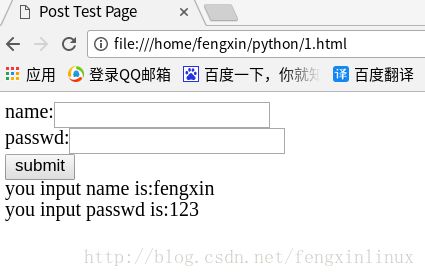
data={'name':'fengxin','pass':'123'}
postdata=urllib.parse.urlencode(data).encode('utf8') #进行编码
request=urllib.request.Request(url,postdata)
reponse=urllib.request.urlopen(request).read()
fhandle=open("./1.html","wb")
fhandle.write(reponse)
fhandle.close()
在浏览器中打开我们刚保存的1.html文件,可以看到,数据已经成功提交。