java web面试题(一)
1、Tomcat优化经验
参考解答:http://blog.csdn.net/itcast_cn/article/details/48949233
1、去掉对web.xml的监视,把jsp提前编辑成Servlet
有富余物理内存情况下,加大tmocat使用的jvm的内存
2、服务器资源配置
1)CPU的性能,在高并发的情况下,直接影响处理速度
2)大数据处理下,对内存需求大,可以用-Xmx -Xms -XX:MaxPermSize等对内存不同功能块进行划分
经常性内存不足,会导致经常性full GC,影响性能3)对大数据文件进行磁盘读取,磁盘常常是性能瓶颈,最好用缓存
3、利用缓存和压缩
1)静态页面最好缓存,这样不用每次从磁盘访问
nginx可以做缓存服务器,缓存图片、css、js等资源,减少后端tomcat访问2)开启gzip压缩能加快网络传输速度,可以将压缩工作交给前端Ngix来完成,减少tmocat工作
4、采用集群
横向扩展,组建tomcat集群能有效提升性能
5、优化tomcat的参数
主要是优化连接配置,关闭客户端dns等
2、Http中Get和Post的区别
http://blog.csdn.net/yipiankongbai/article/details/24025633
Http定义了与服务器交互的不同方法
最基本的是:GET\POST\PUT\DELETE\HEAD
GET\HEAD是安全的方法,一般只是请求服务器的数据
而POST是不安全的,因为可能修改服务器的数据
3、什么是Servlet
sevelet有良好的生命周期
包括:加载、实例化、初始化、处理请求、服务结束
其生命周期由javax.servlet.Servlet接口的init、service、destroy表达
是开发动态web资源的技术
通常将实现了servlet的类叫Servlet
步骤:
1、编写java类,实现servlet接口
2、将该类部署到web服务器
Sevlet运行过程:
它由web服务器调用,当web服务器接收到客户端的访问请求
1、web服务器检查是否已经装载并创建了该Servlet的实例对象
2、若没有,则装载并创建Servlet实例
3、调用实例对象的init()
4、创建一个用与封装HTTP请求消息的HttpServletRequest对象和
相应消息对象HttpServletResponse,再调用service(),将请求和响应传入
5、web应用程序被停止or重启前,Servlet引擎将卸载Servlet,在卸载前调用destroy()
浏览器发送一个HTTP请求,请求被Web容器分配给特定的Servlet处理
Servletz本质就是拥有一系列可以处理HTTP请求的方法的对象,常见方法doGet()/doPost()
web容器包含多个Servlet,特定的HTTP请求由那个Servlet处理由web.xml决定
Sevlet生命周期:
1、web容器加载servlet,开始生命周期
2、调用init()初始化
3、调用service(),该方法会根据请求的不同调用不同的do**()
4、结束服务时,调用destroy()
实现:
extends HttpServlet
4、forward()和redirect()
http://blog.csdn.net/tenor/article/details/4077079
forward():
容器中控制权的转向,是服务器内部重定向
他是直接读取url中的内容显示,所以地址栏地址不会变
其request值不变
更高效、便于隐藏实际链接
redirect():
告诉客户端,重新发送请求链接,地址栏显示转发后的地址
等于客户端会发送两次request
若要请求跳转别的服务器资源,只能用此
Request范围的对象,能被forward访问,不能被redirect访问
5、request.getAttribute() 和 request.getParameter() 区别?
http://blog.csdn.net/zhaohongjuan/article/details/53641160
getParameter:
取得的是通过容器的实现来取得类似Post、get方式传入的数据取得的是通过容器的实现来取得类似Post、get方式传入的数据
数据从web客户端流转到服务端
getAttribute:
在web容器内部流转,仅仅是请求处理阶段
要get,先要set
在进行转发的时候,可以通过设置attribute来实现Request范围的数据共享
6、页面间对象传递的方法
http://www.jb51.net/article/105355.htm
request
session
application
cookie
url(url参数)
form(提交表单)
url/form:只能传字符串
request/session/application/cookie:可传对象
url/request:在请求页面获得数据
session/application/cookie:多页面共享
session/cookie:保存用户相关信息
session:保存到服务器内存
cookie:保存到客户端内存
application:保存所有用户相关的信息,保存在服务器内存
7、JSP vs Sevlet
JSP:
1、是Sevlet的扩展,本质是Sevlet的简易形式
2、编译后是"类servlet"
3、java和html组合成.jsp的文件
jsp侧重视图
Servlet侧重控制逻辑
8、MVC 的各个部分都有那些技术来实现?如何实现?
Model:业务逻辑,通过JavaBean,EJB组件实现
View:表示层,JSP页面产生
Controller:控制层,一般是一个Servlet
以上组件可以交互和重用
9、我们在web应用开发过程中经常遇到输出某种编码的字符,如iso8859-1等,如何输出一个某种编码的字符串?
public String translate(String str){//对传入的str字符串进行转换
String tempStr = "";
try{
tempStr = new String(str.getBytes("ISO-8859-1"), "GBK");//把"ISO-8859-1"转化为“GBK”编码
tempStr = tempStr.trim();
}catch (Exception e){
System.err.println(e.getMessage());
}
return tempStr;
}10、.数据库事务和锁的概念
数据库事务的ACID特性
1. 事务的四个特性
数据库事务(Transaction)是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。一方面,当多个应用程序并发访问数据库时,事务可以在应用程序间提供一个隔离方法,防止互相干扰。另一方面,事务为数据库操作序列提供了一个从失败恢复正常的方法。
事务具有四个特性:原子性(Atomicity)、一致性(Consistency)、隔离型(Isolation)、持久性(Durability),简称ACID。
1.1 原子性(Atomicity)
事务的原子性是指事务中的操作不可拆分,只允许全部执行或者全部不执行。
1.2 一致性(Consistency)
事务的一致性是指事务的执行不能破坏数据库的一致性,一致性也称为完整性。一个事务在执行后,数据库必须从一个一致性状态转变为另一个一致性状态。
1.3 隔离型(Isolation)
事务的隔离型是指并发的事务相互隔离,不能互相干扰。
1.4 持久性(Durability)
事务的持久性是指事务一旦提交,对数据的状态变更应该被永久保存。
数据库事务隔离级别
原文链接:数据库事务隔离级别
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted 、Read committed 、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。
√: 可能出现 ×: 不会出现
什么是事务(Transaction)?是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。 事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。事务是数据库运行中的一个逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。 举个例子加深一下理解:同一个银行转账,A转1000块钱给B,这里存在两个操作,一个是A账户扣款1000元,两一个操作是B账户增加1000元,两者就构成了转账这个事务。
最后思考一下,怎么样会出现A账户扣款1000元,B账户金额不变?如果你是把两个操作放在一个事务里面,并且是数据库提供的内在事务支持,那就不会有问题,但是开发人员把两个操作放在两个事务里面,而第二个事务失败就会出现中间状态。现实中自己实现的分布式事务处理不当也会出现中间状态,这并不是事务的错,事务本身就是规定不会出现中间状态,是事务实现者做出来的方案有问题。 事务的4个特性
事务并发控制我们从另外一个方向来说说,如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形,有些使我们可以接受的,有些是不能接受的,注意这里的异常就是特定语境下的,并不一定就是错误什么的。假设有一个order表,有个字段叫count,作为计数用,当前值为100
数据库事务隔离级别看到上面提到的几种问题,你可能会想,我擦,这么多坑怎么办啊。其实上面几种情况并不是一定都要避免的,具体看你的业务要求,包括你数据库的负载都会影响你的决定。不知道大家发现没有,上面各种异常情况都是多个事务之间相互影响造成的,这说明两个事务之间需要某种方式将他们从某种程度上分开,降低直至避免相互影响。这时候数据库事务隔离级别就粉墨登场了,而数据库的隔离级别实现一般是通过数据库锁实现的。
下面是各种隔离级别对各异常的控制能力:
数据库锁分类一般可以分为两类,一个是悲观锁,一个是乐观锁,悲观锁一般就是我们通常说的数据库锁机制,乐观锁一般是指用户自己实现的一种锁机制,比如hibernate实现的乐观锁甚至编程语言也有乐观锁的思想的应用。 悲观锁:顾名思义,就是很悲观,它对于数据被外界修改持保守态度,认为数据随时会修改,所以整个数据处理中需要将数据加锁。悲观锁一般都是依靠关系数据库提供的锁机制,事实上关系数据库中的行锁,表锁不论是读写锁都是悲观锁。 悲观锁按照使用性质划分:
悲观锁按照作用范围划分:
乐观锁:顾名思义,就是很乐观,每次自己操作数据的时候认为没有人回来修改它,所以不去加锁,但是在更新的时候会去判断在此期间数据有没有被修改,需要用户自己去实现。既然都有数据库提供的悲观锁可以方便使用为什么要使用乐观锁呢?对于读操作远多于写操作的时候,大多数都是读取,这时候一个更新操作加锁会阻塞所有读取,降低了吞吐量。最后还要释放锁,锁是需要一些开销的,我们只要想办法解决极少量的更新操作的同步问题。换句话说,如果是读写比例差距不是非常大或者你的系统没有响应不及时,吞吐量瓶颈问题,那就不要去使用乐观锁,它增加了复杂度,也带来了额外的风险。 乐观锁实现方式:
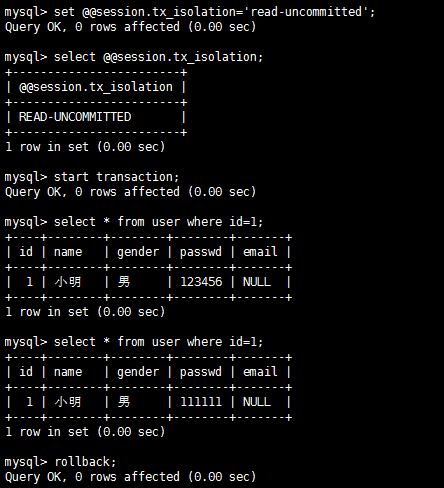
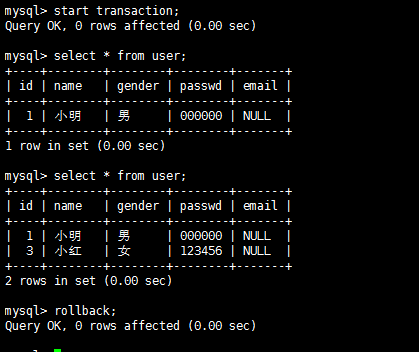
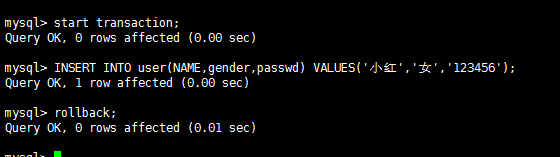
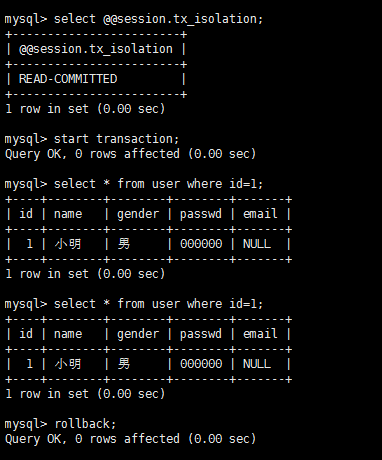
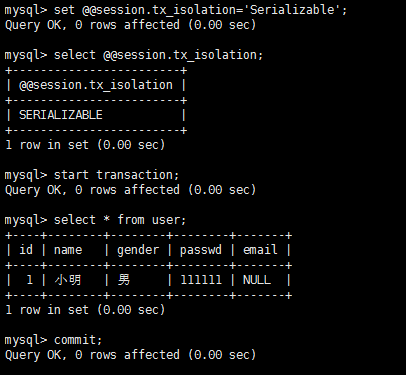
mysql事务隔离级别实战实践是检验真理的唯一标准,掌握上面的理论之后,我们在数据库上实战一番家里更好地掌握也加深理解,同时有助于解决实际问题。不同数据库很多实现可能不同,这里以mysql为例讲解各种隔离级别下的情况,测试表为user(id,name,gender,passwd,email)。 隔离级别:read-uncommitted 脏读测试流程: A:
B:
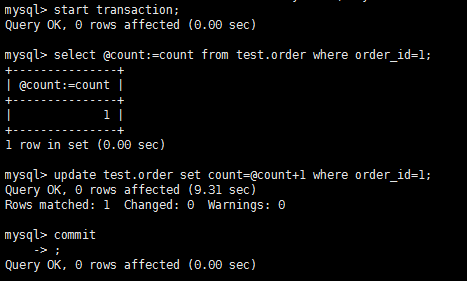
结论:A读到了B没有提交的内容,隔离级别为read-uncommitted的时候出现脏读。 第一类更新丢失测试流程: 结论:结果不如我所想的,A的更新成功了,为什么呢?A执行update语句的时候对该条记录加锁了,B这时候根本无法修改直至超时,也就是至少在mysql中在read-uncommitted隔离级别下验证第一类丢失更新,据了解有的数据库好像可以设置不加锁,如果能够不加锁的话则可以实现,也贴一下图吧。 A:
B:
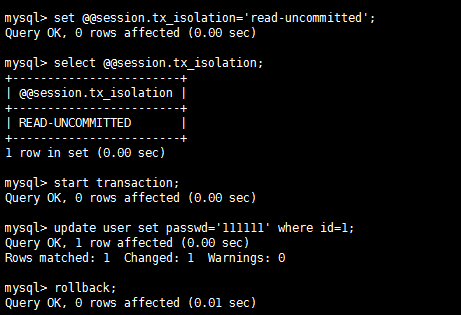
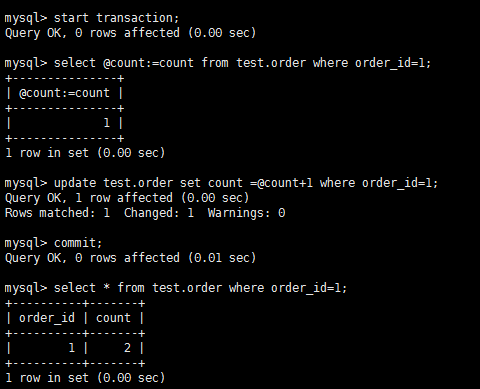
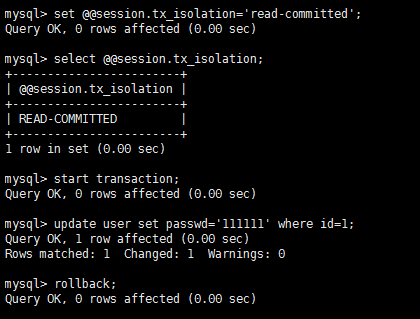
不可重复读测试流程(省略): 结论:流程和测试脏读一样,其实在第一次测试脏读的时候就可以发现会出现不可重复读,A两次读取id=1的数据内容不同。 第二类丢失更新流程: A:
B:
结论:A的更新丢失,我们希望的结果是3,而实际结果是2,跟java的多线程很像对不对,read-uncommitted隔离模式下会出现第二类丢失更新。 幻读测试流程: A:
B:
结论:A两次查询全表数据结果不同,read-uncommitted隔离模式下会出现幻读。 注:因为后面对这几种异常情况的测试流程基本和上面一样,个别有些差别读者自己注意,另外注意更改隔离级别即可,就能看到对应结果,后面的我只给出进一步能解决的异常测试截图,结论可以参照前面的对照表。 隔离级别:read-committed 脏读测试截图 A:
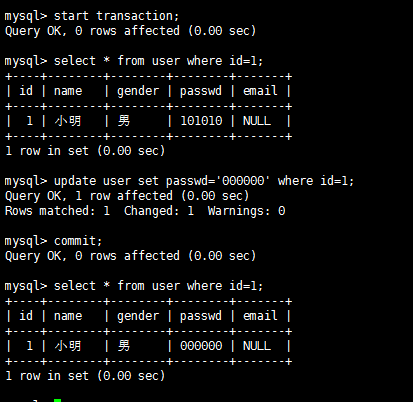
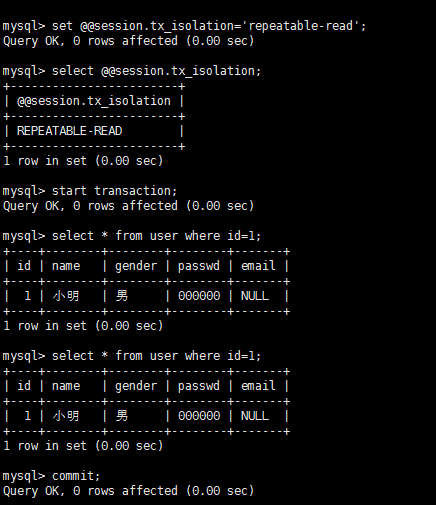
结论:A没有读到B没有提交的内容,隔离级别为read-committed的时候不会出现脏读。 隔离级别:repeatable-read 不可重复读测试截图 A:
B:
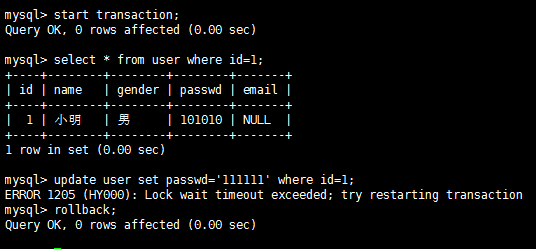
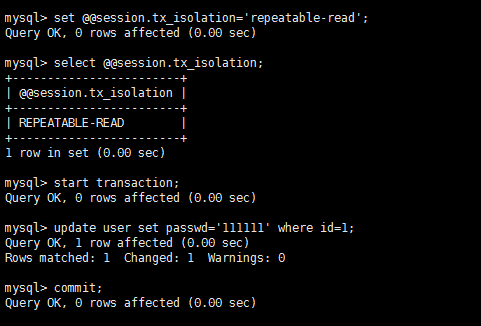
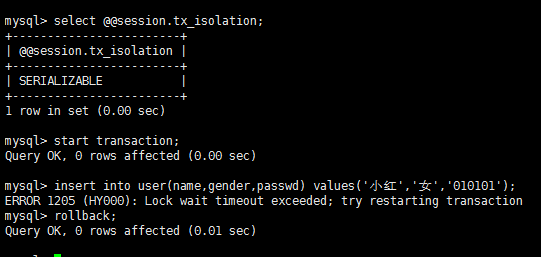
结论:A两次读取id=1的数据内容相同,repeatable-read隔离模式下不会出现不可重复读。 隔离级别:Serializable 幻读测试截图 A:
B:
结论:因为A事务未提交之前,B事务插入操作无法获得锁而超时,Serializable隔离模式下不会出现幻读。 |
|||||||||||||||||||||||||||||||||
注意:我们讨论隔离级别的场景,主要是在多个事务并发 的情况下,因此,接下来的讲解都围绕事务并发。
Read uncommitted 读未提交
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高 兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有 2000元,singo空欢喜一场。
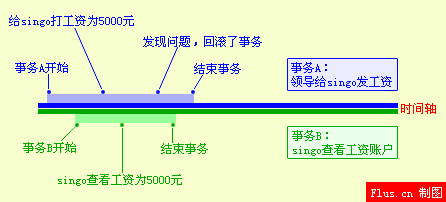
出现上述情况,即我们所说的脏读 ,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为5时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在 singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为 何......
出现上述情况,即我们所说的不可重复读 ,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed 时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读
当隔离级别设置为Repeatable read 时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读 。
singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额 (select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction ... ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出 现了幻觉,幻读就这样产生了。
注:Mysql的默认隔离级别就是Repeatable read。
Serializable 序列化
Serializable 是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
其他参考链接:MySQL数据库事务隔离级别(Transaction Isolation Level)
锁(并发控制的手段)
独占锁(排他锁)只允许一个事务访问数据
共享锁 允许其他事务继续使用锁定的资源
更新锁
锁就是保护指定的资源,不被其他事务操作,锁定的资源包括行、页、簇、表和数据库。为了最小化锁的成本,SQL Server自动地以与任务相应等级的锁来锁定资源对象。锁定比较小的对象,例如锁定行,虽然可以提高并发性,但是却有较高的开支,因为如果锁定许多行,那么需要占有更多的锁。锁定比较大的对象,例如锁定表,会大大降低并发性,因为锁定整个表就限制了其他事务访问该表的其他部分,但是成本开支比较低,因为只需维护比较少的锁。
设置事务级别:SET TRANSACTION ISOLATION LEVEL
开始事务:begin tran
提交事务:COMMIT
回滚事务:ROLLBACK
创建事务保存点:SAVE TRANSACTION savepoint_name
回滚到事务点:ROLLBACK TRANSACTION savepoint_name