CockroachDB分布式SQL层架构解析
SQL 层
SQL层主要用来将SQL语句转化为K-V操作,并将操作送给事务层。
SQL Parser, Planner, Executor,CRDB通过yacc将语句解析为抽象语句树(AST),yacc是描述CRDB支持的语法的文件;通过生成的AST,CRDB将其生成计划树,计划树的节点是planNodes,每个planNodes都包含一系列K-V操作,可以通过EXPLAIN查看计划树的具体情况,比如:
explain select season from episodes where id<100;
+-----------+-------+------------------+
| Tree | Field | Description |
+-----------+-------+------------------+
| render | | |
| └── scan | | |
| | table | episodes@primary |
| | spans | -/99/# |
+-----------+-------+------------------+
(4 rows)
这里的将语句计划为一个scan操作,scan是用来扫描底层K-V对的API;然后Executor负责对计划的执行,主要是编码语句里的值然后发给事务层,解码下层返回来的值。
Encoding,数据在SQL语句中是string形式,而在底层都是操作bytes,因而在将数据传到下层前需要将数据编码。需要注意的一点是由于数据是以K-V对按照顺序存储在range里,因此编码需要满足编码前的索引顺序和编码后的索引顺序仍然一致。
其中K-V对中key的编码包括:1.表ID。2.主键索引的ID。3.行的主键。4.列集合(column family)ID。
Value编码包括:1.四字节的校验和用来校验key和value。2.一字节的value类型(跟数据类型不同)。3.如果后面的列不是第一列(根据column id),那么后跟一字节的column id difference和数据类型。4.编码后的数据。
插入一条数据,有两个column family,那么编码后的K-V对为:
INSERT INTO accounts VALUES (1, 'Alice', 10000.50);
/Table/51/1/1/0/1489427290.811792567,0 : 0xB244BD870A3505348D0F4272
^- ^ ^ ^ ^-------^-^^^-----------
| | | | | | |||
Table ID (accounts) Checksum| |||
| | | | |||
Index ID Value type (TUPLE)
| | |||
Primary key (id = 1) Column ID difference
| ||
Column family ID (f0) Datum encoding type (Decimal)
|
Datum encoding (10000.50)
^- ^ ^ ^ ^-------^-^^^-----------
| | | | | | |||
Table ID (accounts) Checksum| |||
| | | | |||
Index ID Value type (TUPLE)
| | |||
Primary key (id = 1) Column ID difference
| ||
Column family ID (f0) Datum encoding type (Decimal)
|
Datum encoding (10000.50)
DistSQL,CRDB对语句的执行是将计算分布到每个存储了语句涉及的数据的节点,每个包含了数据的节点处理自己的那一份数据,然后将结果发送给协调节点进行总结。
Motivation,DistSQL的作用主要是三点:1.remote-side filtering,每个node都能自己过滤数据,而不是全发给协调节点再进行过滤。2.remote-side updates and deletes,每个node都可以自己更新和删除数据而不用发往协调节点处理然后在同步到原node。3.distributed sql operation,将SQL操作(join、group by等)分布到每个node。
Detailed design,DistSQL分为两步,第一步是形成logical plan,类似于前面的planNode,是抽象的执行流程,第二步是形成physical plan,将抽象流程具体到实际node进行处理。
logical plan包含一系列的aggregators,aggregator是一个抽象的概念,有着一个输入stream(有些可能没有,比如table reader)并对输入做一些操作产生一个输出stream(有些可能没有,比如final)。aggregator里面有着一些group,group由group key组织,group key是输入stream中一些列,group间是相互独立的,可以分离处理,因而这也让计算可以分布在不同的node上。aggregator的种类由:
table reader,没有输入stream,它从表的range分布的各个node读取需要的数据,并且可能对数据做一些初级的过滤(where后面的条件)操作,并将结果从输出stream输出。
evaluator,是一个可编程的aggregator,用来做一些计算比如‘SELECT a+b FROM tb where ...’,其中'a+b'就可以交给evaluator来进行计算,evaluator可以根据group key分布在多个node进行计算。
join对两个输入stream进行join操作,通过相等性来得到输出stream。
join reader,通过相等性来从本地或者其他node读取数据。
mutate,对K-V对进行insert、delete和update操作。
set operation,对一些输入流进行set操作比如union或者difference。
aggregator,对数据做聚集操作,比如sum、count和distinct等。
sort,对数据做非默认的输入流排序操作(有些输入流本身就是有顺序的,因为K-V对存储就是根据主键顺序存储,这样可以最大程度的减少sort的使用)。
limit,读取达到limit界定的行后不再读取。
intent collector,是一个单group(不能分布在多个node)的aggregator,位于gateway node(最开始收到query的node),他从mutate获取操作后的intents,并一直跟踪它们的状态直到事务提交。
final,也是单group,位于gateway node,收集其他aggregator查询的结果进行总结然后提交。
一个logical plan的例子如下:
TABLE v (Name STRING, Age INT, Account INT)
SELECT COUNT(DISTINCT(account)) FROM v
WHERE age > 10 and age < 30
GROUP BY age HAVING MIN(Name) > 'k'
生成的logical plan:
WHERE age > 10 and age < 30
GROUP BY age HAVING MIN(Name) > 'k'
生成的logical plan:
TABLE-READER src
Table: v
Table schema: Name:STRING, Age:INT, Account:INT
Filter: (Age > 10 AND Age < 30)
Output schema: Name:STRING, Age:INT, Account:INT
Ordering guarantee: Name
Table: v
Table schema: Name:STRING, Age:INT, Account:INT
Filter: (Age > 10 AND Age < 30)
Output schema: Name:STRING, Age:INT, Account:INT
Ordering guarantee: Name
AGGREGATOR countdistinctmin
Input schema: Name:String, Age:INT, Account:INT
Group Key: Age
Group results: distinct count as AcctCount:INT
MIN(Name) as MinName:STRING
Output filter: (MinName > 'k')
Output schema: AcctCount:INT
Ordering characterization: if input ordered by Age, output ordered by Age
Input schema: Name:String, Age:INT, Account:INT
Group Key: Age
Group results: distinct count as AcctCount:INT
MIN(Name) as MinName:STRING
Output filter: (MinName > 'k')
Output schema: AcctCount:INT
Ordering characterization: if input ordered by Age, output ordered by Age
AGGREGATOR final:
Input schema: AcctCount:INT
Input ordering requirement: none
Group Key: []
Input schema: AcctCount:INT
Input ordering requirement: none
Group Key: []
Composition: src -> countdistinctmin -> final
最开始的table reader负责从各个node读取数据,并根据age>10和age<30进行了过滤,输入了包含name,age和account的输出stream;接下来的aggregator对前面的输出流进行distinct和count操作,注意他的group key是age,那么它是根据hash age来将数据分布在多个node的,结果数据统计的结构AccCount,其中输入stream是根据age排序的,那么如果这个aggregator不是sort则它的输出stream应该仍然根据age排序;最后一个final将结果进行统计并提交。
最开始的table reader负责从各个node读取数据,并根据age>10和age<30进行了过滤,输入了包含name,age和account的输出stream;接下来的aggregator对前面的输出流进行distinct和count操作,注意他的group key是age,那么它是根据hash age来将数据分布在多个node的,结果数据统计的结构AccCount,其中输入stream是根据age排序的,那么如果这个aggregator不是sort则它的输出stream应该仍然根据age排序;最后一个final将结果进行统计并提交。
得到logical plan后将其各个aggregator的计算分布在各个node上得到physical plan。需要注意的是即使计算分布在了很多node上,但如果logical的输入stream是有序的,那么他的输出stream也仍然是有序;像final之类的单group的总结性的aggregator计算应该只能分布在一个node上。
分布计算的的简单规则如下:
table readers根据range的分布将数据读取任务分布给各个node,一般来讲为了就近原则,是选择该range的lease node,从读取数据开始以及执行后面一系列计算的流程叫做flow,多个flow并行执行在不同的node上。
同样根据就近原则,如果table reader开始的flow能够在该node上完成后续的计算,就不会移动,当有的aggregator的数据需要发往其他node进行聚集时,根据group key来分布输出stream的数据(也不总是这样)。
分布计算不依赖于range的正确性,当计划使用的range被修改或者删除了,仍然可以从其他replicas那里读取数据。
下面是一个语句的计划生成过程,数据的range分布在A,B两个节点:
TABLE Orders (OId INT PRIMARY KEY, CId INT, Value DECIMAL, Date DATE)
SELECT CID, SUM(VALUE) FROM Orders
WHERE DATE > 2015
GROUP BY CID
ORDER BY 1 - SUM(Value)
logical plan:
WHERE DATE > 2015
GROUP BY CID
ORDER BY 1 - SUM(Value)
logical plan:
TABLE-READER src
Table: Orders
Table schema: Oid:INT, Cid:INT, Value:DECIMAL, Date:DATE
Output filter: (Date > 2015)
Output schema: Cid:INT, Value:DECIMAL
Ordering guarantee: Oid
Table: Orders
Table schema: Oid:INT, Cid:INT, Value:DECIMAL, Date:DATE
Output filter: (Date > 2015)
Output schema: Cid:INT, Value:DECIMAL
Ordering guarantee: Oid
AGGREGATOR summer
Input schema: Cid:INT, Value:DECIMAL
Output schema: Cid:INT, ValueSum:DECIMAL
Group Key: Cid
Ordering characterization: if input ordered by Cid, output ordered by Cid
Input schema: Cid:INT, Value:DECIMAL
Output schema: Cid:INT, ValueSum:DECIMAL
Group Key: Cid
Ordering characterization: if input ordered by Cid, output ordered by Cid
EVALUATOR sortval
Input schema: Cid:INT, ValueSum:DECIMAL
Output schema: SortVal:DECIMAL, Cid:INT, ValueSum:DECIMAL
Ordering characterization: if input ordered by [Cid,]ValueSum[,Cid], output ordered by [Cid,]-ValueSum[,Cid]
SQL Expressions: E(x:INT) INT = (1 - x)
Code {
EMIT E(ValueSum), CId, ValueSum
}
physical plan:
Input schema: Cid:INT, ValueSum:DECIMAL
Output schema: SortVal:DECIMAL, Cid:INT, ValueSum:DECIMAL
Ordering characterization: if input ordered by [Cid,]ValueSum[,Cid], output ordered by [Cid,]-ValueSum[,Cid]
SQL Expressions: E(x:INT) INT = (1 - x)
Code {
EMIT E(ValueSum), CId, ValueSum
}
physical plan:
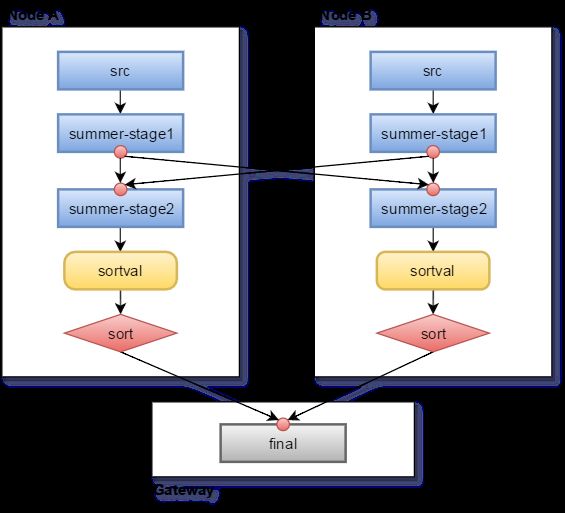
每个方框是一个processor,processor是aggregator在每个node上的具体处理者。这里将table reader分布在了A,B两个node的src processor上;summer aggregator需要根据cid来聚集数据,因而分为两步,第一步收集上一个flow中上个processor的数据并做一些能够在本地处理的计算(这里仅仅收集数据),然后根据group key(这里是cid)将数据hash到第二步的processor(不同node),这样相同的cid的数据就能在同一个node继续进行聚集操作(这里是sum);随后sort数据然后发给final汇总并提交。
聚集数据的那两步之间也不总是通过group key hash数据到不同node,也可以将各自的数据都发往一个node,集中在这个node进行sum操作,这个要看当时的数据量(比如其中一边数据量很少,那么可以那一边的发往另一个node,而另一个node不用发送数据)。
Processor包含三个部分:
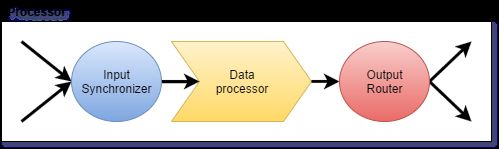
第一部分进行输入同步,有三种类型:1.只有一路输入的,那么不用做任何操作。2.对顺序没有要求的,那么将几路输入随意的组合在一起送到下一部份。3.输入有顺序的(aggregator的输入stream存在有序要求),那么会根据顺序将几路数据聚集在一起送到下一部分。
第二部分进行具体数据处理。
第三部分进行输出路由,有四种类型:1.单路输出,不做任何操作。2.将数据镜像发送到多个node。3.通过hash group key将数据分布到多个node。4.将数据送到对应的range所在的node。
JOIN,对于需要进行join操作的两个stream之间,通过将其中一个stream进行hash,然后与另一个stream进行处理,如果用hash的列是group key,那么处理速度更快。join操作可以分布在多个node上,有两种分布方式:1.通过processor的hash类型的router将数据hash到不同node上,用来hash的列是进行连接相等性比较的列,这样该列等值的行会被hash到同一个node。

2.其中一个stream的processor的router通过镜像方式将他的数据发送到进行join操作的另一个node,适用于这个node数据量较少的情况。

Scheduling,对于每个事务在每个node上的processor需要一个规则来避免死锁等问题:
所有的processor都是根据事务来在队列排序,而不是根据processor来进行排序。
限制一次性同时运行的processor数量。
事务队列根据事务时间戳和优先级进行排序,每个node上的processor都需要遵循这个队列顺序。