为什么企业需要快速建模的能力?
数据仓库作为一种数据环境,具有面向分析、提供管理决策支持的重要作用。而在数据仓库中,多维数据模型能够满足大多数企业的数据分析需求——它提供了多角度多层次的分析应用,比如基于时间维度、地域维度等构建的销售星形模型、雪花模型,可以实现在各时间维度和地域维度的交叉查询,以及基于时间维度和地域维度的细分。
传统的多维模型建模,具有冗长而复杂的特点。首先要选择业务过程,其次声明数据粒度,之后确定维度字段和事实字段。其中,由于业务过程是由很多微观的业务活动组成的,比如注册用户、获得订单、开具发票、接受付款、处理索赔等等。因此,建模人员需要耗费大量时间去理解和组织业务活动,这样创建的模型最终才能回答业务分析的具体问题,为管理决策提供权威的数据支持。
而在当前的信息时代,业务的快速反应能力决定了很多企业能否把握准确的时机,甚至决定了很多企业在关键时刻的生死存亡。比如零售行业,尤其是电商方向的企业,管理决策层需要关注引起利润变化的因素并迅速调整的营销策略。因此,快速建模或者调整数据模型才可以支持这类的业务快速反应能力。
KAP 支持业务的快速反应
KAP 支持标准SQL接口,通过JDBC和ODBC无缝对接主流BI产品,完全匹配商业分析师熟悉的分析模式。分析师无需了解大数据底层架构,可以在海量大数据上进行交互式的分析,释放了大数据生产力。
不同的企业中,常用的业务分析问题是基本固定的,比如零售行业的常见问题“同样的营销模式下,不同渠道的利润差别有多大?”。而这些常用的业务分析问题都已经转化为固定的的查询报表、成体系的SQL查询语句或者商业分析师相对稳定的查询模式。
KAP v2.5支持自动创建合适的模型,减少了建模人员了解业务细节的时间成本,消除了建模人员与业务人员的磨合成本,大大增加了企业的快速反应能力。
KAP v2.5的自动建模之路
具体来说,KAP v2.5 增强了智能化的建模,模型推荐支持通过SQL自动生成模型,Cube优化器支持多种存储优化策略。另外,新增了通过SQL验证模型的能力,支持对业务分析需求变化的快速响应。
模型推荐
模型从无到有的部分,最考验建模人员对业务逻辑和查询需求的理解。传统多维模型的建模耗时耗力,而且对最终所创建的模型是否能回答业务查询无法保证。KAP v2.5支持通过SQL自动生成模型。导入源表后,即可通过输入SQL自动创建模型,实现了从SQL到模型的一键生成。以查询SQL为依据,自动生成的模型可以准确的回答这些查询SQL。

多策略的Cube优化器
Cube是数据仓库中一个经典的概念,是多维模型的一个形象的说法。传统OLAP 技术下,Cube虽然能存储大量维度,但随着维度增加, Cube所需要的存储空间也会呈几何倍数增长。比如一个Cube中包含了N个维度,那么这N个维度将生成2N 个维度组合。这些成倍增长的维度组合中,有很多在整个Cube的生命周期里都不会被使用,同时由于维度组合数爆炸而带来的存储膨胀、构建时间冗长、甚至查询性能由此而下降的弊病。
为了解决这个问题 KAP 提供了多种场景下,对Cube的优化设置,帮助用户筛选出真正会被使用到的 Cube维度组合,避免大量存储资源被无效的维度组合耗用,缩短构建时间。优化设置包括衍生维度、聚合组、联合维度、层级维度、必要维度和Rowkey等。
结合不同的业务场景,合理的使用这些优化设置能够使数据建模事半功倍。根据这些优化设置的方法,商业分析师可以定制精确满足业务场景的Cube,避免Cube爆炸的问题。
Cube优化器提供了多种优化策略来满足不同的业务场景, 其中模型优先策略,充分利用数据自身的逻辑关系优化Cube,满足灵活查询场景;业务优先策略,定向加速指定SQL,用最小的存储成本支持常见的报表查询模式;综合优化策略,支持以上两种需求,满足了多种优化场景。
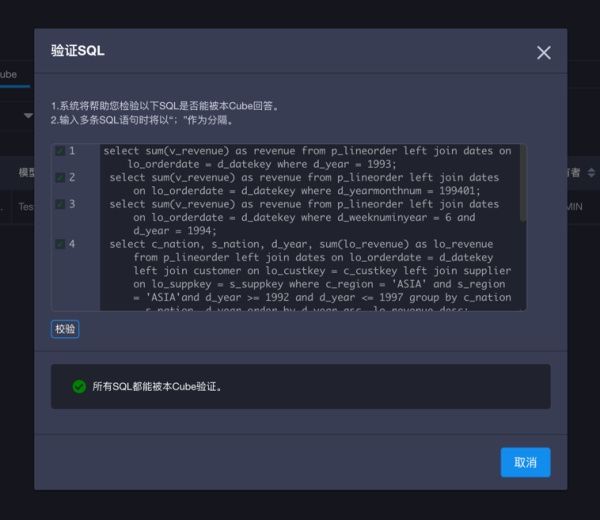
快速验证SQL
同样,在传统的OLAP 技术下,数据模型需要在构建后才能得到验证。每一次模型从设计到验证,需要付出很大的时间成本与资源代价,滞后的模型设计反馈难以满足当前快节奏的市场变化。
KAP v2.5支持的快速验证能力,极大地加速了模型反馈。无需构建,建模后即可快速验证模型是否满足业务查询SQL,快速响应业务分析需求变化。
总结
在当前的信息时代,业务的快速反应能力决定了很多企业能否把握准确的时机,KAP致力于帮助更多企业把握时机,通过支持以SQL为中心的自动建模,支持模型设计快速验证,以响应瞬息万变的市场需求,实现更多企业的商业价值与使命。