论文地址:https://arxiv.org/abs/1807.02515
论文题目:
Blockchain as a Service: An Autonomous, Privacy Preserving, Decentralized Architecture for Deep Learning
背景知识
深度学习这一概念自从2006年Hinton等人提出之后,迅速成为机器学习领域的一个热门分支。深度学习技术在了当下几乎所有的人工智能领域表现出了远远超过传统方法的性能,包括计算机视觉、音频处理、自然语言处理、大数据分析等等。
深度学习之所以称之为“深度”是相对与传统的人工神经网络方法来说具有多个隐藏层,这些深层的模型通过特征的组合,逐层将原始输入转化为高层的抽象特征然后经过最后的输出层得到最终的任务目标。通过这种深层的特种提取,深层模型实现了十分强大的表达能力。
随着深度学习研究热潮的持续高涨,深度学习入门的门槛也在迅速降低。各种开源的深度学习框架层出不穷,比如TensorFlow、Caffe、Keras、CNTK、PyTorch、Theano,等等。使用这些框架开发者可以不再去从零开始写一个深度学习模型的代码,从而实现高效的深度学习.....
而且一些Batch Normalization之类的的新技术的出现,深度学习模型的训练变得更加容易,调参的时间大幅度减少。但是,在实际的应用中,要训练出一个好的深度学习模型仍然是一件不容易的事情。
深度学习与数据隐私
深度学习之所以在各领域能够取得巨大的成功有两个主要因素:
1.具有一般分布的大型数据集。
- 可观的计算能力,主要是大型GPU集群。在计算能力足够的情况下,如何得到高质量,大数量的数据成为了制约深度学习模型能力的关键。
对于一些大型的基于网络的企业来说,可以通过收集并保存用户的数据,例如照片、语音、视频、文字等,集中起来以备将来使用。
正因为如此,在深度学习领域成功应用的大多数都是一些大型组织,它们既拥有大量有价值的数据,也拥有足够的计算能力去训练深度模型来改进它们的产品和服务。
虽然深度学习的好处是不可否认的,但它需要收集大量的数据,这就带来了隐私的风险。这些收集起来的数据的使用,作为一般用户来说是无法控制的。它有可能被组织或者第三方机构用来挖掘用户的隐私敏感信息。随着数据隐私意识的增强,用户会变得不愿意分享他们的数据。
从另一个角度看,这些用户的数据正在成为一种宝贵的资产。此外,在一些领域如医疗保健部门,政府的办公室等,有丰富的有价值的数据,但是由于隐私和法律法规,不能与第三方分享。如果开发一种方案,能够在充分利用这些私人数据的同时保持他们的隐私是很有意义的,这也是这篇文章中所希望解决的主要问题。
区块链可以说是近年来非常火热的一个名词了。2008年由中本聪提出比特币的概念并使用区块链技术作为其底层技术和基础架构。
区块链技术有一个重要特征就是“匿名性”:由于节点之间的交换遵循固定的算法,其数据交互是无需信任的,区块链中的程序规则能够自行判断活动是否有效,因此交易对手无须通过公开身份的方式让对方对自己产生信任,两个陌生的节点也可以进行安全的交易。
在本文中作者结合区块链与去中心的深度学习技术,提出了一种自主的隐私保护与合作的深度学习框架。
区块链+深度学习
作者描述了三种不同的深度学习方案。
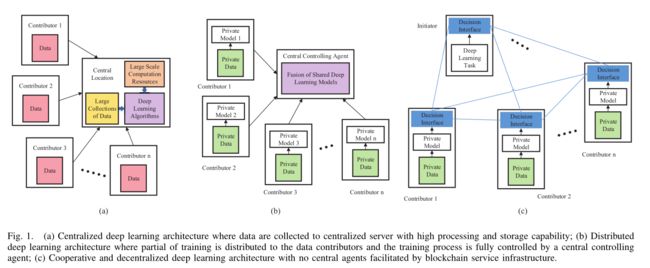
一种是中心化的深度学习架构。如图1(a)所示,中心服务器收集来自数据贡献者的数据,然后进行统一的存储和处理。
通过这种数据采集方式来创建大规模数据集的最大问题之一就是隐私及其相关问题。数据的提供者可能并没有共享数据的动机。此外中心服务器需要很高的计算能力来处理收集到的大数据。
另一种解决方案是分布式深度学习架构。如图1(b)所示,在分布式学习中,不是由单个中心服务器收集和处理数据,而是将数据的处理分配给各个数据贡献者。这样,贡献者使用他们各自的本地数据来训练自己的深度学习模型,然后由中心服务器融合贡献者们的模型。
这种方式数据是不共享的从而保护了数据的隐私。此外,在具有较小的数据集上训练深度学习模型,与第一种中心化的方案相比,单个计算贡献者所需要的计算能力要低得多。
然而,这种架构完全由中心的服务器控制整个深度学习模型,容易收到单点故障的影响。基于此作者提出了改进的架构如图1(c)所示,每个计算贡献者可以完全控制自己的深度学习模型,并且贡献者的参与或者离开这个计算架构不会影响整个学习过程的功能和效率。
此外,参与计算的贡献者能够依照其贡献的价值得到一些财务上的奖励用于激励。为了能够实现上述目的,作者使用以太坊作为区块链平台设计了智能合约来确保网络陌生节点之间交易互信,从而实现了自主协作的非中心化深度学习框架。
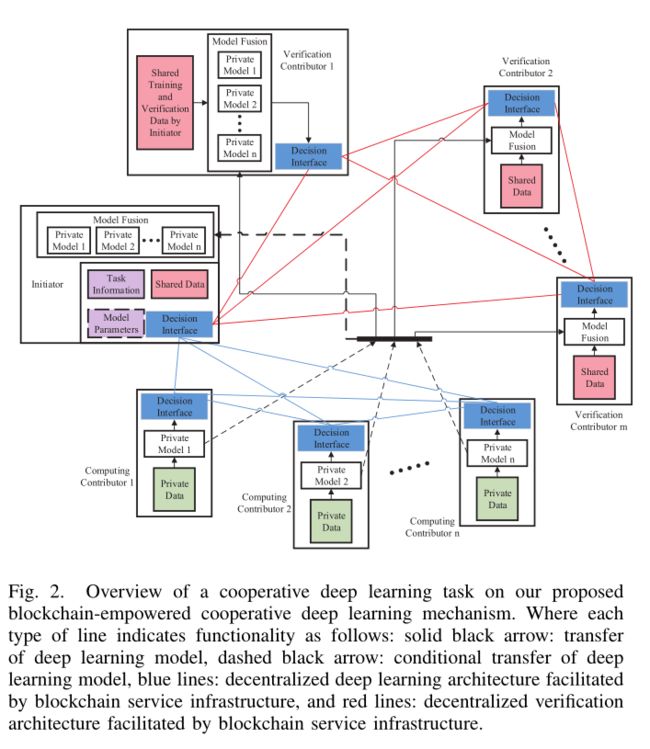
面我们从图2中来看一看,作者提出的深度学习框架机制的详细情况。如图2所示,个体的参与者可以在这个框架中充当应用发起人、计算贡献者或是验证贡献者。
应用发起人是某项任务的发起者,负责定义计算任务,比如输入数据的属性和模型的预期输出。他们也要提供一些用于核实的数据集并且定义模型预测结果的准确度,最后还需要承诺财务报酬。发起人可以选择是否预先设定好算法模型的结构。
计算贡献者使用自己拥有的本地数据针对给定的任务训练合适的算法模型,并将训练好的模型发布给验证贡献者。如果发起人推荐了算法模型的结构,那么计算贡献者就优化推荐的模型而不是训练一个新的模型。
接收到训练好的模型之后,验证贡献者将接收到的模型进行融合然后在共享的数据集上评估整体的性能是否改进,然后评估计算贡献者的贡献。验证参与者是被动参与该过程的,他们以随机和非中心化的方式提供硬件资源来执行验证任务。
验证贡献者之间通过多数表决的方式确定计算贡献者的贡献,然后依据相应的贡献从发起人获得报酬。验证贡献者也会得到发起人承诺的报偿。
根据以太坊区块链上的智能合约,在支付财务报酬之后,发起人能够访问训练好的模型。因为计算贡献者和验证贡献者都可以方便地离开或者加入任务,所以这个学习过程是异步和自适应的。
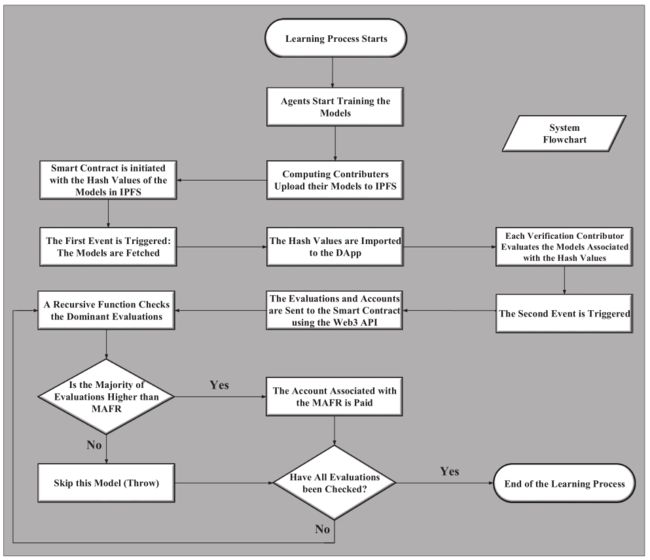
作者提出的框架里面参与者之间的交互是通过部署在以太坊平台上实现的,然后通过智能合约来控制这些交互行为。智能合约主要由两个事件组成。
学习过程的流程图如图3所示,在第一个事件中,首先由任务发起人定义好任务的各项细节启动任务,然后计算贡献者针对给定的任务训练模型并将模型参数使用星际文件系统(Interplanetary File System,缩写IPFS)存储。
用模型参数在IPFS中的哈希值初始化智能合约。哈希值传递给DApp可以得到训练好的模型。当接收到训练好的模型后,验证贡献者开始进行评估其性能然后报告评估结果。
在智能合约的第二个事件中,智能合约会获取到验证贡献者得出的个体的评估结果,然后对任务发起人指定的阈值最小可接受适配率(minimum acceptable fitness rate,缩写 MAFR)进行检查,如果大多数评估结果高于MAFR,支付函数就通过以太坊自动地将以太币转给相应的计算贡献者。此外,所有的验证贡献者也会获得他们工作量的报酬。
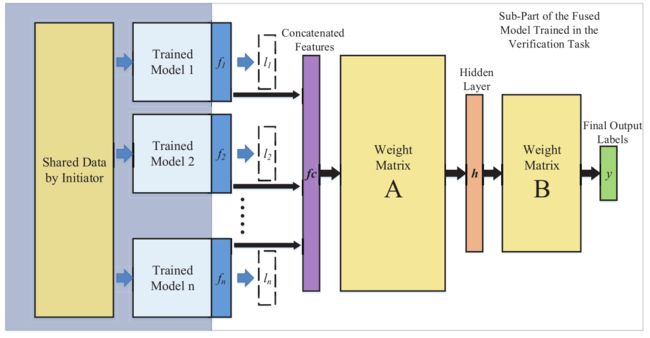
图2所示的深度学习框架需要有一种有效的机制来整合由各个计算贡献者提供的各种合理的计算模型,以针对任务目标实现好的性能。作者采用的整合模型的策略如图4所示,模型的整合层可以看做是一个单隐层的神经网络。
把n个训练好的模型中的输出层拿掉,将上一层的输出结果作为特征向量拼接起来得到特征向量fc。隐藏层h的维度与n个模型的输出层的维度和相等。
对于如何学习权重矩阵A、B的最优值,作者使用了两种策略:1. 权重矩阵A、B没有任何限制,可以直接使用反向传播进行优化计算。2. 提出了渐进模型融合策略,希望能够即学习到模型之间的相关性,同时也能保留模型的独特性。
仿真实验与主要结果
作者考虑到以太坊网络上挖矿过程会有很严重的交互延迟,所以在私有链上进行仿真实验来验证框架的性能。在仿真中,考虑深度学习任务是对MNIST数据集所提供的10个手写数字图像类别进行分类。
假设有5个计算贡献者,每个计算贡献者使用三层卷积神经网络作为分类器,并且每个计算贡献者拥有MNIST数据集中的一部分作为本地数据。
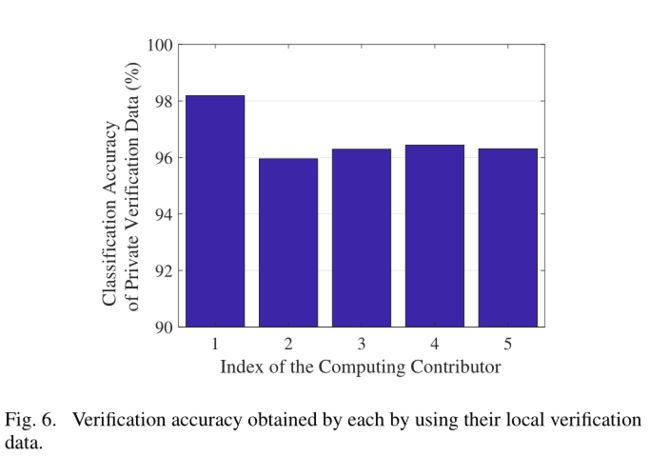
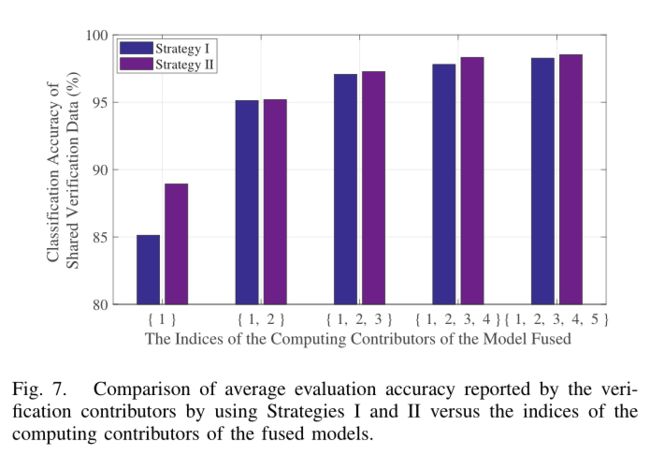
如图5所示,由各个计算贡献者开发的CNN模型对其本地验证数据分类的准确率。如图6所示,计算贡献者将他们的模型发布给验证贡献者,通过使用策略I和II分别由验证贡献者融合后获得的平均评价结果。
从图6中,我们可以观察到,验证贡献者验证数据的分类准确率随着模型融合数量的增加而增加。因此,可以认为所有的模型都对给定的任务有所贡献。从图6中也可以看出,利用策略II实现的融合模型精度比使用策略I获得的融合模型精度稍好。
结语
算力和大数据是深度学习在各种应用领域成功的两个主要因素,但是计算资源和数据都需要很高成本。随着人们对数据隐私越来越受到关注,更加大了数据获取的难度。因此,在深度学习中以适当的去中心化的方式使用私有数据是很有意义的。