1.几个重要的概念:
参考R-CNN的几个重要概念
什么是R-CNN
Since we combine region proposals with CNNs, we call our method R-CNN: Regions with CNN
features.
R-CNN中的boundingbox回归
下面先介绍R-CNN和Fast R-CNN中所用到的边框回归方法。
什么是IOU

为什么要做Bounding-box regression?

如上图所示,绿色的框为飞机的Ground Truth,红色的框是提取的Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5),那么这张图相当于没有正确的检测出飞机。如果我们能对红色的框进行微调,使得经过微调后的窗口跟Ground Truth更接近,这样岂不是定位会更准确。确实,Bounding-box regression 就是用来微调这个窗口的。
回归/微调的对象是什么?
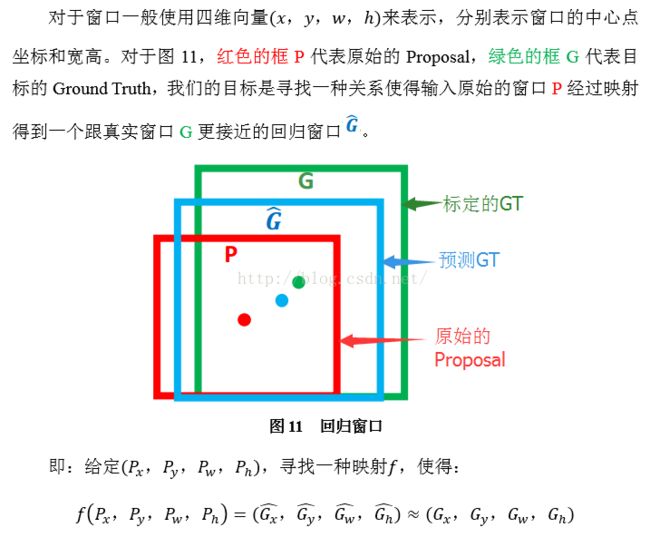
Bounding-box regression(边框回归)
那么经过何种变换才能从图11中的窗口P变为窗口呢?比较简单的思路就是:


注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这个也是G-CNN: an Iterative Grid Based Object Detector多次迭代实现目标准确定位的关键。
PASCAL VOC数据集
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。


2.R-CNN 模型
模型详解
中心思想:
RCNN全程就是Regions with CNN features,从名字也可以看出,RCNN的检测算法是基于传统方法来找出一些可能是物体的区域,再把该区域的尺寸归一化成卷积网络输入的尺寸,最后判断该区域到底是不是物体,是哪个物体,以及对是物体的区域进行进一步回归的微微调整(与深度学习里的finetune去分开,我想表达的就只是对框的位置进行微微调整)学习,使得框的更加准确。
正如上面所说的,RCNN的核心思想就是把图片区域内容送给深度网络,然后提取出深度网络某层的特征,并用这个特征来判断是什么物体(文章把背景也当成一种类别,故如果是判断是不是20个物体时,实际上在实现是判断21个类。),最后再对是物体的区域进行微微调整。实际上文章内容也说过用我之前所说的方法(先学习分类器,然后sliding windows),不过论文用了更直观的方式来说明这样的消耗非常大。它说一个深度网络(alexNet)在conv5上的感受野是195×195,按照我的理解,就是195×195的区域经过五层卷积后,才变成一个点,所以想在conv5上有一个区域性的大小(7×7)则需要原图为227×227,这样的滑窗每次都要对这么大尺度的内容进行计算,消耗可想而知,故论文得下结论,不能用sliding windows的方式去做检测(消耗一次用的不恰当,望各位看官能说个更加准确的词)。不过论文也没有提为什么作者会使用先找可能区域,再进行判断这种方式,只是说他们根据09年的另一篇论文[1],而做的。这也算是大神们与常人不同的积累量吧。中间的深度网络通过ILSVRC分类问题来进行训练,即利用训练图片和训练的分类监督信号,来学习出这个网络,再根据这个网络提取的特征,来训练21个分类器和其相应的回归器,不过分类器和回归器可以放在网络中学习,
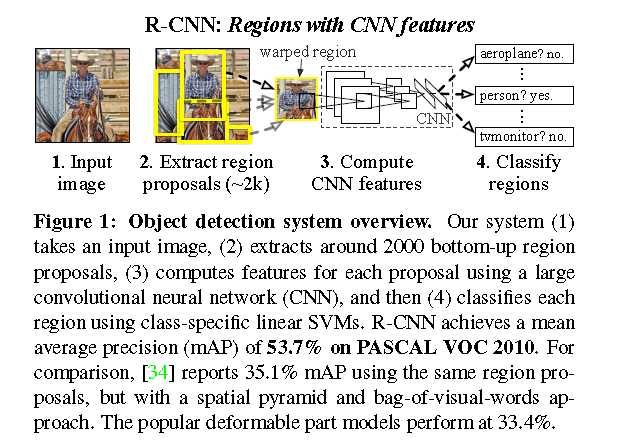
R-CNN 模型
如果要拟人化比喻,那 R-CNN 肯定是 Faster R-CNN 的祖父了。换句话说,R-CNN 是一切的开端。
R-CNN,或称 Region-based Convolutional Neural Network,其工作包含了三个步骤:
1.借助一个可以生成约 2000 个 region proposal 的「选择性搜索」(Selective Search)算法,R-CNN 可以对输入图像进行扫描,来获取可能出现的目标。
2.在每个 region proposal 上都运行一个卷积神经网络(CNN)。
3.将每个 CNN 的输出都输入进:a)一个支持向量机(SVM),以对上述区域进行分类。b)一个线性回归器,以收缩目标周围的边界框,前提是这样的目标存在。
下图具体描绘了上述 3 个步骤:
3.论文通读
Abstract:
R-CNN的两个贡献:1.cnn卷积层的能力很强,可以遍历候选区域达到精确的定位。2.当有标签的数据很少的时候,我们可以事前进行有标签(别的数据集上?)的预训练作为辅助任务,然后对特定的区域进行微调。
Introduction:
这篇文章最开始是在PASCAL VOC上在图像分类和目标检测方面取得了很好的效果。
为了达到很好的效果,文章主要关注了两个问题:1.用深层网络进行目标的定位。2.如何用少量的带标签的检测数据来训练模型
对于对一个问题目标定位,通常有两个思路可以走:
1.把定位看成回归问题。效果不是很好。
2.建立划窗检测器。
CNN一直采用建立划窗这个方式,但是也只是局限于人脸和行人的检测问题上。
本文使用了五个卷积层(感受野食195*195),在输入时移动步长是32*32。
除此之外,对于定位问题,我们采用区域识别的策略。
在测试阶段,本文的方法产生了大约2000个类别独立的候选区域作为cnn的输入。然 后得到一个修正后的特征向量。然后对于特定的类别用线性SVM分类器分类。我们用简 单的方法(放射图像变形)来将候选区域变成固定大小。
对于第二个缺少标签数据的问题
目前有一个思路就是无监督的预训练,然后再加入有监督的微调。
作为本文最大的贡献之二:在ILSVRC数据集上,我们先进行有监督的预训练。然 后我们在PASCAL这个小数据集上我们进行特定区域的微调。在我们的实验中,微调 可以提升8%的mAP。
本文的贡献;效率高
仅仅是特别类别的计算是合乎情理的矩阵运算,和非极大值抑制算法。他们共享权 值,并且都是低维特征向量。相比于直接将区域向量作为输入,维数更低。
本文方法处理能实现目标检测,还以为实现语义分割。
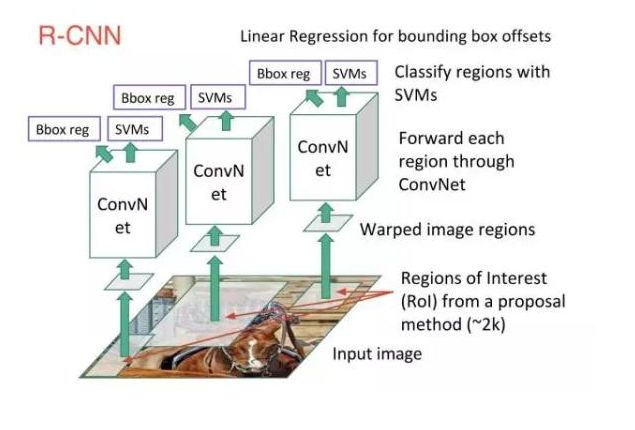
2.用R-CNN进行目标检测:
有3个Model:
(1)产生独立的候选区域。
(2)CNN产生固定长度的特征向量。
(3)针对特别类别的一群svm分类器。
2.1 模块的设计
候选区域:
之前有大量的文章都提过如果产生候选区域。本文采用SS(selective search )方法。参考文献【34】+【36】
特征抽取:
对于每个候选区域,我们采用cnn之后得到4096维向量。
2.2 测试阶段的检测
在测试阶段,我们用选择性搜素的方式在测试图片上选取了2000个候选区域,如上图所示的步骤进行。
运行时间分析:总之当时相比很快。
2.3训练模型
有监督的预训练:我们使用了大量的ILSVRC的数据集来进行预训练CNN,但是这个标签是图片层的。换句话说没有带边界这样的标签。
特定区域的微调:我们调整VOC数据集的候选区域的大小,并且我们把ImageNet上午1000类,变成了21类(20个类别+1个背景)。我们把候选区域(和真实区域重叠的)大于0.5的标记为正数,其他的标记为负数。然后用32个正窗口和96个负窗口组成128的mini-batch。
目标类别分类器:
对于区域紧紧的包括着目标的时候,这肯定就是正样本。对于区域里面全部都是背景的,这也十分好区分就是负样本。但是某个区域里面既有目标也有背景的时候,我们不知道如歌标记。本文为了解决这个,提出了一个阈值:IoU覆盖阈值,小于这个阈值,我们标记为负样本。大于这个阈值的我们标记为正样本。我们设置为0.3。这个是一个超参数优化问题。我们使用验证集的方法来优化这个参数。然而这个参数对于我们的最后的性能有很大的帮助。
一旦,我们得到特征向量。因为训练数据太大了。我们采用standard hard negative mining method(标准难分样本的挖掘)。这个策略也是的收敛更快。
2.4 Results on PASCAL VOC 201012
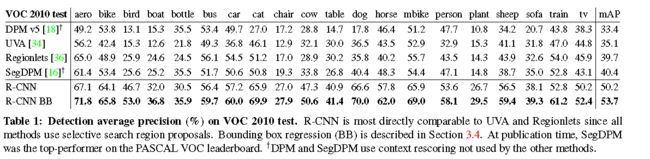
3.3. Visualization, ablation, and modes of error
3.1. Visualizing learned features
提出了一个非参数的方法,直接展现出我们的网络学习到了什么。这个想法是将一个特定的单元(特性)放在其中使用它,就好像它自己是一个对象检测器正确的。具体方法就是:我们在大量候选区域中,计算每个单元的激励函数。按从最高到最低排序激活输出,执行非最大值抑制,然后显示得分最高的区域。我们的方法让选定的单元“为自己说话”通过显示它所触发的输入。我们避免平均为了看到不同的视觉模式和获得洞察力为单位计算的不变性。我们可以看到来着第五个maxpooling返回的区域。第五层输出的每一个单元的接受野对应输出227*227的其中的195*195的像素区域。所以中心那个点单元有全局的视觉。

3.2. Ablation studies
实际上ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。
Performance layer-by-layer, without fine-tuning.
我们只观察了最后三层

Performance layer-by-layer, with fine-tuning.
微调之后,fc6和fc7的性能要比pool5大得多。从ImageNet中学习的pool5特性是一般的,而且大部分的提升都是从在它们之上的特定领域的非线性分类器学习中获得的。
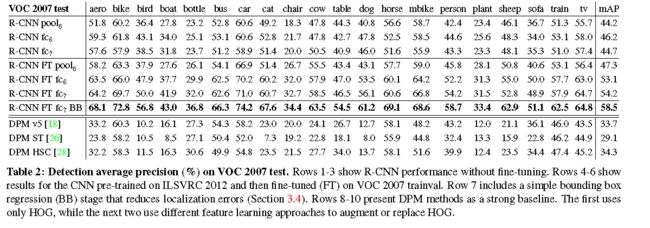
Comparison to recent feature learning methods.
见上图
3.3. Detection error analysis
CNN的特征比HOG更加有区分。
3.4. Bounding box regression
有了对错误的分析,我们加入了一种方法来减少我们的定位错误。我们训练了一个线性的回归模型
4.相关文献
HOG和SIFT很慢。但是我们可以由此得到启发,利用有顺序等级和多阶段的处理方式,来实现特征的计算。

生物启发的等级和移不变性,本文采用。但是缺少有监督学习的算法。

使得卷积训练变得有效率。


第一层的卷积层可以可视化。
【23】本文采用这个模型,来得到特征向量

ImageNet Large Scale Visual Recognition Competition
用了非线性的激励函数,以及dropout的方法。

【34】直接将区域向量作为输入,维数较高。IoU覆盖阈值=0.5,而本文设置为0.3,能提高5个百分点。产生候选区域的方式:selective search 也是本文所采取的方式是结合【34】+【36】。
【5】产生候选区域的方式为:限制参数最小割


bounding box regression


HOG-based DPM文章3.2section中的对比试验。


缩略图概率。

[18][26][28]文章3.2section中的对比试验。