
将 C 或 C++ 源代码编译成可执行文件分成两步:第一步是将每个源代码文件分别编译成可重定位文件(relocatable,扩展名为 .o),第二步是将所有的可重定位文件链接成可执行文件。在 Linux 中,可重定位文件和可执行文件的格式都是 ELF(Executable and Linkable Format)。
本文面向对 ELF 文件格式不熟悉的读者,通过图解的形式讲解 ELF 文件的链接方式,重点分析为什么要引入各种数据结构,以便读者对 ELF 的链接过程有形象化的认识。如果读者对这部分内容已经有所了解,可以直接跳到文章末尾的《参考文献》部分,直接阅读这些深入讲解 ELF 文件格式的文章和文档。
本文涉及的概念包括段(segment)、节(section)、符号表(symbol table)、字符串表(string table)和重定位表(relocation table)。重点讲解这些概念是如何互相配合,以服务于 ELF 链接过程的,而不详细说明这些概念在文件中的二进制格式。
为了减少复杂性,本文中的 ELF 程序都不使用共享对象(shared object)和动态加载技术(dynamic loading)。
1 段(segment)
从操作系统的视角来看,将程序加载到内存中的最简单方法是:将程序从文件中直接拷贝到内存的指定位置上,然后跳转到程序入口处。
因为程序在内存中的位置是预先约定好的,所以,每一个函数和全局变量在内存中的位置也都是可以事先知道的。程序的代码不需要任何修改就可以直接被执行。

在实际的操作系统中,内存是以页(page)为单位管理的。一页为 4096 字节(十六进制表示为 0x1000),每个内存页都可以设置访问权限。在 x86 中,内存页可以设置写入和执行两种权限。
出于系统安全的目的,代码所在的内存页可以执行,但不可以写入,数据所在的内存页可以写入,但不可以执行。如果有一段内存既可以写入,又可以执行,攻击者就可以利用程序的 bug 在这个位置写入攻击代码,然后执行它,从而达到破坏操作系统的目的。
在 ELF 文件中,内存访问属性相同的内容在文件中也连续存储,称为段(segment)。代码存放在代码段(text segment)中,数据存放在数据段(data segment)中。
除了在文件中的位置和长度,一个段还需要说明它在内存中的位置和长度,以及它所需的内存属性。这些信息记录在程序头(program header)中。段和程序头一一对应。
程序头以数组的形式连续地存储在 ELF 文件中,这个数组称为程序头表(program header table)。通常,程序头表在 ELF 头之后,但也可以在文件的其他位置。程序头表的在文件中的具体位置记录在 ELF 头之中。

操作系统根据 ELF 头记录的信息找到程序头表。在找到程序头表之后,操作系统按照每个程序头的信息,将对应的段加载到内存中的相应位置,最后跳转到程序入口处开始执行程序。
因为内存页以 4K 为单位,所以代码段和数据段的长度必须是 4K 的整数倍。如果通过在段末尾补 0 的方式凑齐 4K 的整数倍,就会有空间浪费。为了避免这种浪费,ELF 文件的各个段之间是紧密相连的,只是在加载到内存中的时候,才映射到不同的内存区域。又因为通过内存映射(memory mapping)加载文件时必须以 4K 为单位,所以在内存中数据段的开头会有一小部分代码,而代码段的末尾也会有一小部分数据。

2 节(section)
操作系统最关心的问题是如何将文件加载到内存中,因此,段所记录的信息是:
- 段在文件中的位置和长度;
- 段在内存中的位置和长度;
- 段的内存属性。
而从链接器的视角触发,第二点和第三点都不是链接器所关心的问题。链接器更关心 ELF 文件中各个部分的功能,以及如何按功能将多个可重定位文件合并成一个文件。
一个段可以包含多种需要区别对待的功能:在代码段中,普通的代码和全局初始化代码应该区别对待;在数据段中,有初始值的全局变量和没有初始值的全局变量也应该区别对待。这样一段连续的相同功能的区域称为节(section)。与段不同,每个节都有名称。
与代码和数据相关的节包括:
| 节名称 | 描述 | 在可执行文件中放在哪个段中 |
|---|---|---|
| .text | 一般的代码 | 代码段 |
| .init | 初始化代码,在程序运行的最开始执行 | 代码段 |
| .fini | 清理代码,在程序退出前执行 | 代码段 |
| .data | 有初始值的全局数据 | 数据段 |
| .bss | 没有初始值的全局数据,初始值为 0 | 数据段 |
| .rodata | 只读的全局数据 | 代码段,因为在内存属性上与代码段最接近 |

描述节的结构是节头(section header)。节头以数组的形式连续地存放在文件中,这个数组被称为节头表(section header table)。节头表通常放置于 ELF 文件的末尾,它的具体位置记录在 ELF 头中。
值得注意的是,节不是段的子结构,而是与段的地位相同的结构。段是从操作系统的视角来看 ELF 文件的方式,节是从链接器的视角来看 ELF 文件的方式。它们都是 ELF 文件的可选部分:可重定位文件没有段,而可执行文件也可以没有节(但大部分可执行文件都有节)。

在链接过程中,相同名称的节会合并成一个节。以 .text 节为例,每个可重定位文件都有一个 .text 节,它们被链接器合并成一个大的 .text 节,并存放在输出的可重定位文件或者可执行文件中。
3 符号表(symbol table)和字符串表(string table)
在写程序时,一个文件可以访问另一个文件中定义的变量和函数。这些变量和函数统称为符号(symbol)。其他文件可以访问的符号称为全局符号(global symbol),只有文件内部可以访问的符号称为本地符号(local symbol)。这与 C 语言的 static 关键字的功能是相同的。
如果一个文件引用了另一个文件的符号,这个符号也会被记录在引用者中,称为未定义符号(undefined symbol)。在最终链接成可执行程序时,所有的未定义符号都应该可以找到同名的全局符号,否则就会链接失败。
一个符号除了需要记录它的名字,以便其他文件引用,还需要记录它出现在哪个节中和它在节中的偏移量。这些信息以数组的形式连续地存储在文件中,这个数组称为符号表(symbol table)。符号表是一种特殊的节,它的名字是 .sym。
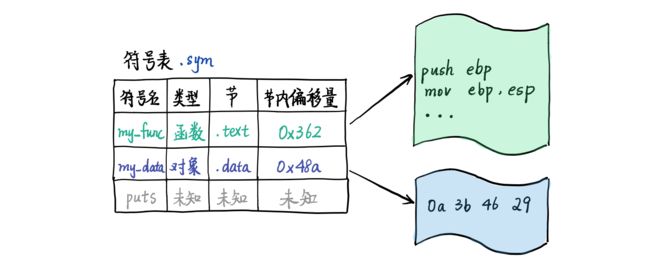
到目前为止,我们发现 ELF 文件中有两处需要存储字符串,一处是节的名字,另一处是符号的名字。因为字符串的长度是可变的,如果将其直接存在节头和符号表中,就需要预先分配足够的空间,这会造成大量空间被浪费。为了节约字符串的存储空间,ELF 文件中的所有字符串都存放在一个特殊的节中,称作字符串表(string table),它的节名是 .str。
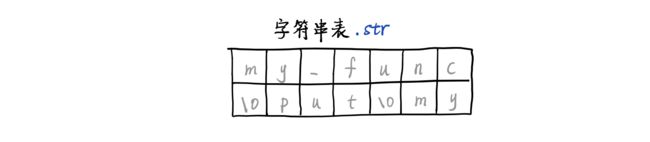
所有的字符串都是以 0 结尾的 C 风格字符串,它们在字符串表中连续存储。其他地方通过它们在字符串表中的下标来引用它们:ELF 头记录了字符串表在节头表中的下标,节头记录了节名称在字符串表中的下标;每个符号表都与一个字符串表关联,每个符号都记录了它的名称在关联的字符串表中的下标。通过这些信息,链接器就可以找到节名和符号名。
4 重定位表(relocation table)
虽然我们现在可以引用其他文件中定义的符号,但我们仍未解决一个重要的问题。
访问全局变量的操作通常会被编译器翻译成访问内存地址的指令。然而,可重定位文件中的节只记录了它在文件中的位置,而不像段一样记录它在内存中的位置,因此我们并不知道文件中定义的全局变量的内存地址。除此之外,如果一个文件引用了另一个文件定义的全局变量,那么直到将它们链接起来之前,我们都不可能知道这个全局变量的内存地址。
进一步地说,直到最终链接成可执行文件时,我们才能知道全局变量和函数的内存地址,在此之前我们始终无法生成访问它们的指令。
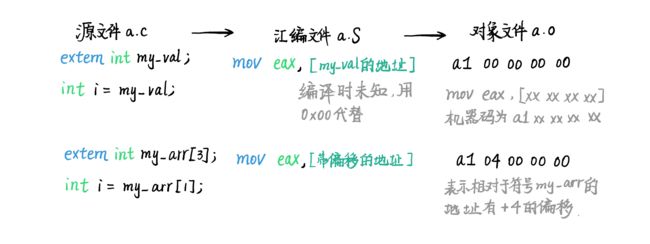
ELF 文件的做法是:仍然按照正常的流程生成访问这些全局变量和函数的指令,但是在内存地址部分填写 0,并且将这些占位 0 的出现的位置记录在 ELF 文件中。在确定了所有这些符号的内存地址后,将占位 0 改成正确的内存地址。
如果访问的是全局数组中的某个元素或者全局结构的某个成员,我们会将元素或成员的偏移量当作占位符写在内存地址出现的地方。在确定了符号的内存地址后,将这两者相加就可以得到正确的内存地址。这个偏移量被称作 addon 。
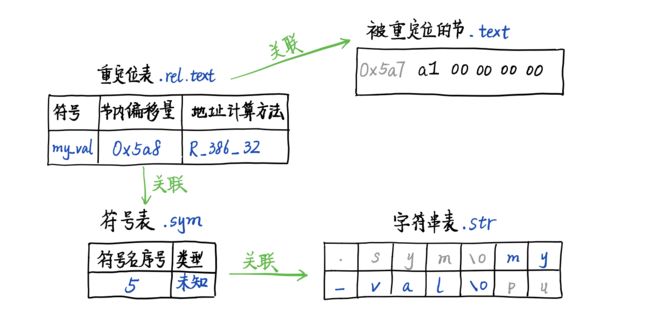
记录这些占位符出现位置的结构称为重定位表(relocation table)。它也是一种特殊的节,而且在文件中不只有一个。每个需要重定位的节都有一个与之对应的重定位表,重定位表的名字就是在被重定位的节名前加上 .rel 或者 .rela。.text 的重定位表是 .rel.text 或者 .rela.text。
之所以有这两种命名方式,是因为重定位表有两种略有不同的格式。.rel 格式的重定位表将 addon 写在内存地址出现的位置,当作占位符,如同前面描述的一样;而 .rela 格式的重定位表将 addon 写在重定位表中,而不是被重定位的位置上。
因为重定位需要符号的内存地址,所以每个重定位表除了与被重定位的节相关联,也与符号表相关联。综合来说,重定位表的每个表项(entry)都记录了四种信息:需要重定位的占位符在节中的偏移量、所引用符号在符号表中的下标、重定位时的地址计算方式和addon。
常见的地址计算方式有两种:
| 名称 | 计算方式 |
|---|---|
| R_386_32 | 符号的内存地址 + Addon |
| R_386_PC32 | 符号的内存地址 + Addon - PC |
PC 指的是程序计数器,该寄存器记录了当前指令所在的内存地址。R_386_PC32 用于相对于 PC 的寻址,通常用于生成位置无关代码(PIC)。
在链接成可执行文件时,链接器首先合并相同的节,然后确定节在内存中的位置,组成段。这时候,链接器就可以计算出所有的符号在内存中的地址。接下来链接器遍历所有的重定位表,将每个需要重定位的位置改写为真正的内存地址,就完成了重定位操作。这样生成的程序就可以被操作系统加载到内存中执行了。
5 小结
- 记录如何将程序加载到内存的结构是段。每个段有如下属性:
- 段在文件中的位置和长度
- 段在内存中的位置和长度
- 段的内存权限
- 记录 ELF 文件中各个部分的结构是节。每个节有如下属性:
- 节的名称
- 节的类型
- 节在文件中的位置
- 与它关联的其他的节的下标
- 符号表与字符串表关联
- 重定位表与符号表和被重定位的节关联
- 全局变量和函数统称为符号。
- 符号有名称
- 每个符号对应一个节和节内偏移
- 按类型,符号可以分成:对象(变量)和函数
- 按作用域,符号可以分成:全局符号和局部符号
- 只是引用而未定义的符号称为未定义符号
- 节名和符号名存储在字符串表中。
- 用于将程序中的占位符改写为内存地址的结构称为重定位表。
- 每个需要重定位的节都有一个与之对应的重定位表
- 每个重定位表项与节中的偏移量和一个符号对应
- 重定位的两种计算方式
- R_386_32 = 符号地址 + Addon
- R_386_PC32 = 符号地址 + Addon - PC
6 参考文献
ELF Format 是描述 ELF 文件格式的文档,只有 60 页但面面俱到地讲解了静态链接和动态加载的原理,是了解 ELF 文件的必读材料。然而这个版本已经略有过时,如果按照这个文档去分析现在的 ELF 文件,会发现一些新的属性在文档中是缺失的。尽管如此,因为这个本手册比较薄,所以它的可读性很好,建议在阅读更详细的文档前先读一下这个文档。
Oracle 的 ELF 文档 是描述 ELF 文件格式最详细和最新的文档,适合当作手册来查阅。
Eli Bendersky 的 Load-Time Relocation of Shared Libraries 是讲解共享对象加载原理的文章。共享对象按照代码是否是位置无关的分成两种,本文讲解的是没有开启 PIC (位置无关代码)选项下共享对象的加载方式,它在原理上与链接是相同的。本文有代码和反汇编等实例,适合读者去更加深入而具体地了解链接的过程。