计算机视觉概述
computer vision 针对视觉数据的研究
视觉传感器的增长和发展(eg 手机)
超级多的视觉数据
思科2015研究:估计到2017 互谅网上大约80%的流量都是视频
但是视觉数据很大,接下来的问题就是如何用算法开发和利用这些数据
视觉数据真的很难理解
另一个统计youtube 每一秒 就有长达5h的视频传到youtube(eg 我的一个朋友,网易实习,视频标记,分类)
计算机视觉跨学科领域(生物,物理,cs,math)。。。
cv历史背景
视觉的历史很久很久以前,水里的动物进化出了眼睛,以为澳大利亚研究者,进化出眼睛,视力功能促进了物种数量的爆炸。视觉对于智慧的动物至关重要。
照相机的历史,留住世界。
60s研究动物的视觉处理机制,用猫来研究,观察什么会引起神经皮层的反应。视觉处理起始于视觉世界的简单结构,边缘。再认识复杂的。
《vision》david marr 70s
边缘,曲线,2.5曲面----》3d模型
同样是70s,识别和表示现实世界的试题,每个对象都由简单的几何图组成
80s,重建和识别视觉空间
目标分割
2000 face detection,adaboost实时面部检测
2006 fujjika面部检测的相机
90-00 一个非常有影响力的思想方法是:基于特征的目标识别,SIFT特征
某些特征在变化中具有整体性和不变性,所以目标识别的首要任务就是在目标上确认这些关键的特征。
整体场景识别,空间金字塔特征,方向梯度直方图
2006-2012 pascal visual object challenge 目标识别的数据集
训练数据不够,出现过拟合,组件ImageNet数据集(目标检测)
imagenet大规模视觉是被竞赛,140图像,1000类别
2012 错误率显著下降。--CNN算法(重点)
图像分类问题
2015 微软残差网络 152层
1998手写数字识别,类似2012的alexnet网络
突破性进展
1 计算能力提升,GPU具有超高并行计算能力
2 data 带标签数据集Pascal imagenet
Lecture02
image classification pipeline
图像是一堆数字,每个数字三个值组成rgb
图像识别有很多挑战:illumination deformation变形,遮挡,背景干扰
数据驱动方法
之前使用硬编码规则,计算图像边缘,将形状分类号,但是这样不可推演,对于每一个物体都要重新编写一套规则
现在:使用数据驱动的训练,抓取数据集,训练机器分类图像,总结,生成一个模型,来识别新的图像

训练函数 接受输入图片和标签输出 模型
预测函数 接受模型 对图片预测

寻找最相近的图片

在训练集中找到最相似的图片,找到其标签,这个时候就可以说测试图片是什么类别
NN分类器
对于两张图片比较
什么样的比较函数
曼哈顿距离:



k赋值大,决策边缘光滑
白色区域表示没有获得k邻近的投票,没有最近的点
k-最近邻算法

曼哈顿距离 每个像素之前的距离总总和
欧氏距离(距离是确定的,无论在什么坐标系中)


与实际解决的问题有关的超参数
机器学习中,我们关心的不是尽可能拟合,而是要让我们的分类器,我们的方法,在训练集以外的未知数据上表现更好。
 image.png
image.png
测试集是个我们的算法一个评估,即在没遇到的数据上算法表现将会如何
 image.png
image.png
验证集,分验证集和测试集,最后一步接触到测试集,确保测试集数据得到严格的控制
 image.png
image.png
交叉验证适合于小的数据集
 image.png
image.png
深度学习中,大型模型不使用
 image.png
image.png
knn不适合用于图像分类

维度灾难 高维空间的像素很多


线性分类
linear classification

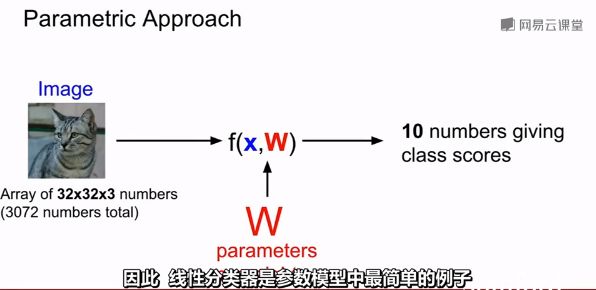




但是在现在参数化的过程中,


测试的时候我们需要的是参数

b是偏置项

线性分类是一种模板匹配方法

线性分类器每个类别只能学习一个模板

-
回顾:
 image.png
image.png
 image.png
image.png
线性分类器可以解释为每个种类的学习模板,对图里的每个像素以及10个分类中的一类,矩阵w里都有一些对应的项,告诉我们那个像素,对那个分类有多少影响,也就是说矩阵w里的每一行,都对应一个分类模板,如果我们解开这些行的值(成图片的大小),那么每一行又分别对应一些权重,每个图像像素值和对应的那个类别的一些权重,将这行分解回图像的大小,我们
就可以可视化学到的每个类的模板
还有一种对线性分类器的解释是,学习像素在高维空间的一个线性决策边界,其中高伟空间就对应了图片能取到的像素密度值
如何选择w?
损失函数






定量的衡量w是好是坏


给出y的预测
二元svm。两个类,要么是正例要么是负例,推广到多分类SVM(支持向量机),推广到多个类别识别



SVM函数只关注于正确的分数比
一个损坏函数的全部意义在于量化不同的错误到底有多坏
加入正则项

其他损失函数:
Softmax loss

目标是促使我们计算得到的概率分布,就是通过softmax计算的结果,去匹配上述的目标概率分布,即正确的类别应该具有几乎所有的概率
svm vs softmax?
优化函数
optimization
对于参数w的一些设置,w所带来的损失,使用迭代,改进

这就是普遍使用的方法:梯度下降

函数下降最快的地方


最后网络收敛
步长是一个超参数,在那个方向前进多少距离,这个步长也被叫做学习率
(他是你需要设定的一个重要参数)