Lua Table的理解
-
在table 中的散列表去取元素
const TValue *luaH_get (Table *t, const TValue *key) { switch (ttype(key)) { // 传入的key为Nil。直接返回nil case LUA_TNIL: return luaO_nilobject; // 如果是string类型。 case LUA_TSTRING: return luaH_getstr(t, rawtsvalue(key)); case LUA_TNUMBER: { int k; lua_Number n = nvalue(key); lua_number2int(k, n); if (luai_numeq(cast_num(k), nvalue(key))) /* index is int? */ return luaH_getnum(t, k); /* use specialized version */ /* else go through */ } default: { Node *n = mainposition(t, key); do { /* check whether `key' is somewhere in the chain */ if (luaO_rawequalObj(key2tval(n), key)) return gval(n); /* that's it */ else n = gnext(n); } while (n); return luaO_nilobject; } } } const TValue *luaH_getstr (Table *t, TString *key) { // t->node[i] 获取对应的散列桶的位置 Node *n = hashstr(t, key); do { /* check whether `key' is somewhere in the chain */ // 链表对应的元素为string value->gc->ts == key 则在node中取出value if (ttisstring(gkey(n)) && rawtsvalue(gkey(n)) == key) return gval(n); /* that's it */ else n = gnext(n); //上面没有获取则在Node->TKey->nk->next 查找到链表上的下一个元素 } while (n); return luaO_nilobject; } const TValue *luaH_getnum (Table *t, int key) { // 先在数组查找. /* (1 <= key && key <= t->sizearray) */ if (cast(unsigned int, key-1) < cast(unsigned int, t->sizearray)) return &t->array[key-1]; else { // 不满足则在散列表中查找,重复上面的过程。先找到散列桶,遍历链表进行查找。 lua_Number nk = cast_num(key); Node *n = hashnum(t, nk); do { /* check whether `key' is somewhere in the chain */ if (ttisnumber(gkey(n)) && luai_numeq(nvalue(gkey(n)), nk)) return gval(n); /* that's it */ else n = gnext(n); } while (n); return luaO_nilobject; } } 直接插入元素。插入元素之前会根据传入的key判断TValue是否存在。分别是luaH_set ,luaH_setnum,luaH_setstr,三个func会根据传入的key判断TValue是否存在,如果存在则返回,但是内部并不会进行实际的修改或添加。返回TValue* 修改会放在外面。分别看一下这三个Api
- TValue *luaH_setstr (lua_State *L, Table *t, TString *key)
TValue *luaH_setstr (lua_State *L, Table *t, TString *key) {
const TValue *p = luaH_getstr(t, key);
// 不是nil,则返回Tvalue
if (p != luaO_nilobject)
return cast(TValue *, p);
else {
// 如果不存在则重新new一个新的Tvalue。对应的是Node的value。返回给外界。
TValue k;
setsvalue(L, &k, key);
return newkey(L, t, &k);
}
}
const TValue *luaH_getstr (Table *t, TString *key) {
// 获取对应的散列桶
Node *n = hashstr(t, key);
// 遍历链表取出对应的节点Node的value返回。
do { /* check whether `key' is somewhere in the chain */
if (ttisstring(gkey(n)) && rawtsvalue(gkey(n)) == key)
return gval(n); /* that's it */
else n = gnext(n);
} while (n);
return luaO_nilobject;
}
- TValue *luaH_setnum (lua_State *L, Table *t, int key)
TValue *luaH_setnum (lua_State *L, Table *t, int key) {
// 根据数字找到对应的TValue * 元素
const TValue *p = luaH_getnum(t, key);
// 有则直接返回,没有则去创建一个新的TValue并返回。
if (p != luaO_nilobject)
return cast(TValue *, p);
else {
TValue k;
setnvalue(&k, cast_num(key));
return newkey(L, t, &k);
}
}
const TValue *luaH_getnum (Table *t, int key) {
// 先在数组中去查找,如果key在数组的范围内key>0 < sizearray。则直接在数组中返回
/* (1 <= key && key <= t->sizearray) */
if (cast(unsigned int, key-1) < cast(unsigned int, t->sizearray))
return &t->array[key-1];
else { // 否则的话则找到对应的散列桶,然后遍历链表去寻找到对应的元素,返回Node对应的Value对象。
lua_Number nk = cast_num(key);
Node *n = hashnum(t, nk);
do { /* check whether `key' is somewhere in the chain */
if (ttisnumber(gkey(n)) && luai_numeq(nvalue(gkey(n)), nk))
return gval(n); /* that's it */
else n = gnext(n);
} while (n);
return luaO_nilobject;
}
}
- const TValue *luaH_get (Table *t, const TValue *key) 是一个大的口子,在里面会根据传入的key的类型,调用上面提到的get_number和getstr的func。当找不到的时候回调用newKey 创建一个新的Value并返回给外界。
- 插入一个新的key流程如下
static TValue *newkey (lua_State *L, Table *t, const TValue *key) {
// 获取散列桶的位置
Node *mp = mainposition(t, key);
// 如果存在的话。串联到其他的散列桶下
if (!ttisnil(gval(mp)) || mp == dummynode) {
Node *othern;
Node *n = getfreepos(t); /* get a free place */
if (n == NULL) { /* cannot find a free place? */
rehash(L, t, key); /* grow table */
return luaH_set(L, t, key); /* re-insert key into grown table */
}
lua_assert(n != dummynode);
othern = mainposition(t, key2tval(mp));
// 让n串到mp的next节点。n替换掉mp之前的位置。
if (othern != mp) { /* is colliding node out of its main position? */
/* yes; move colliding node into free position */
while (gnext(othern) != mp) othern = gnext(othern); /* find previous */
gnext(othern) = n; /* redo the chain with `n' in place of `mp' */
*n = *mp; /* copy colliding node into free pos. (mp->next also goes) */
gnext(mp) = NULL; /* now `mp' is free */
setnilvalue(gval(mp));
}
else { /* colliding node is in its own main position */
/* new node will go into free position */
gnext(n) = gnext(mp); /* chain new position */
gnext(mp) = n;
mp = n;
}
}
// 如果对于的桶不存在。则直接进行Node的key的赋值,并把空的Value返回。
gkey(mp)->value = key->value; gkey(mp)->tt = key->tt;
luaC_barriert(L, t, key);
lua_assert(ttisnil(gval(mp)));
return gval(mp);
}
-
上面代码当找不到对应的freeSpace的时候会触发重散列的过程。在开发中我们尽量避免过多的重散列,过多的重散列是非常消耗性能的。
static void rehash (lua_State *L, Table *t, const TValue *ek) { int nasize, na; int nums[MAXBITS+1]; /* nums[i] = number of keys between 2^(i-1) and 2^i */ int i; int totaluse; // 初始化nums for (i=0; i<=MAXBITS; i++) nums[i] = 0; /* reset counts */ nasize = numusearray(t, nums); /* count keys in array part */ totaluse = nasize; /* all those keys are integer keys */ totaluse += numusehash(t, nums, &nasize); /* count keys in hash part */ /* count extra key */ nasize += countint(ek, nums); totaluse++; /* compute new size for array part */ // 对数组部门进行重新排列 na = computesizes(nums, &nasize); /* resize the table to new computed sizes */ // 对散列表进行调整。 resize(L, t, nasize, totaluse - na); }保存到array中的原则。所含元素的数量大于50%的最大索引。数组在每个2次方索引 容纳元素的数量大于50%。
key保存在数组中的位置为
 image.png
image.png
- 比如number[0] = 1; 满足 key为1 满足上面的条件。而且 数组数量1 >
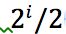 image.png
image.png
同理可以继续分析
- number[1] = 1; 满足数量2>
 image.png
image.png - number[5] = 1 4不满足
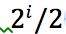 image.png
image.png
。因此key为5分到散列表
具体的重排列算法如下
static int computesizes (int nums[], int *narray) {
int i;
int twotoi; /* 2^i */
int a = 0; /* number of elements smaller than 2^i */
int na = 0; /* number of elements to go to array part */
int n = 0; /* optimal size for array part */
for (i = 0, twotoi = 1; twotoi/2 < *narray; i++, twotoi *= 2) {
if (nums[i] > 0) {
a += nums[i];
if (a > twotoi/2) { /* more than half elements present? */
n = twotoi; /* optimal size (till now) */
na = a; /* all elements smaller than n will go to array part */
}
}
if (a == *narray) break; /* all elements already counted */
}
*narray = n;
lua_assert(*narray/2 <= na && na <= *narray);
return na;
}
排列完数组后会对散列表部分进行resize。代码如下
static void resize (lua_State *L, Table *t, int nasize, int nhsize) {
int i;
// 数组的size
int oldasize = t->sizearray;
// 散列表大小的
int oldhsize = t->lsizenode;
Node *nold = t->node; /* save old hash ... */
// size 变大。则 重新分配数组和散列表
if (nasize > oldasize) /* array part must grow? */
setarrayvector(L, t, nasize);
/* create new hash part with appropriate size */
setnodevector(L, t, nhsize);
// 数组变下,则分配数组元素到散列表上
if (nasize < oldasize) { /* array part must shrink? */
t->sizearray = nasize;
/* re-insert elements from vanishing slice */
// nasize大小开始到新的大小,
for (i=nasize; iarray[i]))
//对应值设置到散列表上
setobjt2t(L, luaH_setnum(L, t, i+1), &t->array[i]);
}
/* shrink array */ /* 重新分配数组空间,去掉后面溢出部分*/
luaM_reallocvector(L, t->array, oldasize, nasize, TValue);
}
/* re-insert elements from hash part */ 将旧的散列表上的Node从后到前设置到新的散列表上
for (i = twoto(oldhsize) - 1; i >= 0; i--) {
Node *old = nold+i;
if (!ttisnil(gval(old)))
setobjt2t(L, luaH_set(L, t, key2tval(old)), gval(old));
}
// 释放老的hash表空间
if (nold != dummynode)
luaM_freearray(L, nold, twoto(oldhsize), Node); /* free old array */
}