
1. 最小二乘法(Least squares)
最小二乘法是一种数学优化技术,它通过最小化误差的平方来寻找数据的最佳函数匹配。
先引入一些先验知识:
1. 高斯分布(Gaussian distribution)
-.-
若随机变量X服从一个位置参数为 μ(数学期望) 、尺度参数为 σ(标准差)的概率分布,记为:X~(μ, σ2)。其概率密度函数为:
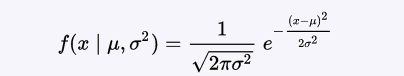
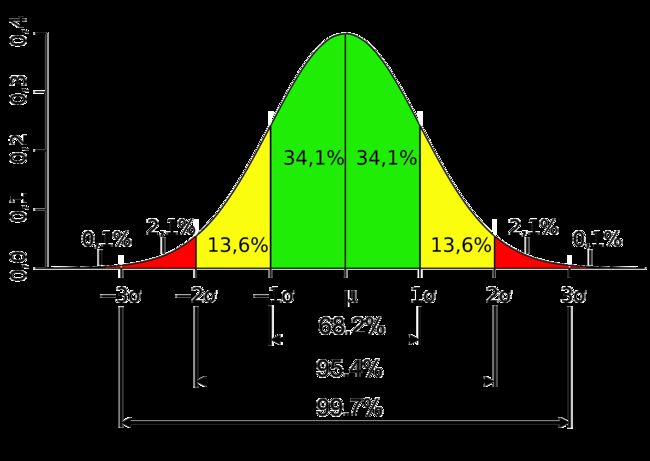
高斯分布曲线:
2. 拉普拉斯分布(Laplace distribution)
-.-
可以看作是两个不同位置的指数分布背靠背拼接在一起,所以它也叫作 双指数分布。其中, μ 是位置参数, b > 0 是尺度参数。
·

拉普拉斯分布曲线:

3. 最大似然估计(Maximum likelihood estimation, ML)
-.-
假设有一组独立同分布的观测样本 x 1, x 2, …, x n ,它们来自一个概率密度函数为 f 0 = f (·|θ 0) 的分布。其中, θ 0为该分布未知的真实参数。而我们的目标是找到最接近 θ 0 的参数估计 θ' 。为了做到这一点,我们引入了最大似然估计。对于前面提到的n个独立同分布的观测样本,其联合密度函数为:
·
························ f ( x 1, x 2, …, x n | θ) = f ( x 1| θ) f ( x 2| θ) ··· f ( x n| θ)
·
考虑到观测样本是该函数的固定参数,而 θ 才是该函数的变量参数,这样我们就可以定义该函数为 似然函数:
.


对两边取自然对数后得到 对数似然,然后,我们可以通过最大化对数似然来求解 θ 0 的最大似然估计 θ ML 。
·
4. 最大后验估计(Maximum a posteriori estimation, MAP)
-.-
最大后验概率估计可以获得对实验数据中无法直接观察到的量的点估计。它与最大似然估计中的经典方法有密切关系,但是它使用了一个增广的优化目标,进一步考虑了被估计量的 先验概率分布。所以最大后验概率估计可以看作是规则化的最大似然估计。
假设 θ 存在一个先验分布 g,利用贝叶斯定理,我们可以得到 θ 的后验分布为:

最大化该分布得到 MAP(当先验 g 是均匀分布时,MAP与MLE重合):

对上式取自然对数得:
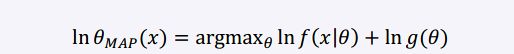
Note: MLE不考虑先验知识,很容易造成过拟合现象。MAP 比 MLE 多了一项先验分布 g( θ),这一项正好起到了 正则化的作用。如果假设 g( θ) 服从高斯分布,则相当于 L2 norm;如果假设 g( θ) 服从拉普拉斯分布,则相当于 L1 norm 。
现在,我们来理解(线性)最小二乘法。假设线性回归模型具有如下形式:

其中,x∈R1xd,W∈Rdx1,误差 ϵ∈R。
若已知,X = (X1, X2, …, Xn)∈Rnxd,y∈Rnx1,如何求解参数 W?
策略: 假设 ϵi ~ N(0, σ2),则 yi ~ N(XiW, σ2),用最大似然估计可推得最小二乘(所以最小二乘是基于高斯分布的):

令上式一阶导数等于0,得: XTX W = XTy,若 XTX 非奇异(即 XTX 的行列式不为0),则 W 有唯一解: W = (XTX)-1XTy (normal equations)
a). 如果我们假设参数W 的先验分布为 Wi ~ N(0, τ2),那么用最大后验估计可推得 Ridge 回归(L2 正则化):

b). 如果我们假设参数W 的先验分布为 Wi ~ Laplace(0, τ2),那么用最大后验估计可推得 LASSO 回归(L1 正则化):
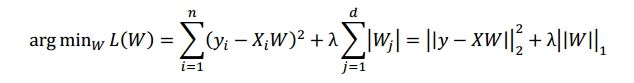
现在,我们可以给出正则化的概率角度解释: 正则化项相当于参数 W 的先验分布(若该分布是 μ=0 的高斯分布,就是 L2 正则化;若该分布是 μ=0 的拉普拉斯分布,则是 L1 正则化),通过加入正则化项,限制参数空间,来控制模型复杂度,从而防止过拟合。
从下图中可以看出,相比于 L2/Gaussian,L1/Laplace 趋向于接受大的(这里指绝对值)以及非常小的参数值,这一特点符合 "L1 比 L2 更容易获得稀疏解" 这一结论。

正则化的几何角度解释(参数/模型空间被限定在了下图的涂色区域内):

从图中我们可以看到 L1 比 L2 更容易获得稀疏解, L2 正则化只有在参数 W 初始化值为0(但是,通常我们不会让权重初始化为0的)的情况下才能获得稀疏解。所以, L1 会趋向于选择少量的特征,而其他特征的权重(参数)都是0,而 L2 会选择更多的特征,这些特征的权重(参数)都会接近于0。 L1 在特征选择(有监督)的时候也非常有用,而 L2 就只是一种正则化手段而已。当作为正则化手段的时候,L2 通常是好于 L1 的,所以通常我们会选择 L2 。
2. Frequentist statistics vs. Bayesian statistics
统计推断的主张和思想,大体可以纳入到两个体系之内:频率学派(Frequentist statistics)和贝叶斯学派(Bayesian statistics)。
Frequentist statistics: 认为需要推断的参数 W 是固定(唯一)且未知的常数。而样本 X 是随机的,其着眼点在样本空间,相关的概率计算都是针对 X 的分布。所以他们的方法论一开始就是从 "哪个参数最有可能产生样本的真实分布" 这个角度出发,于是就有了最大似然(maximum likelihood)以及置信区间(confidence interval)。 ---> [ 求得唯一的最优参数 W ]
Bayesian statistics: 认为参数 W 是随机变量,而样本 X 是固定的,其着眼点在参数空间,重视参数 W 的分布。所以参数空间里的每个值都有可能是真实模型所使用的值,区别只是概率不同而已。于是才会引入先验分布 (prior distribution) 和后验分布(posterior distribution)这样的概念来设法找出参数空间上的每个值的概率。---> [ 求得的是参数 W 的分布 ]
Note: 最大后验估计(MAP)是对贝叶斯后验分布进行最大化估计,得到唯一的最优参数 W,这样做是因为对于大多数模型涉及到贝叶斯后验分布的操作大多很难处理,而 MAP 提供了一个可行的近似估计。
所以,在机器学习中,许多情况下贝叶斯概率推断更能解决观察者推断的问题,而绕开了关于事件本体的讨论(过多的关注训练样本容易产生过拟合,e.g. 最大似然估计)。
既然这里说到了正态分布,那我们就延伸一下,谈谈U分布,T分布,F分布和X2分布。
<1>. U分布
对于任意一个均值为 μ,标准差为 σ 的正态分布,都可以通过变换得到标准正态分布。变换方法:将变量 X 变换为 u,u = (X - μ) / σ,u 值的分布即为U分布(标准正态分布)。
<2>. T分布
从正态分布的同一总体中,随机抽取样本含量相等的若干组样本,分别计算它们的均值,这些样本均值的标准差(standard deviation)称为标准误(standard error)。标准误大,说明抽样误差大,用样本均值估计总体均值的可靠性小。
由于这个总体呈正态分布 N(μ, σ),这些样本均值(假设有 n 组样本,每组样本有 m 个采样值)的频数分布任是以 μ 为中心的正态分布。这些均值的标准差,即标准误,可以通过如下公式计算得到:

实际工作中,标准误常用 S 估算得到(因为我们并不知道 σ 的大小),其计算公式如下(其中小 x 表示每组样本的均值):

而 t 值就是样本均值与总体均值 μ 的差数除以 S ,即
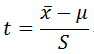
而 t 值的频数分布就是统计学上的T分布。下图为T分布的概率密度函数(PDF),其中 v = n -1 表示自由度,黑色曲线就是标准正态分布。
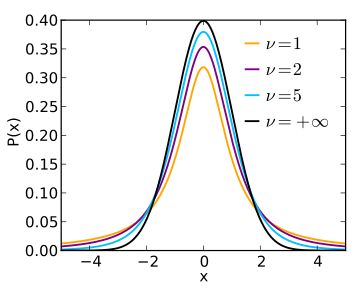
<3>. 卡方分布(X2分布)
假设 Z1, ..., Zk 是 k 个相互独立且服从标准正态分布 N(0,1) 的随机变量,则这 k 个随机变量的平方和 Q 服从自由度为 k 的 X2分布,记作:Q ~ X2(k) 。其均值为 k,方差为 2k 。下图为 X2 分布的概率密度函数:

<4>. F分布
假设 X,Y 两个独立的随机变量,X 服从自由度为 n 的 X2分布,Y 服从自由度为 m 的 X2分布,则这两个独立的 X2分布 除以各自的自由度以后的比率服从F分布,即:
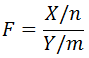
下图为F分布的概率密度函数:

3. 广义线性模型(Generalized Linear Model, GLM)
由于GLM是基于指数分布族(The exponential family),所以先引入一下指数分布族。指数分布族是指可以表示为指数形式的一类概率分布,指数分布的形式如下:
其中,η 为分布的自然参数(nature parameter);T(y) 是充分统计量(sufficient statistic),通常 T(y) = y 。当参数 a、b、T 都固定的时候,就定义了一个以 η 为参数的函数族。
实际上线性最小二乘回归和Logistic回归都是广义线性模型的一个特例。当随机变量 y 服从高斯分布,那么得到的是线性最小二乘回归(前面已经提到过),当随机变量 y 服从伯努利分布,则得到的是Logistic回归。
· 伯努利分布(Bernoulli distribution)
对于 Bernoulli(φ),y ϵ {0,1},有 p(y=1;φ) = φ,p(y=0;φ) = 1−φ,其期望为 φ 。将其推导成指数分布形式:

将其与指数族分布形式对比,可以看出:

从上述式子可以看到,η 的形式与logistic回归用到的sigmoid函数一致。
· 高斯分布(Gaussian distribution)
将高斯分布推导成指数分布形式:
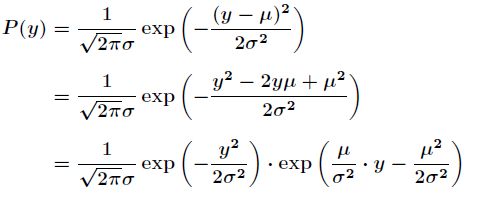
将其与指数族分布形式对比,可以看出:

通过这两个例子,我们大致可以得出:η 以不同的映射函数与其它概率分布函数中的参数发生联系,从而得到不同的模型。广义线性模型正是将指数分布族中的所有成员(每个成员正好有一个这样的联系)都作为线性模型的扩展,通过各种非线性的连接函数将线性函数映射到其他空间,从而扩大了线性模型可解决的问题。
下面给出GLM的形式化定义,GLM 有三个假设:
(1) 给定样本 x 与参数 θ,样本输出 y 服从指数分布族中的某个分布,即P(y|x;θ) ~ ····Exponential Family(η);
(2) 给定一个 x,预测T(y)的期望,即目标函数为 hθ(x) = E[T(y)|x];
(3) η 和 x 之间是线性的,即 η = θTx 。
依据这三个假设,我们可以推导出logistic回归模型与最小二乘回归模型。
伯努利分布 → logistic回归模型 (用于二分类问题):

高斯分布 → 最小二乘回归模型(用于线性回归问题):
[ 广义线性模型通过假设一个概率分布,得到不同的模型,而梯度下降和牛顿方法等优化方法都是为了求解模型中的线性部分 (θTx) 的参数 θ 的。]