问题随机排序,无论先后,全网收集!(搬家完成我又回来了!)
1.runtime如何通过selector找到对应的IMP地址?(分别考虑类方法和实例方法)
答案:
每一个类对象中都一个方法列表,方法列表中记录着方法的名称,方法实现,以及参数类型,其实selector本质就是方法名称,通过这个方法名称就可以在方法列表中找到对应的方法实现.
概述(标准概念):
类对象中有类方法和实例方法的列表,列表中记录着方法的名词、参数和实现,而selector本质就是方法名称,runtime通过这个方法名称就可以在列表中找到该方法对应的实现。
struct objc_class {
Class isaOBJC_ISA_AVAILABILITY;
#if !__OBJC2__
Class super_class
const char *name
long version
long info
long instance_size
struct objc_ivar_list *ivars
struct objc_method_list **methodLists
struct objc_cache *cache
struct objc_protocol_list *protocols
#endif
} OBJC2_UNAVAILABLE; 这里声明了一个指向struct objc_method_list指针的指针,可以包含类方法列表和实例方法列表
具体实现 :
在寻找IMP的地址时,runtime提供了两种方法
IMP class_getMethodImplementation(Class cls, SEL name);
IMP method_getImplementation(Method m)
而根据官方描述,第一种方法可能会更快一些
@note /c class_getMethodImplementation may be faster than /c method_getImplementation(class_getInstanceMethod(cls, name)).
对于第一种方法而言,类方法和实例方法实际上都是通过调用class_getMethodImplementation()来寻找IMP地址的,不同之处在于传入的第一个参数不同
类方法(假设有一个类A)
实例方法
class_getMethodImplementation(objc_getMetaClass("A"),@selector(methodName));
class_getMethodImplementation([Aclass],@selector(methodName));
通过该传入的参数不同,找到不同的方法列表,方法列表中保存着下面方法的结构体,结构体中包含这方法的实现,selector本质就是方法的名称,通过该方法名称,即可在结构体中找到相应的实现。
struct objc_method {
SEL method_name
char *method_types
IMP method_imp
}
而对于第二种方法而言,传入的参数只有method,区分类方法和实例方法在于封装method的函数
总结
- 类方法
Method class_getClassMethod(Class cls, SEL name) - 实例方法
Method class_getInstanceMethod(Class cls, SEL name)
最后调用IMP method_getImplementation(Method m) 获取IMP地址。值得注意的是,如果使用第一种方法,即使找不到方法,仍然会返回一个地址(所有无法找到的IMP都返回一个相同的地址),而第二种方法如果找不到IMP时则返回0
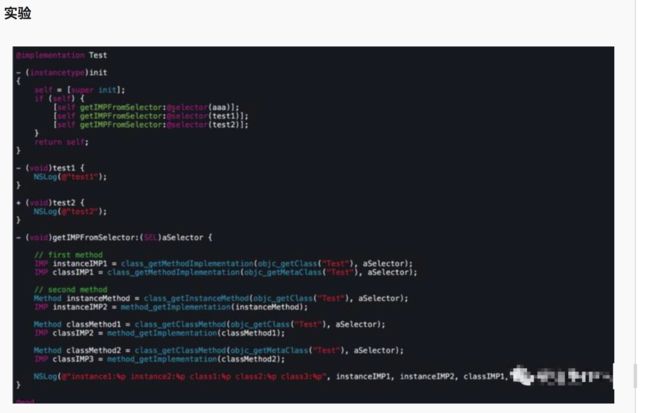 实验.png
实验.png这里有一个叫Test的类,在初始化方法里,调用了两次getIMPFromSelector:方法,第一个aaa方法是不存在的,test1和test2分别为实例方法和类方法
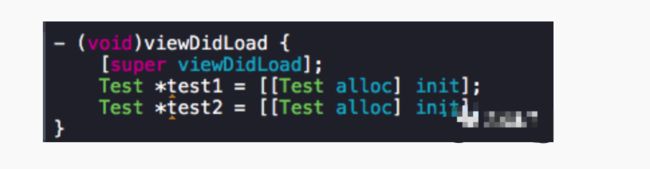 image.png
image.png
然后我同时实例化了两个Test的对象,打印信息如下
 image.png
image.png
大家注意图中红色标注的地址出现了8次:0x1102db280,这个是在调用class_getMethodImplementation()方法时,无法找到对应实现时返回的相同的一个地址,无论该方法是在实例方法或类方法,无论是否对一个实例调用该方法,返回的地址都是相同的,但是每次运行该程序时返回的地址并不相同,而对于另一种方法,如果找不到对应的实现,则返回0,在图中我做了蓝色标记。
还有一点有趣的是class_getClassMethod()的第一个参数无论传入objc_getClass()还是objc_getMetaClass(),最终调用method_getImplementation()都可以成功的找到类方法的实现。
而class_getInstanceMethod()的第一个参数如果传入objc_getMetaClass(),再调用method_getImplementation()时无法找到实例方法的实现却可以找到类方法的实现。
2.使用runtime Associate方法关联的对象,需要在主对象dealloc的时候释放么?
- 在ARC下不需要。
- 在MRC中,对于使用retain或copy策略的需要。
- 在MRC下其实也不需要。
无论在MRC下还是ARC下均不需要。
2011年版本的Apple API 官方文档 - Associative References 一节中有一个MRC环境下的例子:
static char overviewKey;
NSArray *array =
[[NSArray alloc] initWithObjects:@"One", @"Two", @"Three", nil];
// For the purposes of illustration, use initWithFormat: to ensure
// the string can be deallocated
NSString *overview = [[NSString alloc] initWithFormat:@"%@", @"First three numbers"];
objc_setAssociatedObject (
array,
&overviewKey,
overview,
OBJC_ASSOCIATION_RETAIN
);
[overview release];
// (1) overview valid
[array release];
// (2) overview invalid
文档指出
At point 1, the string overview is still valid because the OBJC_ASSOCIATION_RETAIN policy specifies that the array retains the associated object. When the array is deallocated, however (at point 2), overview is released and so in this case also deallocated.
我们可以看到,在[array release];之后,overview就会被release释放掉了。
既然会被销毁,那么具体在什么时间点?
根据 WWDC 2011, Session 322 (第36分22秒) 中发布的内存销毁时间表,被关联的对象在生命周期内要比对象本身释放的晚很多。它们会在被 NSObject -dealloc 调用的 object_dispose() 方法中释放。
对象的内存销毁时间表,分四个步骤:
// 根据 WWDC 2011, Session 322 (36分22秒)中发布的内存销毁时间表
1. 调用 -release :引用计数变为零
* 对象正在被销毁,生命周期即将结束.
* 不能再有新的 __weak 弱引用, 否则将指向 nil.
* 调用 [self dealloc]
2. 子类 调用 -dealloc
* 继承关系中最底层的子类 在调用 -dealloc
* 如果是 MRC 代码 则会手动释放实例变量们(iVars)
* 继承关系中每一层的父类 都在调用 -dealloc
3. NSObject 调 -dealloc
* 只做一件事:调用 Objective-C runtime 中的 object_dispose() 方法
4. 调用 object_dispose()
* 为 C++ 的实例变量们(iVars)调用 destructors
* 为 ARC 状态下的 实例变量们(iVars) 调用 -release
* 解除所有使用 runtime Associate方法关联的对象
* 解除所有 __weak 引用
* 调用 free()`
对象的内存销毁时间表:参考链接。
3.objc中的类方法和实例方法有什么本质区别和联系?
类方法:
类方法是属于类对象的
类方法只能通过类对象调用
类方法中的self是类对象
类方法可以调用其他的类方法
类方法中不能访问成员变量
类方法中不能直接调用对象方法
实例方法:
实例方法是属于实例对象的
实例方法只能通过实例对象调用
实例方法中的self是实例对象
实例方法中可以访问成员变量
实例方法中直接调用实例方法
实例方法中也可以调用类方法(通过类名)
4._objc_msgForward 函数是做什么的,直接调用它将会发生什么?
_objc_msgForward
是 IMP 类型,用于消息转发的:当向一个对象发送一条消息,但它并没有实现的时候,
_objc_msgForward
会尝试做消息转发。
我们可以这样创建一个_objc_msgForward对象:
IMP msgForwardIMP = _objc_msgForward;
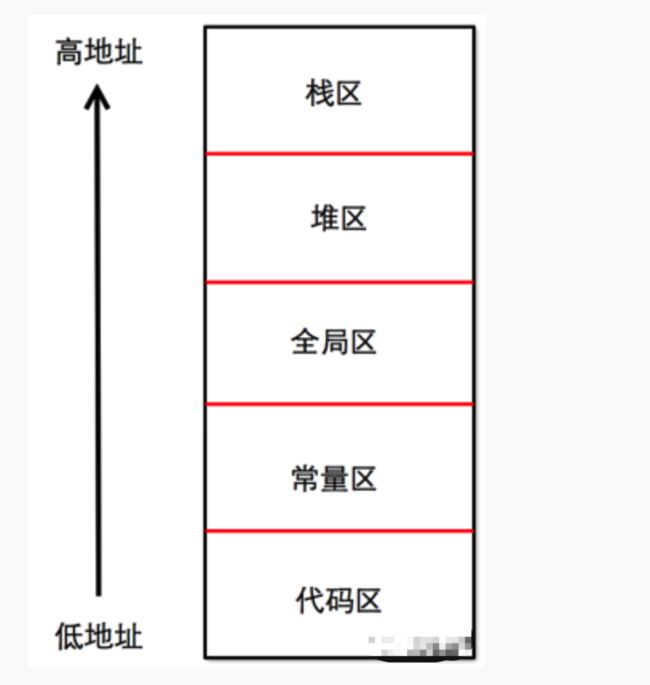
5.介绍下内存的几大区域?
1.栈区(stack) 由编译器自动分配并释放,存放函数的参数值,局部变量等。栈是系统数据结构,对应线程/进程是唯一的。优点是快速高效,缺点时有限制,数据不灵活。[先进后出]
栈空间分静态分配和动态分配两种。
 栈空间分静态分配和动态分配两种.png
栈空间分静态分配和动态分配两种.png
2.堆区(heap) 由程序员分配和释放,如果程序员不释放,程序结束时,可能会由操作系统回收 ,比如在ios 中 alloc 都是存放在堆中
优点是灵活方便,数据适应面广泛,但是效率有一定降低。
 堆区.png
堆区.png
虽然程序结束时所有的数据空间都会被释放回系统,但是精确的申请内存,释放内存匹配是良好程序的基本要素。
4.文字常量区 存放常量字符串,程序结束后由系统释放;
5.代码区 存放函数的二进制代码
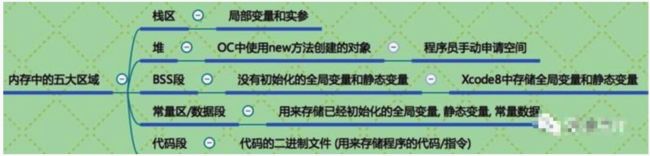 五大区域.png
五大区域.png
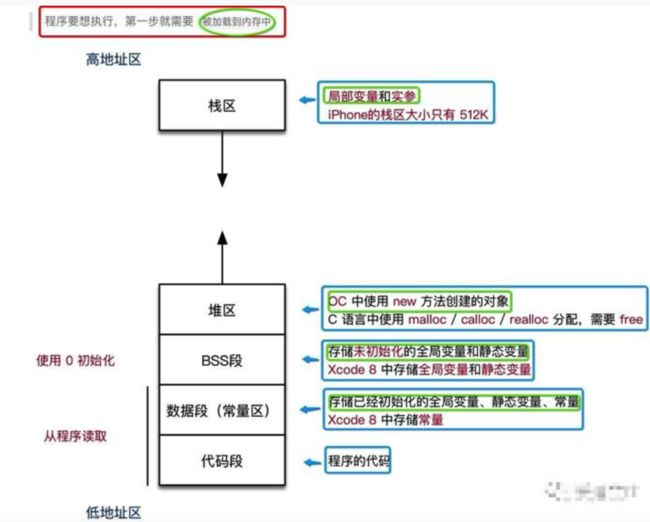 流程.png
流程.png
例子代码:
 例子.png
例子.png
可能被追问的问题一:
1.栈区 (stack [stæk]): 由编译器自动分配释放
局部变量是保存在栈区的
方法调用的实参也是保存在栈区的
2.堆区 (heap [hiːp]): 由程序员分配释放,若程序员不释放,会出现内存泄漏,赋值语句右侧 使用 new 方法创建的对象,被创建对象的所有 成员变量!
3.BSS 段 : 程序结束后由系统释放
4.数据段 : 程序结束后由系统释放
5.代码段:程序结束后由系统释放
程序编译链接 后的二进制可执行代码
可能被追问的问题二:
比如申请后的系统是如何响应的?
栈:存储每一个函数在执行的时候都会向操作系统索要资源,栈区就是函数运行时的内存,栈区中的变量由编译器负责分配和释放,内存随着函数的运行分配,随着函数的结束而释放,由系统自动完成。
注意:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:
1.首先应该知道操作系统有一个记录空闲内存地址的链表。
2.当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
3 .由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中
可能被追问的问题三:
比如:申请大小的限制是怎样的?
栈:栈是向低地址扩展的数据结构,是一块连续的内存的区域。是栈顶的地址和栈的最大容量是系统预先规定好的,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数 ) ,如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
 地址.png
地址.png
栈:由系统自动分配,速度较快,不会产生内存碎片
堆:是由alloc分配的内存,速度比较慢,而且容易产生内存碎片,不过用起来最方便
打个比喻来说:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
6.你是如何组件化解耦的?
一般需要解耦的项目都会多多少少出现,一下几个情况:
耦合比较严重(因为没有明确的约束,「组件」间引用的现象会比较多)
2.容易出现冲突(尤其是使用 Xib,还有就是 Xcode Project,虽说有脚本可以改善)
3.业务方的开发效率不够高(只关心自己的组件,却要编译整个项目,与其他不相干的代码糅合在一起)
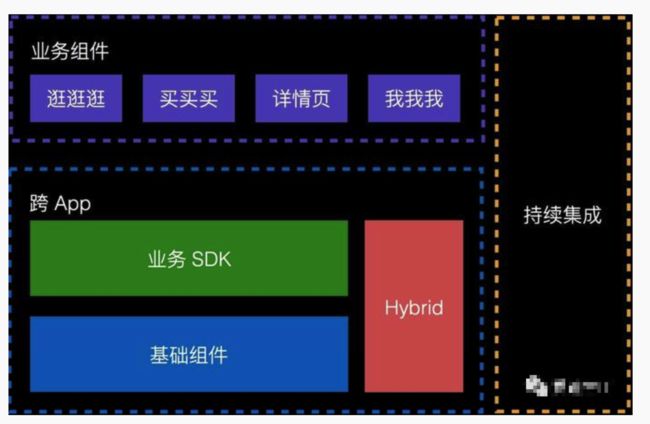
先来看下,组件化之后的一个大概架构
 架构.png
架构.png
组件化」顾名思义就是把一个大的 App 拆成一个个小的组件,相互之间不直接引用。那如何做呢?
组件间通信
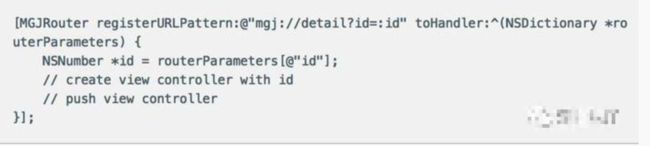
以 iOS 为例,由于之前就是采用的 URL 跳转模式,理论上页面之间的跳转只需 open 一个 URL 即可。所以对于一个组件来说,只要定义「支持哪些 URL」即可,比如详情页,大概可以这么做的
 代码例子.png
代码例子.png
参考答案1
参考答案2
7.runloop内部实现逻辑?
 官方文档.png
官方文档.png
苹果在文档里的说明,RunLoop 内部的逻辑大致如下:
image.png
其内部代码整理如下 :
可以看到,实际上 RunLoop 就是这样一个函数,其内部是一个 do-while 循环。当你调用 CFRunLoopRun() 时,线程就会一直停留在这个循环里;直到超时或被手动停止,该函数才会返回。
RunLoop 的底层实现
从上面代码可以看到,RunLoop 的核心是基于 mach port 的,其进入休眠时调用的函数是 mach_msg()。为了解释这个逻辑,下面稍微介绍一下 OSX/iOS 的系统架构。
 梯形结构.png
梯形结构.png
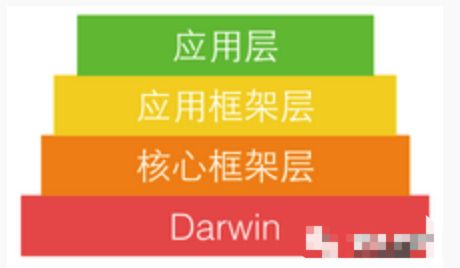
苹果官方将整个系统大致划分为上述4个层次:
应用层包括用户能接触到的图形应用,例如 Spotlight、Aqua、SpringBoard 等。
应用框架层即开发人员接触到的 Cocoa 等框架。
核心框架层包括各种核心框架、OpenGL 等内容。
Darwin 即操作系统的核心,包括系统内核、驱动、Shell 等内容,这一层是开源的,其所有源码都可以在opensource.apple.com里找到。
我们在深入看一下 Darwin 这个核心的架构:
 核心.png
核心.png
其中,在硬件层上面的三个组成部分:Mach、BSD、IOKit (还包括一些上面没标注的内容),共同组成了 XNU 内核。
XNU 内核的内环被称作 Mach,其作为一个微内核,仅提供了诸如处理器调度、IPC (进程间通信)等非常少量的基础服务。
BSD 层可以看作围绕 Mach 层的一个外环,其提供了诸如进程管理、文件系统和网络等功能。
IOKit 层是为设备驱动提供了一个面向对象(C++)的一个框架。
Mach
本身提供的 API 非常有限,而且苹果也不鼓励使用 Mach 的
API,但是这些API非常基础,如果没有这些API的话,其他任何工作都无法实施。在 Mach
中,所有的东西都是通过自己的对象实现的,进程、线程和虚拟内存都被称为"对象"。和其他架构不同, Mach
的对象间不能直接调用,只能通过消息传递的方式实现对象间的通信。"消息"是 Mach 中最基础的概念,消息在两个端口 (port)
之间传递,这就是 Mach 的 IPC (进程间通信) 的核心。
Mach 的消息定义是在头文件的,很简单:
typedef struct {
mach_msg_header_t header;
mach_msg_body_t body;
} mach_msg_base_t;
typedef struct {
mach_msg_bits_t msgh_bits;
mach_msg_size_t msgh_size;
mach_port_t msgh_remote_port;
mach_port_t msgh_local_port;
mach_port_name_t msgh_voucher_port;
mach_msg_id_t msgh_id;
} mach_msg_header_t;
一条 Mach 消息实际上就是一个二进制数据包 (BLOB),其头部定义了当前端口 local_port 和目标端口 remote_port,
发送和接受消息是通过同一个 API 进行的,其 option 标记了消息传递的方向:
mach_msg_return_t mach_msg(
mach_msg_header_t *msg,
mach_msg_option_t option,
mach_msg_size_t send_size,
mach_msg_size_t rcv_size,
mach_port_name_t rcv_name,
mach_msg_timeout_t timeout,
mach_port_name_t notify);
为了实现消息的发送和接收,mach_msg()
函数实际上是调用了一个 Mach 陷阱 (trap),即函数mach_msg_trap(),陷阱这个概念在 Mach中等同于系统调用。当你在用户态调用 mach_msg_trap() 时会触发陷阱机制,切换到内核态;内核态中内核实现的 mach_msg()
函数会完成实际的工作,如下图:
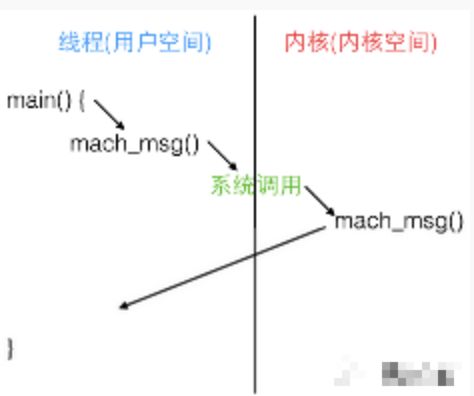 实现.png
实现.png
这些概念可以参考维基百科:System_call、Trap_(computing)。
RunLoop
的核心就是一个 mach_msg() (见上面代码的第7步),RunLoop 调用这个函数去接收消息,如果没有别人发送 port
消息过来,内核会将线程置于等待状态。例如你在模拟器里跑起一个 iOS 的 App,然后在 App 静止时点击暂停,你会看到主线程调用栈是停留在mach_msg_trap() 这个地方。
关于具体的如何利用 mach port 发送信息,可以看看NSHipster 这一篇文章,或者这里的中文翻译 。
关于Mach的历史可以看看这篇很有趣的文章:Mac OS X 背后的故事(三)Mach 之父 Avie Tevanian。
苹果用 RunLoop 实现的功能
首先我们可以看一下 App 启动后 RunLoop 的状态:
可以看到,系统默认注册了5个Mode:
1.kCFRunLoopDefaultMode: App的默认 Mode,通常主线程是在这个 Mode 下运行的。2.UITrackingRunLoopMode: 界面跟踪 Mode,用于 ScrollView 追踪触摸滑动,保证界面滑动时不受其他 Mode 影响。
3.UIInitializationRunLoopMode: 在刚启动 App 时第进入的第一个 Mode,启动完成后就不再使用。
4.GSEventReceiveRunLoopMode: 接受系统事件的内部 Mode,通常用不到。
5.kCFRunLoopCommonModes: 这是一个占位的 Mode,没有实际作用。
你可以在这里看到更多的苹果内部的 Mode,但那些 Mode 在开发中就很难遇到了。
8.你理解的多线程?/谈谈多线程
1.可能会追问,每种多线程基于什么语言?
2.生命周期是如何管理?
3.你更倾向于哪种?追问至现在常用的两种你的看法是?
第一种:pthread
a.特点:
1)一套通用的多线程API
2)适用于Unix\Linux\Windows等系统
3)跨平台\可移植
4)使用难度大
b.使用语言:c语言
c.使用频率:几乎不用
d.线程生命周期:由程序员进行管理
第二种:NSThread
a.特点:
1)使用更加面向对象
2)简单易用,可直接操作线程对象
b.使用语言:OC语言
c.使用频率:偶尔使用
d.线程生命周期:由程序员进行管理
第三种:GCD
a.特点:
1)旨在替代NSThread等线程技术
2)充分利用设备的多核(自动)
b.使用语言:C语言
c.使用频率:经常使用
d.线程生命周期:自动管理
第四种:NSOperation
a.特点:
1)基于GCD(底层是GCD)
2)比GCD多了一些更简单实用的功能
3)使用更加面向对象
b.使用语言:OC语言
c.使用频率:经常使用
d.线程生命周期:自动管理
多线程的原理
同一时间,CPU只能处理1条线程,只有1条线程在工作(执行)
多线程并发(同时)执行,其实是CPU快速地在多条线程之间调度(切换)
如果CPU调度线程的时间足够快,就造成了多线程并发执行的假象
思考:如果线程非常非常多,会发生什么情况?
CPU会在N多线程之间调度,CPU会累死,消耗大量的CPU资源
每条线程被调度执行的频次会降低(线程的执行效率降低)
多线程的优点
能适当提高程序的执行效率,
能适当提高资源利用率(CPU、内存利用率)
多线程的缺点
开启线程需要占用一定的内存空间(默认情况下,主线程占用1M,子线程占用512KB),如果开启大量的线程,会占用大量的内存空间,降低程序的性能,线程越多,CPU在调度线程上的开销就越大,程序设计更加复杂:比如线程之间的通信、多线程的数据共享
你更倾向于哪一种?
倾向于GCD:
GCD
技术是一个轻量的,底层实现隐藏的神奇技术,我们能够通过GCD和block轻松实现多线程编程,有时候,GCD相比其他系统提供的多线程方法更加有效,当然,有时候GCD不是最佳选择,另一个多线程编程的技术NSOprationQueue 让我们能够将后台线程以队列方式依序执行,并提供更多操作的入口,这和 GCD 的实现有些类似。
这种类似不是一个巧合,在早期,MacOX 与 iOS 的程序都普遍采用Operation
Queue来进行编写后台线程代码,而之后出现的GCD技术大体是依照前者的原则来实现的,而随着GCD的普及,在iOS 4 与 MacOS X
10.6以后,Operation Queue的底层实现都是用GCD来实现的。
那这两者直接有什么区别呢?
1.GCD是底层的C语言构成的API,而NSOperationQueue及相关对象是Objc的对象。在GCD中,在队列中执行的是由block构成的任务,这是一个轻量级的数据结构;而Operation作为一个对象,为我们提供了更多的选择;
2.在NSOperationQueue中,我们可以随时取消已经设定要准备执行的任务(当然,已经开始的任务就无法阻止了),而GCD没法停止已经加入queue的block(其实是有的,但需要许多复杂的代码);
3.NSOperation能够方便地设置依赖关系,我们可以让一个Operation依赖于另一个Operation,这样的话尽管两个Operation处于同一个并行队列中,但前者会直到后者执行完毕后再执行;
4.我们能将KVO应用在NSOperation中,可以监听一个Operation是否完成或取消,这样子能比GCD更加有效地掌控我们执行的后台任务;
5.在NSOperation中,我们能够设置NSOperation的priority优先级,能够使同一个并行队列中的任务区分先后地执行,而在GCD中,我们只能区分不同任务队列的优先级,如果要区分block任务的优先级,也需要大量的复杂代码;
6.我们能够对NSOperation进行继承,在这之上添加成员变量与成员方法,提高整个代码的复用度,这比简单地将block任务排入执行队列更有自由度,能够在其之上添加更多自定制的功能。
总的来说,Operation queue提供了更多你在编写多线程程序时需要的功能,并隐藏了许多线程调度,线程取消与线程优先级的复杂代码,为我们提供简单的API入口。从编程原则来说,一般我们需要尽可能的使用高等级、封装完美的API,在必须时才使用底层API。但是我认为当我们的需求能够以更简单的底层代码完成的时候,简洁的GCD或许是个更好的选择,而Operation
queue 为我们提供能更多的选择。
倾向于:NSOperation
NSOperation相对于GCD:
1,NSOperation拥有更多的函数可用,具体查看api。NSOperationQueue 是在GCD基础上实现的,只不过是GCD更高一层的抽象。
2,在NSOperationQueue中,可以建立各个NSOperation之间的依赖关系。
3,NSOperationQueue支持KVO。可以监测operation是否正在执行(isExecuted)、是否结束(isFinished),是否取消(isCanceld)
4,GCD 只支持FIFO 的队列,而NSOperationQueue可以调整队列的执行顺序(通过调整权重)。NSOperationQueue可以方便的管理并发、NSOperation之间的优先级。
使用NSOperation的情况:各个操作之间有依赖关系、操作需要取消暂停、并发管理、控制操作之间优先级,限制同时能执行的线程数量.让线程在某时刻停止/继续等。
使用GCD的情况:一般的需求很简单的多线程操作,用GCD都可以了,简单高效。
从编程原则来说,一般我们需要尽可能的使用高等级、封装完美的API,在必须时才使用底层API。
当需求简单,简洁的GCD或许是个更好的选择,而Operation queue 为我们提供能更多的选择。
9.GCD执行原理?
GCD有一个底层线程池,这个池中存放的是一个个的线程。之所以称为“池”,很容易理解出这个“池”中的线程是可以重用的,当一段时间后这个线程没有被调用胡话,这个线程就会被销毁。注意:开多少条线程是由底层线程池决定的(线程建议控制再3~5条),池是系统自动来维护,不需要我们程序员来维护(看到这句话是不是很开心?)
而我们程序员需要关心的是什么呢?我们只关心的是向队列中添加任务,队列调度即可。
如果队列中存放的是同步任务,则任务出队后,底层线程池中会提供一条线程供这个任务执行,任务执行完毕后这条线程再回到线程池。这样队列中的任务反复调度,因为是同步的,所以当我们用currentThread打印的时候,就是同一条线程。
如果队列中存放的是异步的任务,(注意异步可以开线程),当任务出队后,底层线程池会提供一个线程供任务执行,因为是异步执行,队列中的任务不需等待当前任务执行完毕就可以调度下一个任务,这时底层线程池中会再次提供一个线程供第二个任务执行,执行完毕后再回到底层线程池中。
这样就对线程完成一个复用,而不需要每一个任务执行都开启新的线程,也就从而节约的系统的开销,提高了效率。在iOS7.0的时候,使用GCD系统通常只能开5~8条线程,iOS8.0以后,系统可以开启很多条线程,但是实在开发应用中,建议开启线程条数:3~5条最为合理。
通过案例明白GCD的执行原理
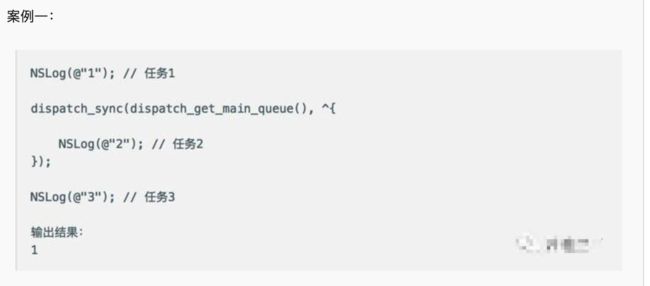 案例一.png
案例一.png
分析:
首先执行任务1,这是肯定没问题的,只是接下来,程序遇到了同步线程,那么它会进入等待,等待任务2执行完,然后执行任务3。但这是队列,有任务来,当然会将任务加到队尾,然后遵循FIFO原则执行任务。那么,现在任务2就会被加到最后,任务3排在了任务2前面,问题来了:
任务3要等任务2执行完才能执行,任务2又排在任务3后面,意味着任务2要在任务3执行完才能执行,所以他们进入了互相等待的局面。【既然这样,那干脆就卡在这里吧】这就是死锁。
 图示.png
图示.png
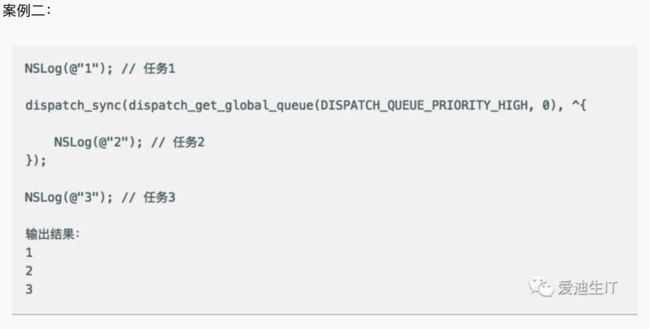 案例2.png
案例2.png
分析:
首先执行任务1,接下来会遇到一个同步线程,程序会进入等待。等待任务2执行完成以后,才能继续执行任务3。从dispatch_get_global_queue可以看出,任务2被加入到了全局的并行队列中,当并行队列执行完任务2以后,返回到主队列,继续执行任务3。
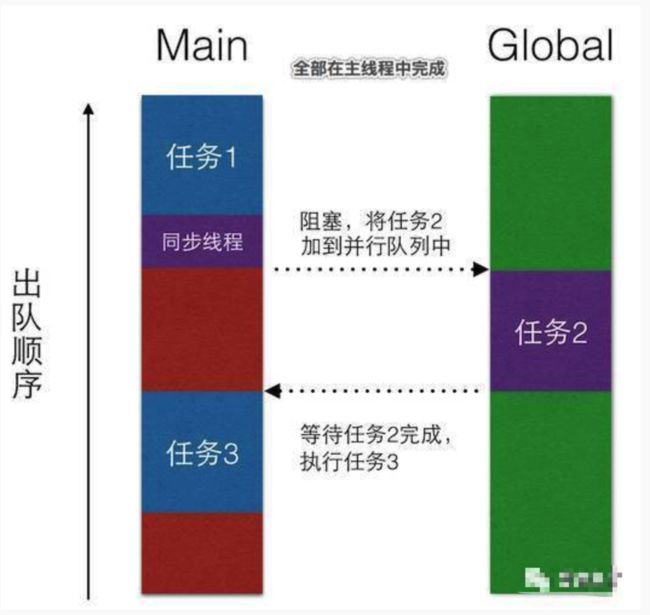 图例.png
图例.png
 案例三.png
案例三.png
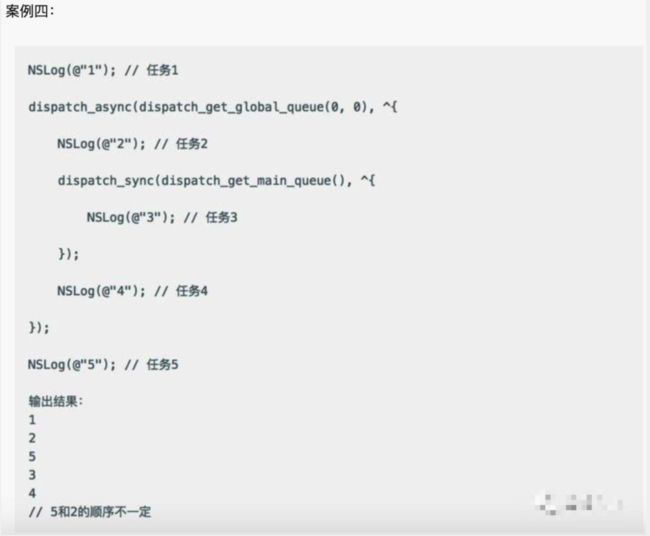 案例四.png
案例四.png
10.#import和#include的区别 @class?
@class一般用于头文件中需要声明该类的某个实例变量的时候用到,在m文 件中还是需要使用#import
而#import比起#include的好处就是不会引起交叉编译
11.readwrite,readonly,assign,retain,copy,nonatomic 属性的作用
@property是 一个属性访问声明,扩号内支持以下几个属性:
1,getter=getName,setter=setName,设置setter与 getter的方法名
2,readwrite,readonly,设置可供访问级别
2,assign,setter方法直接赋值,不进行任何retain操作,为了解决原类型与环循引用问题
3,retain,setter方法对参数进行release旧值再retain新值,所有 实现都是这个顺序(CC上有相关资料)
4,copy,setter方法进行Copy操作,与retain处理流程一样,先旧值release,再 Copy出新的对象,retainCount为1。这是为了减少对上下文的依赖而引入的机制。
5,nonatomic,非原子性访问,不加同步, 多线程并发访问会提高性能。注意,如果不加此属性,则默认是两个访问方法都为原子型事务访问。锁被加到所属对象实例级(我是这么理解的…)。
12.在一个对象的方法里面:self.name= “object”;和 name =”object” 有什么不同吗?
self.name =”object”:会调用对象的setName()方法;
name = “object”:会直接把object赋值给当前对象的name属性。
13.const char p; charconstp; charconst p; const char const p;四个修饰指针有什么区别
(1)定义了一个指向不可变的字符串的字符指针
(2)和(1)一样
(3)定义了一个指向字符串的指针,该指针值不可改变,即不可改变指向
(4)定义了一个指向不可变的字符串的字符指针,且该指针也不可改变指向
14.Objective-C如何对内存管理的,说说你的看法和解决方法?
Objective-C的内存管理主要有三种方式ARC(自动内存计数)、手动内存计数、内存池。
1). (Garbage Collection)自动内存计数:这种方式和java类似,在你的程序的执行过程中。始终有一个高人在背后准确地帮你收拾垃圾,你不用考虑它什么时候开始工作,怎样工作。你只需要明白,我申请了一段内存空间,当我不再使用从而这段内存成为垃圾的时候,我就彻底的把它忘记掉,反正那个高人会帮我收拾垃圾。遗憾的是,那个高人需要消耗一定的资源,在携带设备里面,资源是紧俏商品所以iPhone不支持这个功能。所以“Garbage Collection”不是本入门指南的范围,对“Garbage Collection”内部机制感兴趣的同学可以参考一些其他的资料,不过说老实话“Garbage Collection”不大适合适初学者研究。
解决: 通过alloc – initial方式创建的, 创建后引用计数+1, 此后每retain一次引用计数+1, 那么在程序中做相应次数的release就好了.
2). (Reference Counted)手动内存计数:就是说,从一段内存被申请之后,就存在一个变量用于保存这段内存被使用的次数,我们暂时把它称为计数器,当计数器变为0的时候,那么就是释放这段内存的时候。比如说,当在程序A里面一段内存被成功申请完成之后,那么这个计数器就从0变成1(我们把这个过程叫做alloc),然后程序B也需要使用这个内存,那么计数器就从1变成了2(我们把这个过程叫做retain)。紧接着程序A不再需要这段内存了,那么程序A就把这个计数器减1(我们把这个过程叫做release);程序B也不再需要这段内存的时候,那么也把计数器减1(这个过程还是release)。当系统(也就是Foundation)发现这个计数器变 成员了0,那么就会调用内存回收程序把这段内存回收(我们把这个过程叫做dealloc)。顺便提一句,如果没有Foundation,那么维护计数器,释放内存等等工作需要你手工来完成。
解决:一般是由类的静态方法创建的, 函数名中不会出现alloc或init字样, 如[NSString string]和[NSArray arrayWithObject:], 创建后引用计数+0, 在函数出栈后释放, 即相当于一个栈上的局部变量. 当然也可以通过retain延长对象的生存期.
3). (NSAutoRealeasePool)内存池:可以通过创建和释放内存池控制内存申请和回收的时机.
解决:是由autorelease加入系统内存池, 内存池是可以嵌套的, 每个内存池都需要有一个创建释放对, 就像main函数中写的一样. 使用也很简单, 比如[[[NSString alloc]initialWithFormat:@”Hey you!”] autorelease], 即将一个NSString对象加入到最内层的系统内存池, 当我们释放这个内存池时, 其中的对象都会被释放.
15.Runtime的消息转发机制
Runtime肯定要问的,就可以多记忆一些,你要知道的runtime都在这里
相关术语和数据结构,runtime相关的术语的数据结构
16.Runloop的工作原理
考察方向:
1、与线程和自动释放池相关:
2、CFRunLoopRef构造:数据结构;创建与退出;mode切换和item依赖;Runloop启动
- CFRunLoopModeRef:数据结构(与CFRunLoopRef放一起了);创建;类型;
modeItems:- CFRunLoopSourceRef:数据结构(source0/source1);
- source0 :
- source1 :
- CFRunLoopTimerRef:数据结构;创建与生效;相关类型(GCD的timer与CADisplayLink)
- CFRunLoopObserverRef:数据结构;创建与添加;监听的状态;
3、Runloop内部逻辑:关键在两个判断点(是否睡觉,是否退出)
- 代码实现:
- 函数作用栈显示:
4、Runloop本质:mach port和mach_msg()。
5、如何处理事件:
- 界面刷新:
- 手势识别:
- GCD任务:
- timer:(与CADisplayLink)
- 网络请求:
6、应用:
- 滑动与图片刷新;
- 常驻子线程,保持子线程一直处理事件###17.内存管理
很多文章很详细,不单拿出来做过多赘述,大家可以仔细的看看
18.Block
来源:国士无双A的
C语言内存分配,C语言内存模型图如下:
 内存模型.png
内存模型.png
从图中可以看出内存被分成了5个区,每个区存储的内容如下:
栈区(stack):存放函数的参数值、局部变量的值等,由编译器自动分配释放,通常在函数执行结束后就释放了,其操作方式类似数据结构中的栈。栈内存分配运算内置于处理器的指令集,效率很高,但是分配的内存容量有限,比如iOS中栈区的大小是2M。
堆区(heap):就是通过new、malloc、realloc分配的内存块,它们的释放编译器不去管,由我们的应用程序去释放。如果应用程序没有释放掉,操作系统会自动回收。分配方式类似于链表。
静态区:全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后,由系统释放。
常量区:常量存储在这里,不允许修改的。
代码区:存放函数体的二进制代码。
栈区在什么时候释放内存呢?我们通过下面的一个例子来说明下:
- (void)print {
int i = 10;
int j = 20;
NSLog(@"i+j = %d", (i+j));
}
在上面的代码中当程序执行到 } 的时候,变量i和j的作用域已经结束了,编译器就会自动释放掉i和j所占的内存,所以理解好作用域就理解了栈区的内存分配。
栈区和堆区的区别主要为以下几点:
对于栈来说,内存管理由编译器自动分配释放;对于堆来说,释放工作由程序员控制。
栈的空间大小比堆小许多。
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,所以分配效率比堆高。
栈中存储的变量出了作用域就无效了,而堆由于是由程序员进行控制释放的,变量的生命周期可以延长。
block
声明block属性的时候为什么用copy呢?
在说明为什么要用copy前,先思考下block是存储在栈区还是堆区呢?其实block有3种类型:
全局块(_NSConcreteGlobalBlock)
栈块(_NSConcreteStackBlock)
堆块(_NSConcreteMallocBlock)
全局块存储在静态区(也叫全局区),相当于Objective-C中的单例;栈块存储在栈区,超出作用域则马上被销毁。堆块存储在堆区中,是一个带引用计数的对象,需要自行管理其内存。
怎么判断一个block所在的存储位置呢?
block不访问外界变量(包括栈中和堆中的变量)
block既不在栈中也不在堆中,此时就为全局块,ARC和MRC下都是如此。
block访问外界变量
MRC环境下:访问外界变量的block默认存储在栈区。
ARC环境下:访问外界变量的block默认存放在堆中,实际上是先放在栈区,在ARC情况下自动又拷贝到堆区,自动释放。
使用copy修饰符的作用就是将block从栈区拷贝到堆区,为什么要这么做呢?我们看下Apple官方文档给出的答案:
通过官方文档可以看出,复制到堆区的主要目的就是保存block的状态,延长其生命周期。因为block如果在栈上的话,其所属的变量作用域结束,该block就被释放掉,block中的__block变量也同时被释放掉。为了解决栈块在其变量作用域结束之后被释放掉的问题,我们就需要把block复制到堆中。
不同类型的block使用copy方法的效果也不一样,如下所示:
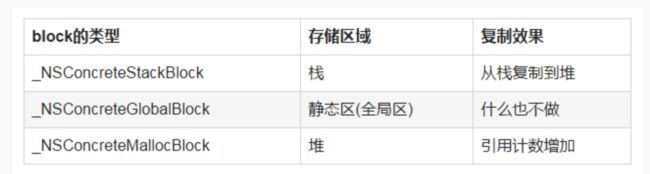
block的类型 存储区域 复制效果
_NSConcreteStackBlock 栈 从栈复制到堆
_NSConcreteGlobalBlock 静态区(全局区) 什么也不做
_NSConcreteMallocBlock 堆 引用计数增加
加上__block之后为什么就可以修改block外面的变量了?
我们先看下例子1:
- (void)testMethod {
int anInteger = 42;
void (^testBlock)(void) = ^{
NSLog(@"Integer is : %i", anInteger);
};
anInteger = 50;
testBlock();
}
19.GCD
详细介绍GCD
GCD 任务和队列
串行队列(Serial Dispatch Queue):
并发队列(Concurrent Dispatch Queue):
GCD 的使用步骤
GCD 的使用步骤其实很简单,只有两步。
创建一个队列(串行队列或并发队列)
将任务追加到任务的等待队列中,然后系统就会根据任务类型执行任务(同步执行或异步执行)
虽然使用 GCD 只需两步,但是既然我们有两种队列(串行队列/并发队列),两种任务执行方式(同步执行/异步执行),那么我们就有了四种不同的组合方式。这四种不同的组合方式是:
1.同步执行 + 并发队列
2.异步执行 + 并发队列
3.同步执行 + 串行队列
4.异步执行 + 串行队列
实际上,刚才还说了两种特殊队列:全局并发队列、主队列。全局并发队列可以作为普通并发队列来使用。但是主队列因为有点特殊,所以我们就又多了两种组合方式。这样就有六种不同的组合方式了。
5.同步执行 + 主队列
6.异步执行 + 主队列
其他方法:
GCD 延时执行方法:dispatch_after
GCD 栅栏方法:dispatch_barrier_async
GCD 一次性代码(只执行一次):dispatch_once
CGD 快速迭代方法:dispatch_apply
GCD 的队列组:dispatch_group
dispatch_group_notify
dispatch_group_wait
GCD 信号量:dispatch_semaphore
Dispatch Semaphore 线程同步
非线程安全(不使用 semaphore)
线程安全(使用 semaphore 加锁)
20.Struct与Union主要区别
Struct 和 Union有下列区别:
1.在存储多个成员信息时,编译器会自动给struct第个成员分配存储空间,struct 可以存储多个成员信息,而Union每个成员会用同一个存储空间,只能存储最后一个成员的信息。
2.都是由多个不同的数据类型成员组成,但在任何同一时刻,Union只存放了一个被先选中的成员,而结构体的所有成员都存在。
3.对于Union的不同成员赋值,将会对其他成员重写,原来成员的值就不存在了,而对于struct 的不同成员赋值 是互不影响的。
注:在很多地方需要对结构体的成员变量进行修改。只是部分成员变量,那么就不能用联合体Union,因为Union的所有成员变量占一个内存。eg:在链表中对个别数值域进行赋值就必须用struct.
代码和例子
21.KVO、delegate、通知的区别以及底层实现
KVO在Apple中的API文档如下:
Automatic key-value observing is implemented using a technique called isa-swizzling… When an observer is registered for an attribute of an object the isa pointer of the observed object is modified, pointing to an intermediate class rather than at the true class …
KVO基本原理:
1.KVO是基于runtime机制实现的
2.当某个类的属性对象第一次被观察时,系统就会在运行期动态地创建该类的一个派生类,在这个派生类中重写基类中任何被观察属性的setter 方法。派生类在被重写的setter方法内实现真正的通知机制
3.如果原类为Person,那么生成的派生类名为NSKVONotifying_Person
4.每个类对象中都有一个isa指针指向当前类,当一个类对象的第一次被观察,那么系统会偷偷将isa指针指向动态生成的派生类,从而在给被监控属性赋值时执行的是派生类的setter方法
5.键值观察通知依赖于NSObject 的两个方法: willChangeValueForKey: 和 didChangevlueForKey:;在一个被观察属性发生改变之前, willChangeValueForKey:一定会被调用,这就 会记录旧的值。而当改变发生后,didChangeValueForKey:会被调用,继而 observeValueForKey:ofObject:change:context: 也会被调用。
KVO深入原理:
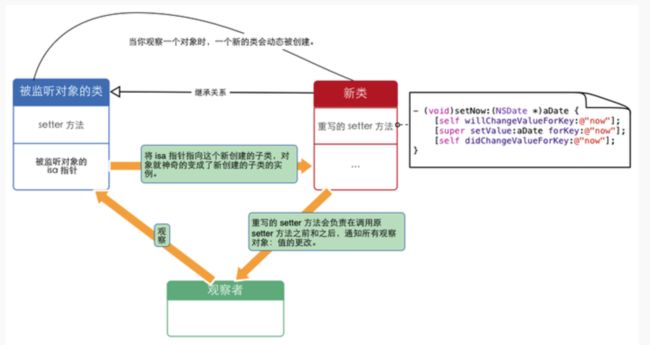
1.Apple 使用了 isa 混写(isa-swizzling)来实现 KVO 。当观察对象A时,KVO机制动态创建一个新的名为:?NSKVONotifying_A的新类,该类继承自对象A的本类,且KVO为NSKVONotifying_A重写观察属性的setter?方法,setter?方法会负责在调用原?setter?方法之前和之后,通知所有观察对象属性值的更改情况。
2.NSKVONotifying_A类剖析:在这个过程,被观察对象的 isa 指针从指向原来的A类,被KVO机制修改为指向系统新创建的子类 NSKVONotifying_A类,来实现当前类属性值改变的监听;
3.所以当我们从应用层面上看来,完全没有意识到有新的类出现,这是系统“隐瞒”了对KVO的底层实现过程,让我们误以为还是原来的类。但是此时如果我们创建一个新的名为“NSKVONotifying_A”的类(),就会发现系统运行到注册KVO的那段代码时程序就崩溃,因为系统在注册监听的时候动态创建了名为NSKVONotifying_A的中间类,并指向这个中间类了。
4.(isa 指针的作用:每个对象都有isa 指针,指向该对象的类,它告诉 Runtime 系统这个对象的类是什么。所以对象注册为观察者时,isa指针指向新子类,那么这个被观察的对象就神奇地变成新子类的对象(或实例)了。)?因而在该对象上对 setter 的调用就会调用已重写的 setter,从而激活键值通知机制。
5.子类setter方法剖析:KVO的键值观察通知依赖于 NSObject 的两个方法:willChangeValueForKey:和 didChangevlueForKey:,在存取数值的前后分别调用2个方法: 被观察属性发生改变之前,willChangeValueForKey:被调用,通知系统该 keyPath?的属性值即将变更;当改变发生后, didChangeValueForKey: 被调用,通知系统该 keyPath?的属性值已经变更;之后,?observeValueForKey:ofObject:change:context: 也会被调用。且重写观察属性的setter?方法这种继承方式的注入是在运行时而不是编译时实现的。
 原理.png
原理.png
22.写一段程序判断文本框内输入的IP地址是否合法
23.编译器怎么检测#import和#include导入多次的问题,三方库导入时如何设置""和<>
24.TCP/IP 5层结构都知道吗?每一层的职能呢?
1)应用层
负责应用间通讯,包含了很多协议,比如HTTP、HTTPS、SIP之类的。
2)传输层
传输层包含协议常考的有两个,TCP和UDP。为上一层提供的是端到端的数据传输(因为要端口号了哦亲)。TCP连接时的3次握手和断开时的4次挥手需要理解。UDP的话属于不太负责任的那种,不保证完整收货的。
3)网络层
这层主要就是做路由的。什么概念呢,我这个包从我这来要到哪去,怎么找路都是这层负责的。不同传输速率的路由器使用的算法不一致。这层可以理解是主机到主机之间的通信。
4)数据链路层
数据链路层主要管的是包在信道上发送时的一些问题,比如物理地址寻址、数据的成帧、流量控制、数据的检错、重发等等。
5)物理层
这层主要是做信号转换的。怎么把01字节转为电信号。算法有很多,速率不同算法也不一样。
25.说说你理解的埋点?
以下几篇文章写的相当不错,可以适当借鉴下!
iOS无埋点数据SDK实践之路
iOS无埋点数据SDK的整体设计与技术实现
iOS无埋点SDK 之 RN页面的数据收集
26.项目中网络层如何做安全处理?
1、尽量使用https
https可以过滤掉大部分的安全问题。https在证书申请,服务器配置,性能优化,客户端配置上都需要投入精力,所以缺乏安全意识的开发人员容易跳过https,或者拖到以后遇到问题再优化。https除了性能优化麻烦一些以外其他都比想象中的简单,如果没精力优化性能,至少在注册登录模块需要启用https,这部分业务对性能要求比较低。
2、不要传输明文密码
不知道现在还有多少app后台是明文存储密码的。无论客户端,server还是网络传输都要避免明文密码,要使用hash值。客户端不要做任何密码相关的存储,hash值也不行。存储token进行下一次的认证,而且token需要设置有效期,使用refresh token去申请新的token。
3、Post并不比Get安全
事实上,Post和Get一样不安全,都是明文。参数放在QueryString或者Body没任何安全上的差别。在Http的环境下,使用Post或者Get都需要做加密和签名处理。
4、不要使用301跳转
301跳转很容易被Http劫持攻击。移动端http使用301比桌面端更危险,用户看不到浏览器地址,无法察觉到被重定向到了其他地址。如果一定要使用,确保跳转发生在https的环境下,而且https做了证书绑定校验。
5、http请求都带上MAC
所有客户端发出的请求,无论是查询还是写操作,都带上MAC(Message Authentication
Code)。MAC不但能保证请求没有被篡改(Integrity),还能保证请求确实来自你的合法客户端(Signing)。当然前提是你客户端的key没有被泄漏,如何保证客户端key的安全是另一个话题。MAC值的计算可以简单的处理为hash(request
params+key)。带上MAC之后,服务器就可以过滤掉绝大部分的非法请求。MAC虽然带有签名的功能,和RSA证书的电子签名方式却不一样,原因是MAC签名和签名验证使用的是同一个key,而RSA是使用私钥签名,公钥验证,MAC的签名并不具备法律效应。
6、http请求使用临时密钥
高延迟的网络环境下,不经优化https的体验确实会明显不如http。在不具备https条件或对网络性能要求较高且缺乏https优化经验的场景下,http的流量也应该使用AES进行加密。AES的密钥可以由客户端来临时生成,不过这个临时的AES
key需要使用服务器的公钥进行加密,确保只有自己的服务器才能解开这个请求的信息,当然服务器的response也需要使用同样的AES
key进行加密。由于http的应用场景都是由客户端发起,服务器响应,所以这种由客户端单方生成密钥的方式可以一定程度上便捷的保证通信安全。
7、AES使用CBC模式
不要使用ECB模式,记得设置初始化向量,每个block加密之前要和上个block的秘文进行运算。
27.main()之前的过程有哪些?
1)dyld 开始将程序二进制文件初始化
2)交由ImageLoader 读取 image,其中包含了我们的类,方法等各种符号(Class、Protocol 、Selector、 IMP)
3)由于runtime 向dyld 绑定了回调,当image加载到内存后,dyld会通知runtime进行处理
4)runtime 接手后调用map_images做解析和处理
5)接下来load_images 中调用call_load_methods方法,遍历所有加载进来的Class,按继承层次依次调用Class的+load和其他Category的+load方法
6)至此 所有的信息都被加载到内存中
7)最后dyld调用真正的main函数
注意:dyld会缓存上一次把信息加载内存的缓存,所以第二次比第一次启动快一点
28.说说你理解weak属性?
weak实现原理:
Runtime维护了一个weak表,用于存储指向某个对象的所有weak指针。weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址(这个地址的值是所指对象的地址)数组。
1、初始化时:runtime会调用objc_initWeak函数,初始化一个新的weak指针指向对象的地址。
2、添加引用时:objc_initWeak函数会调用 objc_storeWeak() 函数, objc_storeWeak() 的作用是更新指针指向,创建对应的弱引用表。
3、释放时,调用clearDeallocating函数。clearDeallocating函数首先根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,最后清理对象的记录。
追问的问题一:1.实现weak后,为什么对象释放后会自动为nil?
追问的问题二:2.当weak引用指向的对象被释放时,又是如何去处理weak指针的呢?
1、调用objc_release
2、因为对象的引用计数为0,所以执行dealloc
3、在dealloc中,调用了_objc_rootDealloc函数
4、在_objc_rootDealloc中,调用了object_dispose函数
5、调用objc_destructInstance
6、最后调用objc_clear_deallocating,详细过程如下:
a. 从weak表中获取废弃对象的地址为键值的记录
b. 将包含在记录中的所有附有 weak修饰符变量的地址,赋值为 nil
c. 将weak表中该记录删除
d. 从引用计数表中删除废弃对象的地址为键值的记录
29.@property定义的变量,默认的修饰符是什么?
30.抓包工具原理和使用
常用的抓包工具
RawCap
可以转到本地回环(127.0.0.1)的数据
抓取所有协议的包
Fiddler
HTTP或者HTTPS 协议抓包
可以过滤,抓取特定特征的包
可以拦截数据包,篡改数据包
Wireshark
抓取所有的数据包,但不可抓回环的数据包
可以过滤,抓取特定特征的包
可以拦截数据包,篡改数据包
可做流量分析,流量统计工具
31.写二叉树的先序遍历,然后用非递归写
32.数组和链表的区别
数组静态分配内存,链表动态分配内存;
数组在内存中连续,链表不连续;
数组元素在栈区,链表元素在堆区;
数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n);
数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)。
33.堆区和栈区
程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)― 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) ― 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)―,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 ―常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区―存放函数体的二进制代码。
34. lldb(gdb)常用的调试命令?
breakpoint 设置断点定位到某一个函数
n 断点指针下一步
po打印对象
更多 lldb(gdb) 调试命令可查看:
1.The LLDB Debugger ;
2.苹果官方文档: iOS Debugging Magic 。
35.使用block时什么情况会发生引用循环,如何解决?
36.在block内如何修改block外部变量?
默认情况下,在block中访问的外部变量是复制过去的,即:写操作不对原变量生效。但是你可以加上 __block 来让其写操作生效,示例代码如下:
__block int a = 0;
void (^foo)(void) = ^{
a = 1;
};
foo();
//这里,a的值被修改为1
这是 微博@唐巧_boy的《iOS开发进阶》中的第11.2.3章节中的描述。你同样可以在面试中这样回答,但你并没有答到“点子上”。真正的原因,并没有书这本书里写的这么“神奇”,而且这种说法也有点牵强。面试官肯定会追问“为什么写操作就生效了?”真正的原因是这样的:
我们都知道:Block不允许修改外部变量的值,这里所说的外部变量的值,指的是栈中指针的内存地址。__block所起到的作用就是只要观察到该变量被 block 所持有,就将“外部变量”在栈中的内存地址放到了堆中。进而在block内部也可以修改外部变量的值。
Block不允许修改外部变量的值**。Apple这样设计,应该是考虑到了block的特殊性,block也属于“函数”的范畴,变量进入block,实际就是已经改变了作用域。在几个作用域之间进行切换时,如果不加上这样的限制,变量的可维护性将大大降低。又比如我想在block内声明了一个与外部同名的变量,此时是允许呢还是不允许呢?只有加上了这样的限制,这样的情景才能实现。于是栈区变成了红灯区,堆区变成了绿灯区。
我们可以打印下内存地址来进行验证:
__block int a = 0;
NSLog(@"定义前:%p", &a); //栈区
void (^foo)(void) = ^{
a = 1;
NSLog(@"block内部:%p", &a); //堆区
};
NSLog(@"定义后:%p", &a); //堆区
foo();
2016-05-17 02:03:33.559 LeanCloudChatKit-iOS[1505:713679] 定义前:0x16fda86f8
2016-05-17 02:03:33.559 LeanCloudChatKit-iOS[1505:713679] 定义后:0x155b22fc8
2016-05-17 02:03:33.559 LeanCloudChatKit-iOS[1505:713679] block内部: 0x155b22fc8
“定义后”和“block内部”两者的内存地址是一样的,我们都知道 block 内部的变量会被 copy 到堆区,“block内部”打印的是堆地址,因而也就可以知道,“定义后”打印的也是堆的地址。
那么如何证明“block内部”打印的是堆地址?
把三个16进制的内存地址转成10进制就是:
定义后前:6171559672
block内部:5732708296
定义后后:5732708296
中间相差438851376个字节,也就是 418.5M 的空间,因为堆地址要小于栈地址,又因为iOS中一个进程的栈区内存只有1M,Mac也只有8M,显然a已经是在堆区了。
这也证实了:a 在定义前是栈区,但只要进入了 block 区域,就变成了堆区。这才是 __block 关键字的真正作用。
__block 关键字修饰后,int类型也从4字节变成了32字节,这是 Foundation 框架 malloc 出来的。这也同样能证实上面的结论。(PS:居然比 NSObject alloc 出来的 16 字节要多一倍)。
理解到这是因为堆栈地址的变更,而非所谓的“写操作生效”,这一点至关重要,要不然你如何解释下面这个现象:
以下代码编译可以通过,并且在block中成功将a的从Tom修改为Jerry。
NSMutableString *a = [NSMutableString stringWithString:@"Tom"];
NSLog(@"\n 定以前:------------------------------------\n\
a指向的堆中地址:%p;a在栈中的指针地址:%p", a, &a); //a在栈区
void (^foo)(void) = ^{
a.string = @"Jerry";
NSLog(@"\n block内部:------------------------------------\n\
a指向的堆中地址:%p;a在栈中的指针地址:%p", a, &a);
//a在栈区
a = [NSMutableString stringWithString:@"William"];
};
foo();
NSLog(@"\n 定以后:------------------------------------\n\
a指向的堆中地址:%p;a在栈中的指针地址:%p", a, &a);
//a在栈区
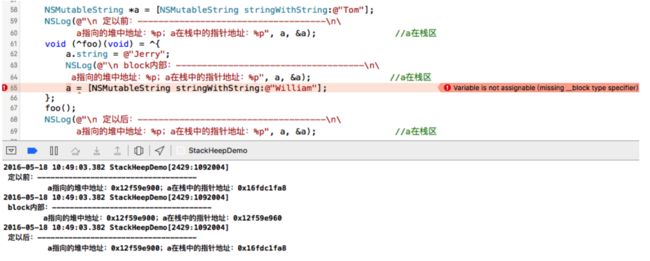
这里的a已经由基本数据类型,变成了对象类型。block会对对象类型的指针进行copy,copy到堆中,但并不会改变该指针所指向的堆中的地址,所以在上面的示例代码中,block体内修改的实际是a指向的堆中的内容。
但如果我们尝试像上面图片中的65行那样做,结果会编译不通过,那是因为此时你在修改的就不是堆中的内容,而是栈中的内容。
上文已经说过:Block不允许修改外部变量的值,这里所说的外部变量的值,指的是栈中指针的内存地址。栈区是红灯区,堆区才是绿灯区。
37.APP启动的完整过程
Mach-O
哪些名词指的是Mach-o
Executable 可执行文件
Dylib 动态库
Bundle 无法被连接的动态库,只能通过dlopen()加载
Image 指的是Executable,Dylib或者Bundle的一种,文中会多次使用Image这个名词。
Framework 动态库和对应的头文件和资源文件的集合
Apple出品的操作系统的可执行文件格式几乎都是mach-o,iOS当然也不例外。
mach-o可以大致的分为三部分:
 图示.png
图示.png
Header 头部,包含可以执行的CPU架构,比如x86,arm64
Load commands 加载命令,包含文件的组织架构和在虚拟内存中的布局方式
Data,数据,包含load commands中需要的各个段(segment)的数据,每一个Segment都得大小是Page的整数倍。
我们用MachOView打开Demo工程的可以执行文件,来验证下mach-o的文件布局:
 图示.png
图示.png
图中分析的mach-o文件来源于 PullToRefreshKit,这是一个纯Swift的编写的工程。
那么Data部分又包含哪些segment呢?绝大多数mach-o包括以下三个段(支持用户自定义Segment,但是很少使用)
__TEXT 代码段,只读,包括函数,和只读的字符串,上图中类似__TEXT,__text的都是代码段
__DATA 数据段,读写,包括可读写的全局变量等,上图类似中的__DATA,__data都是数据段
__LINKEDIT__LINKEDIT包含了方法和变量的元数据(位置,偏移量),以及代码签名等信息。
关于mach-o更多细节,可以看看文档:《 Mac OS X ABI Mach-O File Format Reference》。
dyld
dyld的全称是dynamic loader,它的作用是加载一个进程所需要的image,dyld是开源的。
Virtual Memory
虚拟内存是在物理内存上建立的一个逻辑地址空间,它向上(应用)提供了一个连续的逻辑地址空间,向下隐藏了物理内存的细节。
虚拟内存使得逻辑地址可以没有实际的物理地址,也可以让多个逻辑地址对应到一个物理地址。
虚拟内存被划分为一个个大小相同的Page(64位系统上是16KB),提高管理和读写的效率。 Page又分为只读和读写的Page。
虚拟内存是建立在物理内存和进程之间的中间层。在iOS上,当内存不足的时候,会尝试释放那些只读的Page,因为只读的Page在下次被访问的时候,可以再从磁盘读取。如果没有可用内存,会通知在后台的App(也就是在这个时候收到了memory warning),如果在这之后仍然没有可用内存,则会杀死在后台的App。
Page fault
在应用执行的时候,它被分配的逻辑地址空间都是可以访问的,当应用访问一个逻辑Page,而在对应的物理内存中并不存在的时候,这时候就发生了一次Page fault。当Page fault发生的时候,会中断当前的程序,在物理内存中寻找一个可用的Page,然后从磁盘中读取数据到物理内存,接着继续执行当前程序。
Dirty Page & Clean Page
- 如果一个Page可以从磁盘上重新生成,那么这个Page称为Clean Page
- 如果一个Page包含了进程相关信息,那么这个Page称为Dirty Page
像代码段这种只读的Page就是Clean Page。而像数据段(_DATA)这种读写的Page,当写数据发生的时候,会触发COW(Copy on write),也就是写时复制,Page会被标记成Dirty,同时会被复制。
想要了解更多细节,可以阅读文档:Memory Usage Performance Guidelines
启动过程
使用dyld2启动应用的过程如图:

大致的过程如下:
加载dyld到App进程
加载动态库(包括所依赖的所有动态库)
Rebase
Bind
初始化Objective C Runtime
其它的初始化代码
加载动态库
dyld会首先读取mach-o文件的Header和load commands。
接着就知道了这个可执行文件依赖的动态库。例如加载动态库A到内存,接着检查A所依赖的动态库,就这样的递归加载,直到所有的动态库加载完毕。通常一个App所依赖的动态库在100-400个左右,其中大多数都是系统的动态库,它们会被缓存到dyld shared cache,这样读取的效率会很高。
查看mach-o文件所依赖的动态库,可以通过MachOView的图形化界面(展开Load Command就能看到),也可以通过命令行otool。
192:Desktop Leo$ otool -L demo
demo:
@rpath/PullToRefreshKit.framework/PullToRefreshKit (compatibility version 1.0.0, current version 1.0.0)
/System/Library/Frameworks/Foundation.framework/Foundation (compatibility version 300.0.0, current version 1444.12.0)
/usr/lib/libobjc.A.dylib (compatibility version 1.0.0, current version 228.0.0)
@rpath/libswiftCore.dylib (compatibility version 1.0.0, current version 900.0.65)
@rpath/libswiftCoreAudio.dylib (compatibility version 1.0.0, current version 900.0.65)
//...
Rebase && Bind
这里先来讲讲为什么要Rebase?
有两种主要的技术来保证应用的安全:ASLR和Code Sign。
ASLR的全称是Address space layout randomization,翻译过来就是“地址空间布局随机化”。App被启动的时候,程序会被影射到逻辑的地址空间,这个逻辑的地址空间有一个起始地址,而ASLR技术使得这个起始地址是随机的。如果是固定的,那么黑客很容易就可以由起始地址+偏移量找到函数的地址。
Code Sign相信大多数开发者都知晓,这里要提一点的是,在进行Code sign的时候,加密哈希不是针对于整个文件,而是针对于每一个Page的。这就保证了在dyld进行加载的时候,可以对每一个page进行独立的验证。
mach-o中有很多符号,有指向当前mach-o的,也有指向其他dylib的,比如printf。那么,在运行时,代码如何准确的找到printf的地址呢?
mach-o中采用了PIC技术,全称是Position Independ code。当你的程序要调用printf的时候,会先在__DATA段中建立一个指针指向printf,在通过这个指针实现间接调用。dyld这时候需要做一些fix-up工作,即帮助应用程序找到这些符号的实际地址。主要包括两部分
- Rebase 修正内部(指向当前mach-o文件)的指针指向
- Bind 修正外部指针指向
 图示.png
图示.png
之所以需要Rebase,是因为刚刚提到的ASLR使得地址随机化,导致起始地址不固定,另外由于Code Sign,导致不能直接修改Image。Rebase的时候只需要增加对应的偏移量即可。待Rebase的数据都存放在__LINKEDIT中。
可以通过MachOView查看:Dynamic Loader Info -> Rebase Info
也可以通过命令行:
192:Desktop Leo$ xcrun dyldinfo -bind demo
bind information:
segment section address type addend dylib symbol
__DATA __got 0x10003C038 pointer 0 PullToRefreshKit __T016PullToRefreshKit07DefaultC4LeftC9textLabelSo7UILabelCvWvd
__DATA __got 0x10003C040 pointer 0 PullToRefreshKit __T016PullToRefreshKit07DefaultC5RightC9textLabelSo7UILabelCvWvd
__DATA __got 0x10003C048 pointer 0 PullToRefreshKit __T016PullToRefreshKit07DefaultC6FooterC9textLabelSo7UILabelCvWvd
__DATA __got 0x10003C050 pointer 0 PullToRefreshKit __T016PullToRefreshKit07DefaultC6HeaderC7spinnerSo23UIActivityIndicatorViewCvWvd
//...
Rebase解决了内部的符号引用问题,而外部的符号引用则是由Bind解决。在解决Bind的时候,是根据字符串匹配的方式查找符号表,所以这个过程相对于Rebase来说是略慢的。
同样,也可以通过xcrun dyldinfo来查看Bind的信息,比如我们查看bind信息中,包含UITableView的部分:
192:Desktop Leo$ xcrun dyldinfo -bind demo | grep UITableView
__DATA __objc_classrefs 0x100041940 pointer 0 UIKit _OBJC_CLASS_$_UITableView
__DATA __objc_classrefs 0x1000418B0 pointer 0 UIKit _OBJC_CLASS_$_UITableViewCell
__DATA __objc_data 0x100041AC0 pointer 0 UIKit _OBJC_CLASS_$_UITableViewController
__DATA __objc_data 0x100041BE8 pointer 0 UIKit _OBJC_CLASS_$_UITableViewController
__DATA __objc_data 0x100042348 pointer 0 UIKit _OBJC_CLASS_$_UITableViewController
__DATA __objc_data 0x100042718 pointer 0 UIKit _OBJC_CLASS_$_UITableViewController
__DATA __data 0x100042998 pointer 0 UIKit _OBJC_METACLASS_$_UITableViewController
__DATA __data 0x100042A28 pointer 0 UIKit _OBJC_METACLASS_$_UITableViewController
__DATA __data 0x100042F10 pointer 0 UIKit _OBJC_METACLASS_$_UITableViewController
__DATA __data 0x1000431A8 pointer 0 UIKit _OBJC_METACLASS_$_UITableViewController
Objective C
Objective C是动态语言,所以在执行main函数之前,需要把类的信息注册到一个全局的Table中。同时,Objective C支持Category,在初始化的时候,也会把Category中的方法注册到对应的类中,同时会唯一Selector,这也是为什么当你的Cagegory实现了类中同名的方法后,类中的方法会被覆盖。
另外,由于iOS开发时基于Cocoa Touch的,所以绝大多数的类起始都是系统类,所以大多数的Runtime初始化起始在Rebase和Bind中已经完成。
Initializers
接下来就是必要的初始化部分了,主要包括几部分:
- +load方法。
- C/C++静态初始化对象和标记为
__attribute__(constructor)的方法
这里要提一点的就是,+load方法已经被弃用了,如果你用Swift开发,你会发现根本无法去写这样一个方法,官方的建议是实用initialize。区别就是,load是在类装载的时候执行,而initialize是在类第一次收到message前调用。
dyld3
上文的讲解是dyld2的加载方式。而最新的是dyld3加载方式略有不同:
dyld2是纯粹的in-process,也就是在程序进程内执行的,也就意味着只有当应用程序被启动的时候,dyld2才能开始执行任务。
dyld3则是部分out-of-process,部分in-process。图中,虚线之上的部分是out-of-process的,在App下载安装和版本更新的时候会去执行,out-of-process会做如下事情:
- 分析Mach-o Headers
- 分析依赖的动态库
- 查找需要Rebase & Bind之类的符号
- 把上述结果写入缓存
这样,在应用启动的时候,就可以直接从缓存中读取数据,加快加载速度。
启动时间
冷启动 VS 热启动
如果你刚刚启动过App,这时候App的启动所需要的数据仍然在缓存中,再次启动的时候称为热启动。如果设备刚刚重启,然后启动App,这时候称为冷启动。
启动时间在小于400ms是最佳的,因为从点击图标到显示Launch Screen,到Launch Screen消失这段时间是400ms。启动时间不可以大于20s,否则会被系统杀掉。
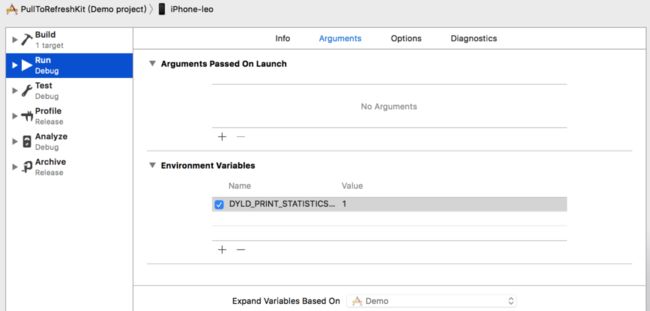
在Xcode中,可以通过设置环境变量来查看App的启动时间,DYLD_PRINT_STATISTICS和DYLD_PRINT_STATISTICS_DETAILS。
38.请在1000万个整型数据中以最快的速度找出其中最大的1000个数?
39.一个有序循的整形环链表断开了,请插入一个整形数,使得链表仍然是有序的。
40.OSI,TCP/IP,五层协议的体系结构,以及各层协议
OSI分层 (7层):物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
TCP/IP分层(4层):网络接口层、 网际层、运输层、 应用层。
五层协议 (5层):物理层、数据链路层、网络层、运输层、 应用层。
每一层的协议如下:
物理层:RJ45、CLOCK、IEEE802.3 (中继器,集线器)
数据链路:PPP、FR、HDLC、VLAN、MAC (网桥,交换机)
网络层:IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP、 (路由器)
传输层:TCP、UDP、SPX
会话层:NFS、SQL、NETBIOS、RPC
表示层:JPEG、MPEG、ASII
应用层:FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS
每一层的作用如下:
物理层:通过媒介传输比特,确定机械及电气规范(比特Bit)
数据链路层:将比特组装成帧和点到点的传递(帧Frame)
网络层:负责数据包从源到宿的传递和网际互连(包PackeT)
传输层:提供端到端的可靠报文传递和错误恢复(段Segment)
会话层:建立、管理和终止会话(会话协议数据单元SPDU)
表示层:对数据进行翻译、加密和压缩(表示协议数据单元PPDU)
应用层:允许访问OSI环境的手段(应用协议数据单元APDU)
41.IP地址的分类
A类地址:以0开头, 第一个字节范围:1~126(1.0.0.0 - 126.255.255.255);
B类地址:以10开头, 第一个字节范围:128~191(128.0.0.0 - 191.255.255.255);
C类地址:以110开头, 第一个字节范围:192~223(192.0.0.0 - 223.255.255.255);
D类地址:以1110开头,第一个字节范围:224~239(224.0.0.0 - 239.255.255.255);(作为多播使用)
E类地址:保留
其中A、B、C是基本类,D、E类作为多播和保留使用。
以下是留用的内部私有地址:
A类 10.0.0.0--10.255.255.255
B类 172.16.0.0--172.31.255.255
C类 192.168.0.0--192.168.255.255
IP地址与子网掩码相与得到网络号:
ip : 192.168.2.110
&
Submask : 255.255.255.0
网络号 :192.168.2 .0
注:
主机号,全为0的是网络号(例如:192.168.2.0),主机号全为1的为广播地址(192.168.2.255)
感谢各大平台的博客作者,面试题编辑者。
面试题地址0
面试题地址1
面试题地址1
面试题地址2
面试题地址3
面试题地址4