opencv2.4提出了一个新的关于人脸识别的类FaceRecognizer,可以用它进行人脸识别实验。当前主要的算法有Eigenfaces ,Fisherfaces ,Local Binary Patterns Histograms。
人脸识别
人脸识别对于人来说很简单,出生三天的baby就可以分辨出周围的人脸了。那么计算机是怎么做到的呢?其实我们对于人怎么识别出人脸都知之甚少,是根据内部特征(眼睛,鼻子,嘴巴)还是外部特征(头型,发际线)?我们怎么分析一张图片,大脑怎么编码它?经证实,我们的大脑根据不同的局部特征(线,边缘,角度)有不同的神经细胞分析。显然我们没有把世界看成零散的块块,我们的视觉皮层必须以某种方式把不同的信息来源转化成有用的模式。自动人脸识别就是从图片中抽取这些有意义的特征,然后用某种方式来形成分类。
基于几何特征的人脸识别可能是最直观的识别方式了。起初的一种识别方式这样表述:标记一些点(眼睛,耳朵,鼻子的位置),构建出特征向量(点之间的距离和角度),然后计算训练图片的特征向量的欧氏距离来进行识别。这种方法对于光照变化具有鲁棒性,但有个巨大的缺陷:即使是目前比较先进的算法,标记点的确定也是很复杂的,而且,也有论文表示,仅仅是几何特征可能没有涵盖足够的识别信息。
Eigenfaces方法描述了一个全面的方法来识别人脸:一个脸部图像由高维图像空间表示成低维的一个点表示,从而让分类变得简单。低维子空间由主成分分析PCA得到,这种变化对于标准点的重构是最优的,但没有分类标记。那么如果当变化仅由外部因素产生,比如光照,那么这样的降维方法是不可能拿来分类的。因此,提出线性判别分析来进行识别。
还有局部特征抽取的方法。为了避免图像局部区域输入数据的高维度,抽取的特征需要对遮挡,光照,小样本有更好的鲁棒性。用于局部特征抽取的算法有比如gabor小波,离散余弦变换和局部二值特征LBP,至于到底哪种才是表示空间信息的局部特征抽取的最佳方式,仍是个开放性的研究。
人脸数据库
你可以创建自己的数据库或者几个网上可用的数据库。
- AT&T Facedatabase也叫ORL数据库,40个人不同的10张照片,基于不同的时间,光照变化,面部表情(眼睛闭到没,笑没笑),面部细节(带没带眼镜儿)。所有图片都是在黑暗的背景下拍摄的直立的正脸。
*Yale Facedatabase A也叫Yalefaces。ORL数据库比较适合初始的测试,是一个相当简易的数据库,Eigenfaces方法就已经有大概97%的识别率了,所以对于其他方法,你也看不到有长进了。Yale就对此很友好了,因为识别问题更加复杂。
*Extended Yale Facedatabase B这个数据库有点大哟,不适合初学者,而且这个数据库重点是考察抽取的特征是否对光照有鲁棒性,图片之间几乎没什么变化。初学者,还是建议用ORL。
准备数据
得到数据之后,需要把它读到程序里面来,这里用的是CSV文件格式,基本上所有的CSV文件都需要包括文件名和分类标记,像这样:/path/to/image.ext;0
/path/to/image.ext是图片的路径,Windows系统就是C:/faces/person0/image0.jpg,然后分号隔开,用整数0标记图片,表示所属的类别。
下载ORL,CSV文件格式如下:
./at/s1/1.pgm;0
./at/s1/2.pgm;0
...
./at/s2/1.pgm;1
./at/s2/2.pgm;1
...
./at/s40/1.pgm;39
./at/s40/2.pgm;39
假设数据存在D:/data/at,CSV文件存在D:/data/at.txt. 你需要把./替换成D:/data/.成功建立好CSV后,可以试着运行它:
facerec_demo.exe D:/data/at.txt
创建CSV
用不着手动输入产生CSV文件,官方源码有python的脚本自动生成,在..\opencv_contrib-master\modules\face\samples\etc\create_csv.py,这里贴出来。
#!/usr/bin/env python
import sys
import os.path
# This is a tiny script to help you creating a CSV file from a face
# database with a similar hierarchie:
#
# philipp@mango:~/facerec/data/at$ tree
# .
# |-- README
# |-- s1
# | |-- 1.pgm
# | |-- ...
# | |-- 10.pgm
# |-- s2
# | |-- 1.pgm
# | |-- ...
# | |-- 10.pgm
# ...
# |-- s40
# | |-- 1.pgm
# | |-- ...
# | |-- 10.pgm
#
if __name__ == "__main__":
if len(sys.argv) != 2:
print("usage: create_csv ")
sys.exit(1)
BASE_PATH=sys.argv[1]
SEPARATOR=";"
label = 0
for dirname, dirnames, filenames in os.walk(BASE_PATH):
for subdirname in dirnames:
subject_path = os.path.join(dirname, subdirname)
for filename in os.listdir(subject_path):
abs_path = "%s/%s" % (subject_path, filename)
print("%s%s%d" % (abs_path, SEPARATOR, label))
label = label + 1
看到没,你的文件目录格式要像代码注释里那样才行,然后调用create_csv.py at,at就是你存放图片的根目录。
Eigenfaces
输入图片表示方式的问题在于它的高维度,pq大小的二维灰度图片跨域了m=pq维的向量空间,因此一个100*100像素的图片就已经有10000维的空间了。那么,所有维度都同样有用吗?我们可以这样,如果数据有任何偏差,就寻找涵盖大部分信息的成分。哈哈哈,那就是PCA勒!把一系列可能相关的变量转换成低维的不相关变量。也就是说,高维数据经常用相关变量来描述,而大部分信息被其中部分有意义的变量包括。PCA寻找数据最大方差的自然基,称为主成分。
Eigenfaces的算法流程
X={x1,x2,…,xn} 是一组随机向量
1.计算均值μ
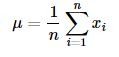
2.去中心化,计算协方差矩阵S
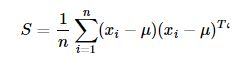
3.计算矩阵S的特征值λ i和特征向量v i
4.根据特征值对特征向量降序排列,k个主成分就是k个最大的特征值的特征向量。
观察量x的k个主成分:
PCA基的重构:
其中,W=(v1,v2,…,vk).
Eigenfaces然后执行识别:
- 投射所有训练样本到PCA子空间
- 投射所有测试样本到PCA子空间
- 寻找训练样本和测试样本的投射空间的最近邻
还有个问题要解决,假设我们有100*100的400张图片,PCA要解决方差矩阵S=XXT,这里的X尺寸为10000*400.最后得到的是10000*10000的矩阵,大概0.8个G,这样就很没有灵性,可以这样做,先考虑S=XTX ,这样计算维度就大大减小了。
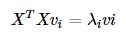 image.png
image.png
然后等式左右都左乘X,就可以巧妙计算S的特征向量了,可以看到,XTX和XXT特征值是相同的。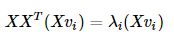 image.png
image.png
opencv里的Eigenfaces
源码见..\opencv_contrib-master\modules\face\samples\facerec_eigenfaces.cpp,在opencv的contrib模块里面,这里贴出来。
/*
* Copyright (c) 2011. Philipp Wagner .
* Released to public domain under terms of the BSD Simplified license.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of the organization nor the names of its contributors
* may be used to endorse or promote products derived from this software
* without specific prior written permission.
*
* See
*/
#include "opencv2/core.hpp"
#include "opencv2/face.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include
#include
#include
using namespace cv;
using namespace cv::face;
using namespace std;
static Mat norm_0_255(InputArray _src) {
Mat src = _src.getMat();
// Create and return normalized image:
Mat dst;
switch(src.channels()) {
case 1:
cv::normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC1);
break;
case 3:
cv::normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC3);
break;
default:
src.copyTo(dst);
break;
}
return dst;
}
static void read_csv(const string& filename, vector& images, vector& labels, char separator = ';') {
std::ifstream file(filename.c_str(), ifstream::in);
if (!file) {
string error_message = "No valid input file was given, please check the given filename.";
CV_Error(Error::StsBadArg, error_message);
}
string line, path, classlabel;
while (getline(file, line)) {
stringstream liness(line);
getline(liness, path, separator);
getline(liness, classlabel);
if(!path.empty() && !classlabel.empty()) {
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str()));
}
}
}
int main(int argc, const char *argv[]) {
// Check for valid command line arguments, print usage
// if no arguments were given.
if (argc < 2) {
cout << "usage: " << argv[0] << " " << endl;
exit(1);
}
string output_folder = ".";
if (argc == 3) {
output_folder = string(argv[2]);
}
// Get the path to your CSV.
string fn_csv = string(argv[1]);
// These vectors hold the images and corresponding labels.
vector images;
vector labels;
// Read in the data. This can fail if no valid
// input filename is given.
try {
read_csv(fn_csv, images, labels);
} catch (cv::Exception& e) {
cerr << "Error opening file \"" << fn_csv << "\". Reason: " << e.msg << endl;
// nothing more we can do
exit(1);
}
// Quit if there are not enough images for this demo.
if(images.size() <= 1) {
string error_message = "This demo needs at least 2 images to work. Please add more images to your data set!";
CV_Error(Error::StsError, error_message);
}
// Get the height from the first image. We'll need this
// later in code to reshape the images to their original
// size:
int height = images[0].rows;
// The following lines simply get the last images from
// your dataset and remove it from the vector. This is
// done, so that the training data (which we learn the
// cv::BasicFaceRecognizer on) and the test data we test
// the model with, do not overlap.
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
images.pop_back();
labels.pop_back();
// The following lines create an Eigenfaces model for
// face recognition and train it with the images and
// labels read from the given CSV file.
// This here is a full PCA, if you just want to keep
// 10 principal components (read Eigenfaces), then call
// the factory method like this:
//
// EigenFaceRecognizer::create(10);
//
// If you want to create a FaceRecognizer with a
// confidence threshold (e.g. 123.0), call it with:
//
// EigenFaceRecognizer::create(10, 123.0);
//
// If you want to use _all_ Eigenfaces and have a threshold,
// then call the method like this:
//
// EigenFaceRecognizer::create(0, 123.0);
//
Ptr model = EigenFaceRecognizer::create();
model->train(images, labels);
// The following line predicts the label of a given
// test image:
int predictedLabel = model->predict(testSample);
//
// To get the confidence of a prediction call the model with:
//
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
//
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
cout << result_message << endl;
// Here is how to get the eigenvalues of this Eigenfaces model:
Mat eigenvalues = model->getEigenValues();
// And we can do the same to display the Eigenvectors (read Eigenfaces):
Mat W = model->getEigenVectors();
// Get the sample mean from the training data
Mat mean = model->getMean();
// Display or save:
if(argc == 2) {
imshow("mean", norm_0_255(mean.reshape(1, images[0].rows)));
} else {
imwrite(format("%s/mean.png", output_folder.c_str()), norm_0_255(mean.reshape(1, images[0].rows)));
}
// Display or save the Eigenfaces:
for (int i = 0; i < min(10, W.cols); i++) {
string msg = format("Eigenvalue #%d = %.5f", i, eigenvalues.at(i));
cout << msg << endl;
// get eigenvector #i
Mat ev = W.col(i).clone();
// Reshape to original size & normalize to [0...255] for imshow.
Mat grayscale = norm_0_255(ev.reshape(1, height));
// Show the image & apply a Jet colormap for better sensing.
Mat cgrayscale;
applyColorMap(grayscale, cgrayscale, COLORMAP_JET);
// Display or save:
if(argc == 2) {
imshow(format("eigenface_%d", i), cgrayscale);
} else {
imwrite(format("%s/eigenface_%d.png", output_folder.c_str(), i), norm_0_255(cgrayscale));
}
}
// Display or save the image reconstruction at some predefined steps:
for(int num_components = min(W.cols, 10); num_components < min(W.cols, 300); num_components+=15) {
// slice the eigenvectors from the model
Mat evs = Mat(W, Range::all(), Range(0, num_components));
Mat projection = LDA::subspaceProject(evs, mean, images[0].reshape(1,1));
Mat reconstruction = LDA::subspaceReconstruct(evs, mean, projection);
// Normalize the result:
reconstruction = norm_0_255(reconstruction.reshape(1, images[0].rows));
// Display or save:
if(argc == 2) {
imshow(format("eigenface_reconstruction_%d", num_components), reconstruction);
} else {
imwrite(format("%s/eigenface_reconstruction_%d.png", output_folder.c_str(), num_components), reconstruction);
}
}
// Display if we are not writing to an output folder:
if(argc == 2) {
waitKey(0);
}
return 0;
}
先说说最关键的类EigenFaceRecognizer,包含在facerec.hpp头文件,代码里可直接包含face.hpp,他的继承关系如下:
创建个Eigenfaces的对象
static Ptr create(int num_components = 0, double threshold = DBL_MAX);
num_components就是主成分分析的成分个数,我们并不知道到底设多少才是最好的,这个依赖与你的输入来试验,保持80应该是比较合适的。threshold是你在预测图片时的阈值,一般就是指预测和训练图片的距离的最大值。如果直接创建create(),那么默认num_components=0。
注意了!:
- 训练和预测都应该在灰度图像上进行,用cvtColor转换一下
- 保证你的训练和预测的图片尺寸一致
在他爸爸BasicFaceRecognizer那里,有这些属性和方法可以访问:
public:
/** @see setNumComponents */
CV_WRAP int getNumComponents() const;
/** @copybrief getNumComponents @see getNumComponents */
CV_WRAP void setNumComponents(int val);
/** @see setThreshold */
CV_WRAP double getThreshold() const;
/** @copybrief getThreshold @see getThreshold */
CV_WRAP void setThreshold(double val);
CV_WRAP std::vector getProjections() const;
CV_WRAP cv::Mat getLabels() const;
CV_WRAP cv::Mat getEigenValues() const;
CV_WRAP cv::Mat getEigenVectors() const;
CV_WRAP cv::Mat getMean() const;
virtual void read(const FileNode& fn);
virtual void write(FileStorage& fs) const;
virtual bool empty() const;
using FaceRecognizer::read;
using FaceRecognizer::write;
他爷爷FaceRecognizer那里定义了train,update,predict,write,read等一些方法,后辈可以覆盖。
注意了!
- read,write保存模型数据可以用xml,yaml
- update是指在原有训练基础上添加图片和标签进行更新,这个只有LBP才能用。
代码里显示了伪彩色图,可以看到不同的Eigenfaces的灰度值是如何分布的,可见,Eigenfaces不仅编码了面部特征,还有光照变化。

然后,我们可以利用低维近似来重构人脸,来看看一个好的重构需要多少Eigenfaces,分别使用了10,30,...,310个Eigenfaces
10个特征向量显然不是很好的,50个看起来已经能够很好的编码面部的一些重要信息了,大概300个,差不多。

Fisherfaces
PCA,是Eigenfaces的核心,可以找到数据最大化方差的特征的线性组合,这是可以呈现数据的一种强有力的方式,但他并没有考虑分类,而且如果丢掉一些成分可能也会丢弃一些判别信息。如果数据的变化由外部因素导致,比如光照,那么PCA的成分不会包含任何判别信息。
线性判别分析是一种降维可分的方法,由老鱼费舍尔(并不是湖人队的)发明。为了找到一种最优分类的特征组合方式,考虑最大化类内散度和最小化类间散度。想法很简单,在低维表示下,同类应该紧紧在一起,而不同类应尽可能远离。
在opencv里面,调用fisherfaces和Eigenfaces是一样的方法。还有第三种方法LBP,后面再讲