作者介绍:
hawkingrei(王维真),中间件高级开发工程师,开源爱好者,TiDB & TiKV Contributor。
WaySLOG(雪松),Rust 铁粉一枚,专注中间件,bug creator。

本文根据 hawkingrei & WaySLOG 在 首届 RustCon Asia 大会 上的演讲整理。
今天我们会和大家聊聊 Rust 在我们公司的二三事,包括在公司产品里面用的两个工具,以及雪松(WaySLOG)做的 Cache Proxy —— Aster 的一些经验。

十年前,我司刚刚成立,那时候其实很多人都喜欢用 PHP 等一些动态语言来支持自己的早期业务。用动态语言好处在于开发简单,速度快。但是动态语言对代码质量、开发的水平的要求不是很高。所以我来到公司以后的第一个任务就是把我们的 PHP 改写成 Golang 业务。在我看了当时 PHP 的代码以后的感受是:动态语言一时爽,代码重构火葬场。因为早期我司还是个人网站,PHP 代码质量比较差,代码比较随意,整套系统做在了一个单体的软件里,我们称这个软件是一个全家桶,所有的业务都堆在里面,比较恶心。所以导致早期我司的服务质量也是非常差,观众给我们公司一个绰号叫「小破站」。
但是随着规模越来越大,还上市了,如果还停留在「小破站」就十分不妥,因此我们开始用 Golang 对服务进行一些改进,包括开发一些微服务来稳定我们的业务。通过这些改造也获得了很好的一个效果,因为 Golang 本身非常简洁,是一个带 GC 的语言,同时还提供了 goroutine 和 channel 一些功能,可以很方便的实现异步操作。但随着业务规模变大,也出现了一些 Golang 无法支持的一些情况。于是,我们将目光转向了 Rust。
1. Remote Cache
Remote Cache 是我们第一个 Rust 服务。该服务是我们公司内部的一套 Cache 服务。
在具体介绍这个服务之前,先介绍一下背景。首先在我们内部,我们的代码库并不像普通的一些公司一个项目一个库,我们是大仓库,按语言分类,把所有相同语言的一个业务代码放到一个仓库里,同时在里面还会封装一些同一种语言会用到的基础库,第三方的依赖放在一个库里面。这样所有的业务都放在一个仓库,导致整个仓库的体积非常巨大,编译也会花很多的时间,急需优化。

此时,我们用到了两个工具—— Bazel 和 Gradle,这两个编译工具自带了 Remote Cache 功能。比如你在一台机器上编译以后,然后换了台机器,你还可以重新利用到上次编译的一个中间结果继续编译,加快编译的速度。
还有一个是叫 Prow 的分布式 CI/CD 系统,它是构建在 K8s 上运行的一套系统,来进行我们的一个分布式编译的功能,通过上面三个工具就可以来加速我们大仓库的一个编译的效率。但是,大家也看到了,首先中间一个工具,Bazel 跟 Gradle 他需要上传我的一个中间产物。这样就需要远端有一个服务,可以兜住上传结果,当有编译任务时,会把任务分布在一个 K8s 集群里面,就会同时有大量的请求,这样我们就需要有个 Remote Cache 的服务,来保证所有任务的 cache 请求。同时,因为我们使用了 Bazel 跟 Gradle,所以在办公网里面,很多开发也需要去访问我们的 Remote Cache 服务,来进行编译加速。

所以对我们 Remote Cache 服务的负担其实是很重的。在我们早期的时候,因为一些历史原因,我们当时只有一台服务器,同时还要承担平均每天 5000-6000 QPS 的请求,每天的量大概是 3TB 左右,并且仓库单次编译的大小还会不断的增加,所以对 Remote Cache 服务造成很大压力。
1.1 Kubernetes Greenhouse
我们当时在想如何快速解决这个问题,最开始我们的解决方法是用 K8s 的 Greenhouse 开源服务(https://github.com/kubernetes/test-infra/tree/master/greenhouse)。
刚开始用的时候还挺好的,但是后来发现,他已经不太能满足我们的需求,一方面是我们每天上传的 Cache 量比较大,同时也没有进行一些压缩,它的磁盘的 GC 又比较简单,它的 GC 就是设置一个阈值,比如说我的磁盘用到了 95%,我需要清理到 80% 停止,但是实际我们的 Cache 比较多。而且我们编译的产物会存在一种情况,对我们来说并不是比较老的 Cache 就没用,新的 Cache 就比较有用,因为之前提交的 Cache 在之后也可能会有所使用,所以我们需要一个更加强大的一个 GC 的功能,而不是通过时间排序,删除老的 Cache,来进行 GC 的处理。
1.2 BGgreenhouse
于是我们对它进行了改造,开发出了 BGreenhouse,在 BGreenhouse 的改造里面,我们增加了一个压缩的功能,算法是用的 zstd,这是 Facebook 的一个流式压缩算法,它的速度会比较快,并且我们还增加了一个基于 bloomfilter 过滤器的磁盘 GC。在 K8s 的 Greenhouse 里面,它只支持 Bazel。在 BGreenhouse 中,我们实现了不仅让它支持 Bazel,同时也可以支持 Gradle。

最初上线的时候效果非常不错,但是后来还是出现了一点问题(如图 5 和图 6)。大家从图中可以看到 CPU 的负载是很高的,在这种高负载下内存就会泄露,所以它就「炸」了……


1.3 Cgo is not Go
我们分析了问题的原因,其实就是我们当时用的压缩算法,在 Golang 里面,用的是 Cgo 的一个版本,Cgo 虽然是带了一个 go,但他并不是 Go。在 Golang 里面,Cgo 和 Go 其实是两个部分,在实际应用的时候,需要把 C 的部分,通过一次转化,转换到 Golang 里,但 Golang 本身也不太理解 C 的部分,它不知道如何去清理,只是简单的调用一下,所以这里面会存在一些很不安全的因素。同时,Golang 里面 debug 的工具,因为没法看到 C 里面的一些内容,所以就很难去做 debug 的工作,而且因为 C 跟 Golang 之间需要转换,这个过程里面也有开销,导致性能也并不是很好。所以很多的时候,Golang 工程师对 Cgo 其实是避之不及的。
1.4 Greenhouse-rs
在这个情况下,当时我就考虑用 Rust 来把这个服务重新写一遍,于是就有了 Greenhouse-rs。Greenhouse-rs 是用 Rocket 来写的,当中还用了 zstd 的库和 PingCAP 编写的 rust-prometheus,使用以后效果非常明显。在工作日的时间段,CPU 和内存消耗比之前明显低很多,可谓是一战成名(如图 7 和图 8 所示)。


1.5 Golang vs Rust
然后我们对比来了一下 Golang 和 Rust。虽然这两门语言完全不一样,一个是带 GC 的语言,一个是静态语言。Golang 语言比较简洁,没有泛型,没有枚举,也没有宏。其实关于性能也没什么可比性,一个带 GC 的语言的怎么能跟一个静态语言做对比呢?Rust 性能特别好。
另外,在 Golang 里面做一些 SIMD 的一些优化,会比较恶心(如图 9)。因为你必须要在 Golang 里先写一段汇编,然后再去调用这段汇编,汇编本身就比较恶心, Golang 的汇编更加恶心,因为必须要用 plan9 的一个特别的格式去写,让人彻底没有写的兴趣了。

但在 Rust 里面,你可以用 Rust 里核心库来进行 SIMD 的一些操作,在 Rust 里面有很多关于 SIMD 优化过的库,它的速度就会非常快(如图 10)。经过这一系列对比,我司的同学们都比较认可 Rust 这门语言,特别是在性能上。

2. Thumbnail service
之后,我们又遇到了一个服务,就是我们的缩略图谱,也是用 Rust 来做图片处理。缩略图谱服务的主要任务是把用户上传的一些图片,包括 PNG,JPEG,以及 WEBP 格式的图,经过一些处理(比如伸缩/裁剪),转换成 WEBP 的图来给用户做最后的展示。

但是在图片处理上我们用了 Cgo,把一些用到的基础库进行拼装。当然一提到 Cgo 就一种不祥的预感,线上情况跟之前例子类似,负载很高,而在高负载的情况下就会发生内存泄露的情况。
2.1 Thumbnail-rs
于是我们当时的想法就是把 Golang 的 Cgo 全部换成 Rust 的 FFI,同时把这个业务重新写了一遍。我们完成的第一个工作就是写了一个缩略图的库,当时也看了很多 Rust 的库,比如说 image-rs,但是这个里面并没有提供 SIMD 的优化,虽然这个库能用也非常好用,但是在性能方面我们不太认可。
2.2 Bindgen
所以我们就需要把现在市面上用的比较专业的处理 WEBP,将它的基础库进行一些包装。一般来说,大家最开始都是用 libwebp 做一个工作库,简单的写一下,就可以自动的把一个 C++ 的库进行封装,在封装的基础上进行一些自己逻辑上的包装,这样很容易把这个任务完成。但是这里面其实是存在一些问题的,比如说 PNG,JPEG,WEBP 格式,在包装好以后,需要把这几个库 unsafe 的接口再组装起来,形成自己的逻辑,但是这些 unsafe 的东西在 Rust 里面是需要花一些精力去做处理的, Rust 本身并不能保证他的安全性,所以这里面就需要花很多的脑力把这里东西整合好,并探索更加简单的方法。
我们当时想到了一个偷懒的办法,就是在 libwebp 里边,除了库代码以外会提供一些 Example,里面有一个叫 cwebp 的一个命令行工具,他可以把 PNG,JPEG 等格式的图片转成 WEBP,同时进行一些缩略剪裁的工作。它里面存在一些相关的 C 代码,我们就想能不能把这些 C 的代码 Copy 到项目里,同时再做一些 Rust 的包装?答案是可以的。所以我们就把这些 C 的代码,放到了我们的项目里面,用 Bindgen 工具再对封装好的部分做一些代码生成的工作。这样就基本写完我们的一个库了,过程非常简单。
2.3 Cmake && Bindgen
但是还有一个问题,我们在其中用了很多 libpng、libwebp 的一些库,但是并没有对这些库进行一些版本的限制,所以在正式发布的时候,运维同事可能不知道这个库是什么版本,需要依赖与 CI/CD 环境里面的一些库的安装,所以我们就想能不能把这些 lib 库的版本也托管起来,答案也是可以的。

图 12 中有一个例子,就是 WEBP 的库是可以用 Cmake 来进行编译的,所以在我的 build.rc 里面用了一个 Cmake 的库来指导 Rust 进行 WEBP 库的编译,然后把编译的产物再去交给 Bindgen 工具进行自动化的 Rust 代码生成。这样,我们最简单的缩略图库很快的就弄完了,性能也非常好,大概是 Golang 三倍。我们当时测了 Rust 版本请求的一个平均的耗时,是 Golang 版本的三倍(如图 13)。

2.4 Actix_Web VS Rocket
在写缩略图服务的时候,我们是用的 Actix_Web 这个库,Greenhouse 是用了 Rocket 库,因为同时连续两个项目都使用了不同的库,也有一种试水的意思,所以在两次试水以后我感觉还是有必要跟大家分享一下我的感受。这两个库其实都挺好的,但是我觉得 Rocket 比较简单,同时还带一些宏路由,你可以在 http handle 上用一个宏来添加你的路由,在 Actix 里面就不可以。 Actix 支持 Future,性能就会非常好,但是会让使用变得比较困难。Rocket 不支持 Future,但基本上就是一个类似同步模型的框架,使用起来更简单,性能上很一般。我们后续计划把 Greenhouse 用 Actix_web 框架再重新写一遍,对比如下图所示。

以上就是我司两个服务的小故事和一些小经验。
3. Rust 编译过慢
前面分享了很多 Rust 的优点,例如性能非常好,但是 Rust 也有一个很困扰我们的地方,就是他编译速度和 Golang 比起来太慢了, 在我基本上把 Rust 编译命令敲下以后,出去先转上一圈,回来的时候还不一定能够编译完成,所以我们就想办法让 Rust 的编译速度再快一点。
3.1 Prow
首先是我们公司的 Prow,它其实也不是我司原创,是从 K8s 社区搬过来的。Prow 的主要功能是把一个大仓库里面的编译任务通过配置给拆分出来。这项功能比较适合于大仓库,因为大的仓库里面包含了基础库和业务代码,修改基础库以后可能需要把基础库和业务代码全部再进行编译,但是如果只改了业务代码,就只需要对业务代码进行编译。另外同基础库改动以后,时还需要按业务划分的颗粒度,分散到不同的机器上对这个分支进行编译。
在这种需求下就需要用到 Prow 分布式编译的功能,虽然叫分布式编译,但其实是个伪分布式编译,需要提前配置好,我们现在是在大仓库里面通过一个工具自动配置的,通过这个工具可以把一个很大规模存量的编译拆成一个个的小的编译。但是有时候我们并一定个大仓库,可能里面只是一个很简单的业务。所以 Prow 对我们来说其实并不太合适。
3.2 Bazel
另外介绍一个工具 Bazel,这是谷歌内部类似于 Cargo 的一个编译工具,支持地球上几乎所有的语言,内部本质是一个脚本工具,内置了一套脚本插件系统,只要写一个相应的 Rules 就可以支持各种语言,同时 Bazel 的官方又提供了 Rust 的编译脚本,谷歌官方也提供了一些相应的自动化配置生成的工具,所以 Golang 在使用的时候,优势也很明显,支持 Remote Cashe。同时 Bazel 也支持分布式的编译,可以去用 Bazel 去做 Rust 的分布式编译,并且是跨语言的,但这个功能可能是实验性质的。也就是说 Rust 可能跟 Golang 做 Cgo,通过 Golang Cgo 去调 Rust。所以我们通过 Bazel 去进行编译的工作。但缺点也很明显,需要得从零开始学 Rust 编译,必须要绕过 Cargo 来进行编译的配置,并且每个目录层级下面的原代码文件都要写一个 Bazel 的配置文件来描述你的编译过程。
为了提升性能,就把我们原来使用 Rust 的最大优势——Cargo 这么方便的功能直接给抹杀掉了,而且工作量也很大。所以 Bazel 也是针对大仓库使用的一个工具,我们最后认为自己暂时用不上 Bazel 这么高级的工具。
3.3 Sccahe
于是我们找了一个更加简单的工具,就是 Firefox 官方开发的 Sccahe。它在远端的存储上面支持本地的缓存,Redis,Memcache,S3,同时使用起来也非常简单,只要在 Cargo 里面安装配置一下就可以直接使用。这个工具缺点也很明显,简单的解释一下, Sccahe 不支持 ffi 里涉及到 C 的部分,因为 C 代码的 Cache 会存在一些问题,编译里开的一些 Flag 有可能也会不支持(如下图所示)。

所以最后的结论就是,如果你的代码仓库真的很大,比 TiKV 还大,可能还是用 Bazel 更好,虽然有学习的曲线很陡,但可以带来非常好的收益和效果,如果代码量比较小,那么推荐使用 Sccahe,但是如果你很不幸,代码里有部分和 C 绑定的话,那还是买一台更好的电脑吧。
4. Cache Proxy
这一部分分享的主题是「技术的深度决定技术的广度」,出处已经不可考了,但算是给大家一个启迪吧。

下面来介绍 Aster。Aster 是一个简单的缓存代理,基本上把 Corvus(原先由饿了么的团队维护)和 twemproxy 的功能集成到了一起,同时支持 standalone 和 redis cluster 模式。当然我们也和 Go 版本的代理做了对比。相比之下,QPS 和 Latency 指标更好。因为我刚加入我司时是被要求写了一个 Go 版本的代理,但是 QPS 和 Latency 的性能不是很好,运维又不给我们批机器,无奈只能是自己想办法优化,所以在业余的时间写了一个 Aster 这个项目。但是成功上线了。

图 18 是我自己写的缓存代理的进化史,Corvus 的话,本身他只支持 Redis Cluster,不支持 memcache 和是 Redis Standalone 的功能。现在 Overlord 和 Aster 都在紧张刺激的开发中,当然我们现在基本上也开发的差不多了,功能基本上完备。

因为说到 QPS 比较高,我们就做了一个对比,在图 19 中可以看到 QPS 维度的对比大概是 140 万比 80 万左右,在 Latency 维度上 Aster 相较于 Overlord 会更稳定,因为 Aster 没有 GC。

4.1 无处安放的类型转换
给大家介绍一下我在写 Aster 的时候遇到了一些问题,是某天有人给我发了图 20,是他在写 futures 的时候,遇到了一个类型不匹配的错误,然后编译报出了这么长的错误。

可能大家在写 Future 的时候都会遇到这样的问题,其实也没有特别完善的解决办案,但可以在写 Future 和 Stream 的时候尽量统一 Item 和 Error 类型,当然我们现在还有 failure::Error 来帮大家统一。
这里还重点提一下 SendError。SendError 在很多 Rust 的 Channal 里面都会实现。在我们把对象 Push 进这个队列的时候,如果没有足够的空间,并且 ownership 已经移进去了,那么就只能把这个对象再通过 Error 的形式返回出来。在这种情况下,如果你不处理这个 SendError,不把里面的对象接着拿下来,就有可能造成这个对象无法得到最后的销毁处理。我在写 Aster 的时候就遇到这样的情况。
4.2 drop 函数与唤醒
下面再分享一下我认为 Rust 相比 Golang 、 C 及其他语言更好的一个地方,就是 Drop 函数。每一个 Future 最终都会关联到一个前端的一个 FD 上面,关联上去之后,我们需要在这个 Future 最后销毁的时候,来唤醒对应的 FD ,如果中间出现了任何问题,比如 SendError 忘了处理,那么这个 Future 就会一直被销毁,FD 永远不会被唤醒,这个对于前端来说就是个大黑盒。
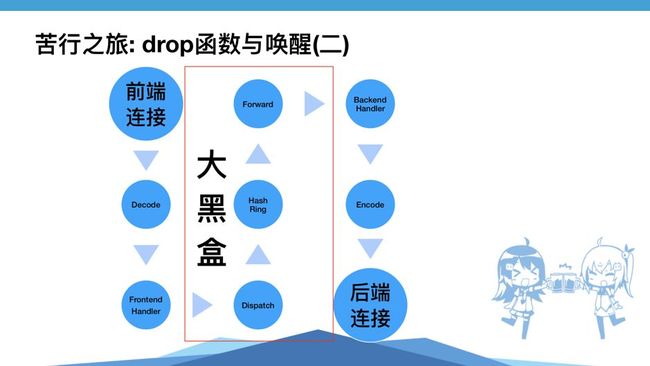
于是我们就想到用 Drop 函数维持一个命令的 Future 的引用计数,引用计数到了归零的时候,实际上就相当于这个 Future 已经完全结束了,我们就可以通过归零的时候来对它进行唤醒。但是一个命令可能包含很多子命令,每一个子命令完成之后都要进行一次唤醒,这样代价太高,所以我们又加入了一个计数,只有这个计数归零的时候才去唤醒一次。这样的话,效率会很高。

4.3 让人头秃的 profile
Aster 最初的版本性能已经很高了,接着我们对它进行了两版优化,然而越优化性能越低,我们感到很无奈,然后去对它做了一个 Profile,当然,现在一般我采用的手段都是 perf 或者火焰图,我在对 Rust 程序做火焰图的时候,顺手跑了个命令,perf 命令,用火焰图工具把他处理一下,最后生成出来的结果不是很理想,有很多 unknown 的函数,还有函数名及线程名显示不全的情况(如图 23)。

然后我们开始尝试加各种各样的参数,包括 force-frame-pointers 还有 call-graph 但是最后的效果也不是很理想。直到有一天,我发现了一个叫 Cargo Flame Graph 的库,尝试跑了一下,很不幸失败了,它并没有办法直接生成我们这种代理程序的火焰图,但是在把它 CTRL-C 掉了之后,我们发现了 stacks 文件。如果大家熟悉火焰图生成的话,对 stacks 肯定是很熟悉的。然后我们就直接用火焰图生成工具,把它再重新展开。这次效果非常好,基本上就把所有的函数都打全了(如图 24)。

4.4 paser 回溯
这个时候我们就可以针对这个火焰图去找一下我们系统的瓶颈,在我们测 benchmark 的时候,发现当处理有几万个子命令的超长命令的时候,Parser 因为缓存区读不完,会来回重试解析,这样非常消耗 CPU 。于是我们请教了 DC 老师,让 DC 老师去帮我们写一个不带回溯的、带着状态机的 Parser。

这种解法对于超长命令的优化情况非常明显,基本上就是最优了,但是因为存了状态,所以它对正常小命令优化的耗时反而增加了。于是我们就面临一个取舍,要不要为了 1% 的超长命令做这个优化,而导致 99% 的命令处理都变慢。我们觉得没必要,最后我们就也舍去了这种解法,DC 老师的这个 Commit 最终也没有合进我的库,当然也很可惜。
4.5 我最亲爱的 syscall 别闹了
我们做 Profile 的时候发现系统的主要瓶颈是在于syscall,也就是 readfrom 和 sendto 这两个 syscall 里面。
这里插入一个知识点,就是所谓的零拷贝技术。

在进行 syscall 的时候,读写过程中实际上经历了四次拷贝,首先从网卡 buffer 拷到内核缓存区,再从内核缓存区拷到用户缓存区,如果用户不拷贝的话,就去做一些处理然后再从用户缓冲区拷到内核缓存区,再从内核缓存区再把他写到网卡 buffer 里面,最后再发送出去,总共是四次拷贝。有人提出了一个零拷贝技术,可以直接用 sendfile() 函数通过 DMA 直接把内核态的内存拷贝过去。
还有一种说法是,如果网卡支持 SCATTER-GATHER 特性,实际上只需要两次拷贝(如下图右半部分)。

但是这种技术对我们来说其实没有什么用,因为我们还是要把数据拷到用户态缓冲区来去做一些处理的,不可能不处理就直接往后发,这个是交换机干的事,不是我们服务干的事。
4.6 DPDK + 用户态协议栈
那么有没有一种技术既能把数据拷到用户态又能快速的处理?有的,就是 DPDK。
接下来我为大家简单的介绍一下 DPDK,因为在 Aster 里面没有用到。DPDK 有两种使用方式,第一种是通过 UIO,直接劫持网卡的中断,再把数据拷到用户态,然后再做一些处理(如图 28)。这样的话,实际上就 bypass 了 syscall。

第二个方式是用 Poll Model Driver(如图 29)。这样就有一颗 CPU 一直轮循这个网卡,让一颗 CPU 占用率一直是百分之百,但是整体效率会很高,省去了中断这些事情,因为系统中断还是有瓶颈的。

这就是我们今天的分享内容,谢谢大家。
