本篇文章长更,欢迎大家收藏和喜欢
2018.12.25 字符串函数2
1.正则表达式解析函数:regexp_extract
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
举例:
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) fromlxw_dual;
the
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 2) fromlxw_dual;
bar
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 0) fromlxw_dual;
foothebar
注意,在有些情况下要使用转义字符,下面的等号要用双竖线转义,这是java正则表达式的规则。
select data_field,
regexp_extract(data_field,'.*?bgStart\\=([^&]+)',1) as aaa,
regexp_extract(data_field,'.*?contentLoaded_headStart\\=([^&]+)',1) as bbb,
regexp_extract(data_field,'.*?AppLoad2Req\\=([^&]+)',1) as ccc
from pt_nginx_loginlog_st
where pt = '2012-03-26'limit 2;
2. URL解析函数:parse_url
语法: parse_url(string urlString, string partToExtract [, stringkeyToExtract])
返回值: string
说明:返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
举例:
hive> selectparse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') fromlxw_dual;
facebook.com
hive> selectparse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k1') from lxw_dual;
v1
3. json解析函数:get_json_object
语法: get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
举例:
hive> select get_json_object('{"store":
> {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}],
> "bicycle":{"price":19.95,"color":"red"}
> },
> "email":"amy@only_for_json_udf_test.net",
> "owner":"amy"
> }
> ','$.owner') from lxw_dual;
amy
2018.12.25 字符串函数2
1.去空格函数:trim
语法: trim(string A)
返回值: string
说明:去除字符串两边的空格
举例:
hive> select trim(' abc ') from lxw_dual;
abc
2.左边去空格函数:ltrim
语法: ltrim(string A)
返回值: string
说明:去除字符串左边的空格
举例:
hive> select ltrim(' abc ') from lxw_dual;
abc
3.右边去空格函数:rtrim
语法: rtrim(string A)
返回值: string
说明:去除字符串右边的空格
举例:
hive> select rtrim(' abc ') from lxw_dual;
abc
4.强制类型转换
select cast(‘1’ as bigint) from dual;
2018.12.20 字符串函数1
1.字符串长度函数:length
语法: length(string A)
返回值: int
说明:返回字符串A的长度
举例:
hive> select length('abcedfg') from lxw_dual;
2.字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
举例:
hive> select substr('abcde',3) from lxw_dual;
cde
hive> select substring('abcde',3) from lxw_dual;
cde
hive> selectsubstr('abcde',-1) from lxw_dual; (和ORACLE相同)
3.字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A)
返回值: string
说明:返回字符串A的大写格式
举例:
hive> select upper('abSEd') from lxw_dual;
ABSED
hive> select ucase('abSEd') from lxw_dual;
ABSED
4.字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A)
返回值: string
说明:返回字符串A的小写格式
举例:
hive> select lower('abSEd') from lxw_dual;
absed
hive> select lcase('abSEd') from lxw_dual;
absed
2018.12.17 统计函数
Null值不参与计算
•个数统计函数: count
•总和统计函数: sum
•平均值统计函数: avg
•最小值统计函数: min
•最大值统计函数: max
2018.12.09 条件判断函数
1.case when
select
case when X1 then A when X2 then B else C end result
当满足X1条件,result输出A,当满足X2条件,result输出B,都不满足输出C
2.if
select
if(判断条件,true返回值, 其他返回值)
2018.12.06 排序函数
排序函数包括Order by、Sort by、Distribute By、Cluster By…你知道它们的用法和不同吗?
1. Order by:“我是全局排序”
解读:order by 会对输入做全局排序,因此只会有一个reduce(多个reduce无法保证全局有序);这样当输入规模较大时,会导致较长的计算时间。
2. distribute by:“我类似于分区,通常和Sort by一起使用” 解读:根据distribute by指定的字段把数据划分到不同的输出reduce文件中。
3. Sort by:“我可以基于分区排序” 解读:sort by不是全局排序,其在数据进入reduce前完成排序,因此,当有多个reduce时,只能保证单个reduce输出有序,不能保证全局有序。
4. Cluster By:“我的本领大,通常等同于 Distribute By + Sort by” 解读:cluster by 除了具有 distribute by 的功能外还兼具 sortby 的功能。 但是cluster by默认升序,不能指定排序规则为asc 或者desc。
介绍完毕,再来个示例吧:
例:近期参加初级、中级、高级认证的考生成绩如下:
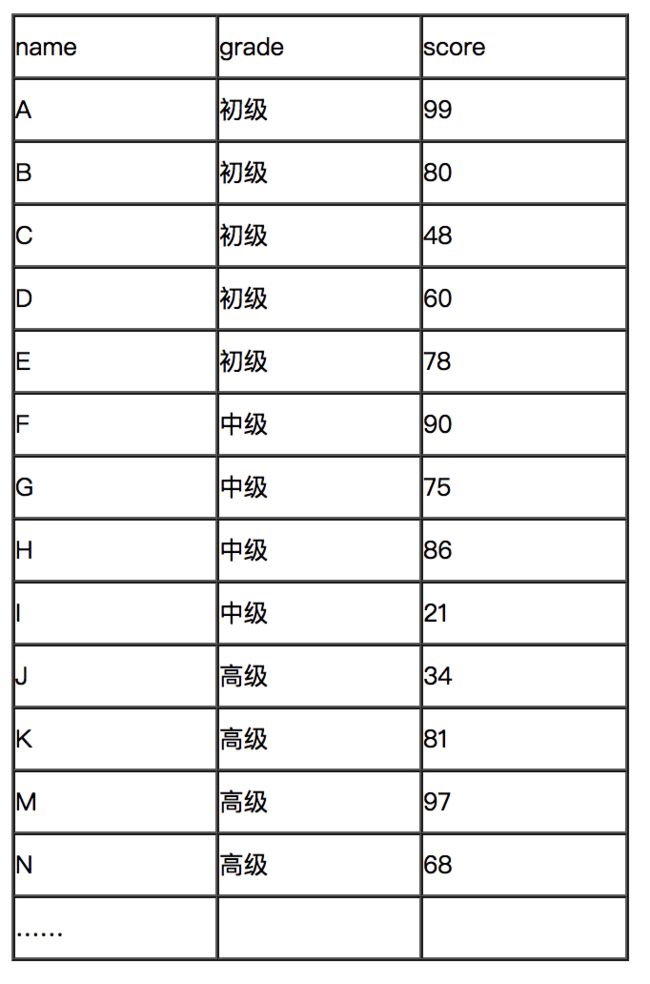
1)通过order by score asc,结果如下:
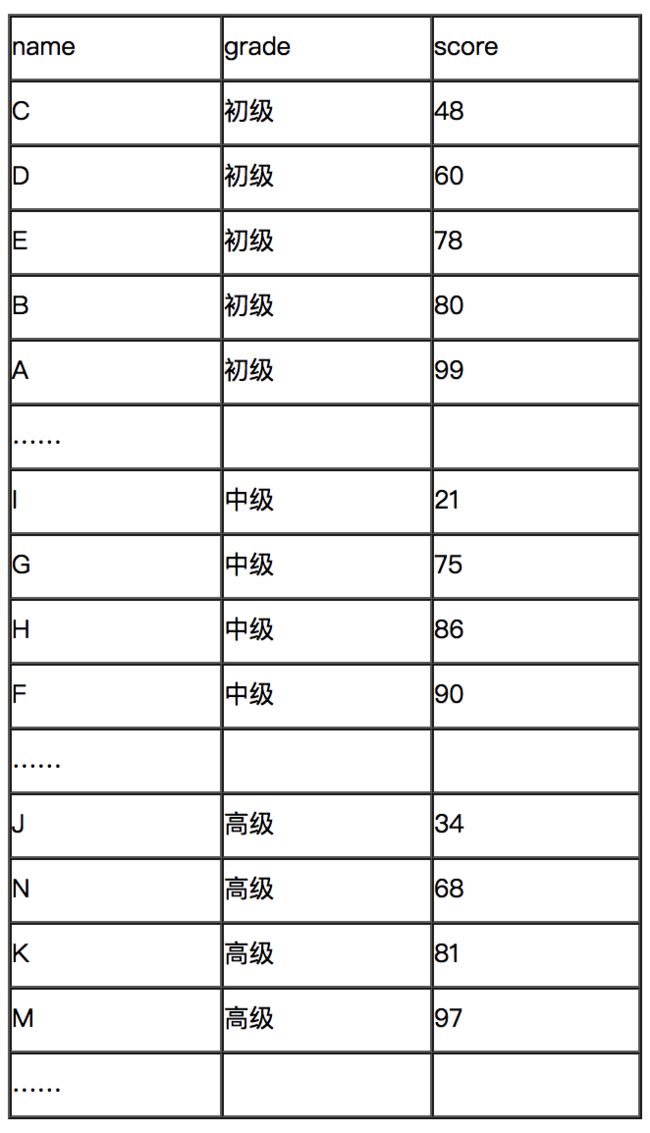
注意:在hive.mapred.mode=strict模式下,使用order by时必须添加limit限制,能够大幅减少reducer数据规模。例如,当限制limit 10时,如果map的个数为20,则reducer的输入规模为10*20
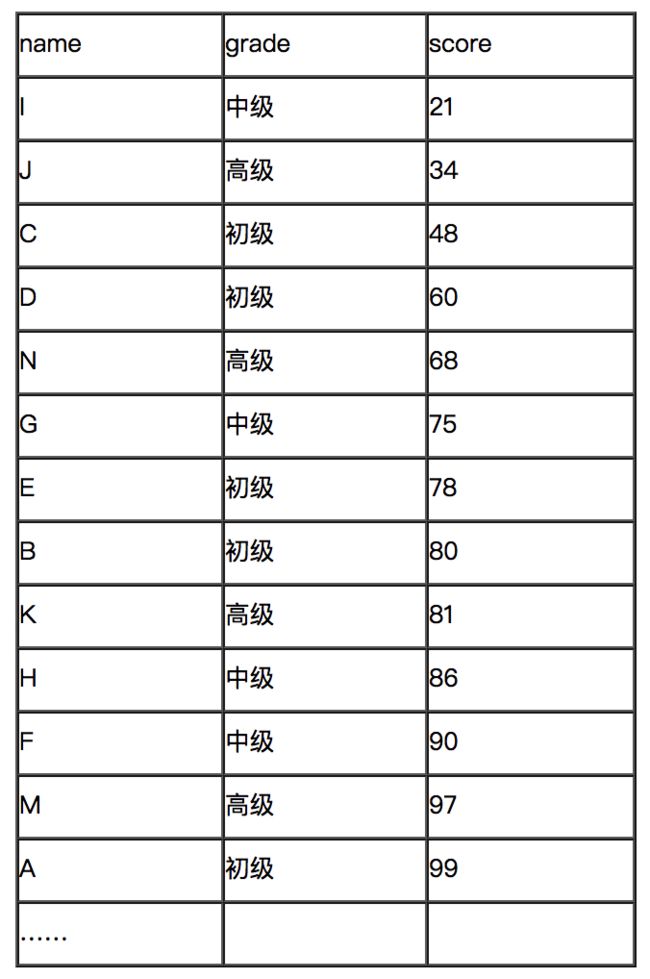
2)通过distribute by grade sort by score asc,结果如下:
3) cluster by grade等价于distribute by grade sort by grade asc,但并不等价distribute by grade sort by score asc。细心的小伙伴发现不同了吗?所以cluster by的本领还是有点局限,distribute by colname1结合sort by colname2更实用哦。
2018.11.22 正则表达式 regexp_extract
语法: regexp_extract(string subject, string pattern, int index) 返回值:string
说明: 将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
第一参数: 要处理的字段
第二参数: 需要匹配的正则表达式
第三个参数:0是显示与之匹配的整个字符串 1 是显示第一个括号里面的 2 是显示第二个括号里面的字段...
实例:
regexp_extract('00aa0', '([0-9]+)', 0) --00
rregexp_extract('00aa0', '([0-9]+)([a-z]+)', 0) --00aa
正则中常用的表达式
中文:[\u4e00-\u9fa5]
英文字母:[a-zA-Z]
数字:[0-9]
匹配中文,英文字母和数字及_: ^[\u4e00-\u9fa5_a-zA-Z0-9]+$
同时判断输入长度:[\u4e00-\u9fa5_a-zA-Z0-9_]{4,10}
2018.11.20 行转列、列转行、多行转单行、一列转多列
行转列、列转行、多行转单行、一列转多列
①行转列:
应用场景:

select
name,
concat_ws('', collect_set(ywscore)) ywscore, --多行转一行
concat_ws('', collect_set(sxscore)) sxscore,
from
(select
name,
case when subject='语文' then score end 'ywscore',
case when subject='语文' then score end 'sxscore'
from XXXX)
group by name
collect_list--不去重,可替换collect_set
②列转行(一列转多行)
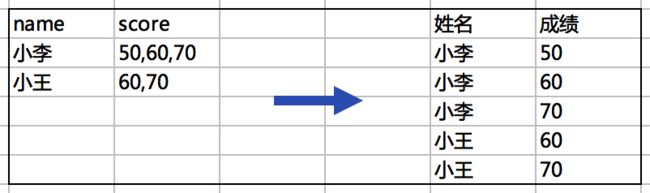
select name,score1
from XXXXX
lateral view explode(split(score, ',')) as score1 --spilt一列变多列
2018.08.08 字符串替换
字符串替换函数
regexp_replace('abcde', 'a', 'm') ;--mbcde
注意regexp_replace可以连用,最多连三次
regexp_replace(regexp_replace(regexp_replace('abcde', 'a', 'm'), 'b', 'm'), 'c', 'm') --mmmde
2018.06.01 时间函数
8.其他日期函数
查询当月第几天: dayofmonth(current_date);
月末: last_day(current_date)
当月第1天: date_sub(current_date,dayofmonth(current_date)-1)
下个月第1天: add_months(date_sub(current_date,dayofmonth(current_date)-1),1)
2018.05.27 时间函数
1.日期转时间戳:从1970-01-01 00:00:00 UTC到指定时间的秒数
select unix_timestamp(); 获得当前时区的UNIX时间戳
select unix_timestamp('2018-05-27 14:23:00');--1527402180
select unix_timestamp('2018-05-27 14:23:00','yyyy-MM-dd HH:mm:ss');
select unix_timestamp('20180527 14:23:00','yyyyMMdd HH:mm:ss');
2.时间戳转日期
select from_unixtime(1527402180);--2018-05-27
select from_unixtime(1505456567,'yyyyMMdd');
select from_unixtime(1505456567,'yyyy-MM-dd HH:mm:ss');
3.获取当前日期: current_date
select current_date --2018-05-27
4.日期时间转日期:to_date(string timestamp)
select to_date('2018-05-27 11:12:00') ; --2018-05-27
5.获取日期中的年/月/日/时/分/秒/周
select year(dt),month(dt),day(dt),hour(dt),minute(dt),second(dt),weekofyear(dt)
6.计算两个日期之间的天数: datediff
select datediff('2018-05-27','2018-05-25') ; --2
7.日期增加和减少: date_add/date_sub(string startdate,int days)
select date_add('2018-05-27',1) ; --2018-05-28
select date_sub('2018-05-27',1) ; --2018-05-26
2018.03.21 取以经纬度范围多少公里数据
( abs(latitude - 30.528941640491446) * 111 <= 5 and abs(longitude - 120.69242) * 111 <= 5)
30.528941640491446是经度,120.69242是纬度,5是公里
2018.03.10 map类型字段
直接使用ext_columns["key"]可得到value
json串解析:str_to_map(page_param) ['"skuid"']
2018.03.04 字符串分割函数:split()
split(split(ct_url,'com/') [1], '.html') [0]
使用多个符号分割用[,],不仅可以取符号分割,还可以取字母,常用词组等
split(cfv_cate_90dcate3, '[,#]') [4]
注意:分割后结果为数组,数组指针从0开始,所以必须带上[指针]调用
2018.02.27 分组排序函数:row_number(),dense_rank(),rank()
应用场景:对品类下去品牌销量TOP3,品牌下取销量TOP商品,各班级英语成绩最高的前3名,班级中各科成绩学生排名等。
实例:对品牌下型号销量进行排序,取各品牌销量前三型号。
建表,写入表数据如下:
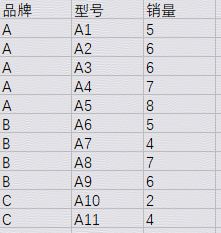
取数脚本:
“
SELECT
brand,
size,
salenum,
row_number() over(partition by brand order by salenum) row_number,
dense_rank() over(partition by brand order by salenum) dense_rank,
rank() over(partition by brand order by salenum) rank
from
dev_3c_xtzc.moring_share_rownumber_3c_zwh aa
”
结果:
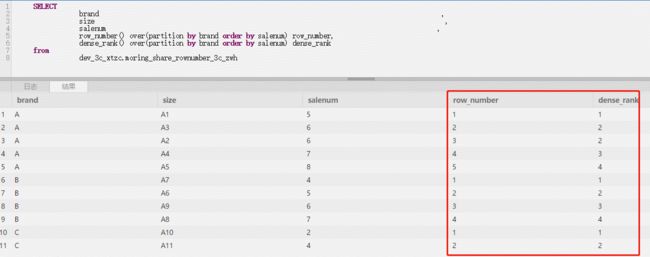
其中:1.over为窗口函数,取当前查询的结果集2.partition可理解为切片分区,根据brand进行分区3.row_number、dense_rank和rank的区别是row_number遇到相同分数,不做并列,直接递增排序,dense_rank和rank会取并列值,rank并列值后跳过间隔排序,即最大值和row_number的一致。