作者:吴世飞 | 连玉君 ( 知乎 | | 码云 | github )
Stata 现场培训报名中……
1. 何谓离群值?

离群值 (outliers)
是指在一份数据中,与其他观察值具有明显不同特征的那些观察值。
然而,并没有一个明确的准则来判断哪些观察值属于“离群值”。这主要取决于多种因素。
比如,下图中:
 Paste_Image.png
Paste_Image.png
姚明算不算离群值?
郭敬明呢?
杨幂呢?
刘翔呢?
对于姚明算不算离群值?,这本身就是一个非常不严谨的问题。
因为,我们可以找到很多变量来描述姚明的特征,比如身高、颜值、智商、情商、跑步速度、沟通能力,等等。
可能所有看到图片的读者的第一反应都是,姚明好高!如果据此推断“姚明的身高是离群值”,那你实际上潜意识里把图片中四人的身高构成的样本视为从一个更大的母体中的随机抽样。换言之,你将普通人的身高作为分析对象。此时,基本上可以认为姚明是离群值。
以我自己的经历而言,我从16 岁停止长身高开始,到现在过去了 20 多年,亲眼见过的人应该不少于 10000 人了。其中只有 3-5 位身高超过 2 米,最高的那位身高 2.10 米,曾是广东排球队的队员。根据 NBA 的官方统计,姚明的身高是 2.26 米。这意味着,若以普通人的身高作为母体来随机抽样,抽取的 10000 个观察值中身高超过 2.26 米的概率是接近于 0 ( 0/10000 = 0)。
若将对照组调整为 NBA 球员,情况又如何呢?在 NBA 的官网上可以看到,2002-2003 赛季所有 413 个球员中,姚明身高位列第二。
然而,若我们将对照组改为“NBA中锋” ,从下图可以看到, NBA 中锋的平均身高为 2.11 米。由于不知道标准差,所以无法判断具体的分布,但可以想象,姚明站在一群 NBA 中锋中,虽然仍是高个儿,但若说他的身高是离群值,怕是有不少中锋会不高兴。
 image.png
image.png
如果抛开身高,从其他特征来看,比如沟通能力,智商等,姚明可能都不能算做离群值,应该都在平均值附近。
因此,离群值其实是一个主观概念!若是一般人为参照对象,
对于刘翔,其奔跑速度可能是离群值,但身高则未必是;
对于郭敬明,其身高和创作能力可能都是离群值,但情商和智商则未必是;
此外,从姚明的例子可以看出,在处理数据时,我们可以把姚明的身高视为离群值,从样本中删除之——所谓的截尾;也可以将姚明的资料视为姚明明,后者的身高被我们人为设定为 1.98 米 (样本中的第 1 百分位数),而其他方面的资料则与姚明完全相同——所谓的缩尾。
2. 离群值存在会怎样?
大多数的参数统计数值,如均值、标准差、相关系数 等,以及基于这些参数的统计分析,均对离群值高度敏感。因此,离群值的存在会对数据分析造成极大影响。
范例:美国妇女工资的决定因素
先看一看数据中小时工资( wage )的分布情况
sysuse nlsw88.dta, clear
histogram wage, ylabel(, angle(0))
绘图结果如下
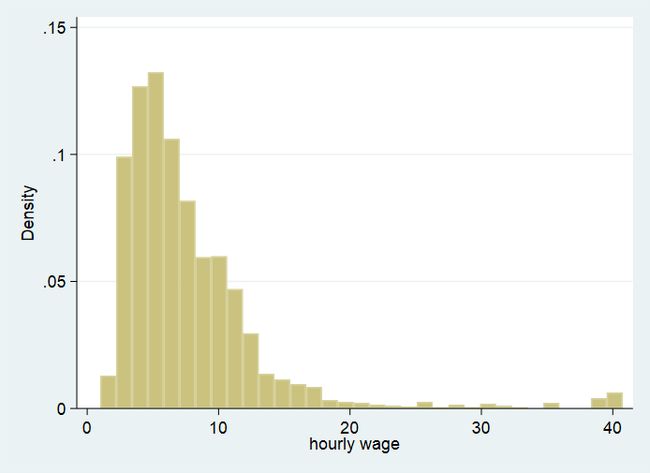 妇女小时工资的直方图
妇女小时工资的直方图
从上图中可以发现,小时工资在 20 以上的观察值比重较小(在 1988 年,仅有极少的女性能够在每小时赚到 20 美元以上!这些是所谓的高薪个体。),这些观察值很可能属于离群值。
下面我们来看一下,在包含和不包含高薪个体的情况下,工资方程的回归结果分别是怎样的。
sysuse nlsw88.dta, clear
qui reg wage age ttl_exp collgrad
est store ttl
qui reg wage age ttl_exp collgrad if wage < 20
est store norm
esttab ttl norm, mtitle( ) ar2
回归结果如下:
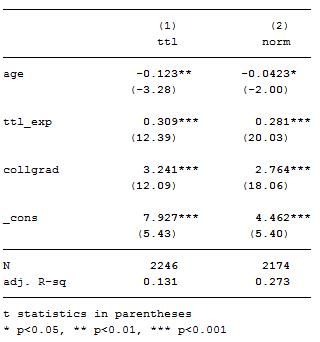
从以上回归结果中可以发现,在去掉样本中的
高薪个体后,模型的
拟合优度明显提高,年龄(
age)系数的显著性有所下降,这些均体现了离群值对分析所带来的影响。
3. 离群值的处理方法
- 对数转换
- 缩尾
- 截尾
- 插值
3.1 对数转换
对存在离群值的变量作对数转换可以克服其离群值问题,且对数转换并不影响各观察值之间在此变量上的相对大小。
为什么对数转换可以克服离群值问题呢?这是因为,转换后数据的分布会变得更加集中。换句话说,虽然对数转换并不改变原有数值的相对大小关系,但却使得转换后数值之间的相对距离缩小了。
比如,在下表中, 10 与 1000 相差百倍,但二者的对数值却仅相差 3 倍。可见对数转换后,其分布变得更加集中了。
| x | ln( x ) |
|---|---|
| 10 | 2.3 |
| 100 | 2.3 × 2 = 4.6 |
| 1000 | 2.3 × 3 = 6.9 |
沿前例:
对 wage 变量进行对数转换
sysuse nlsw88.dta, clear
gen ln_wage = ln(wage)
看看对数转换后发生了什么变化
histogram wage, ylabel(, angle(0)) xtitle("wage") name(fig1, replace)
histogram ln_wage, ylabel(, angle(0)) xtitle("ln_wage") name(fig2, replace)
graph combine fig1 fig2
绘图结果如下
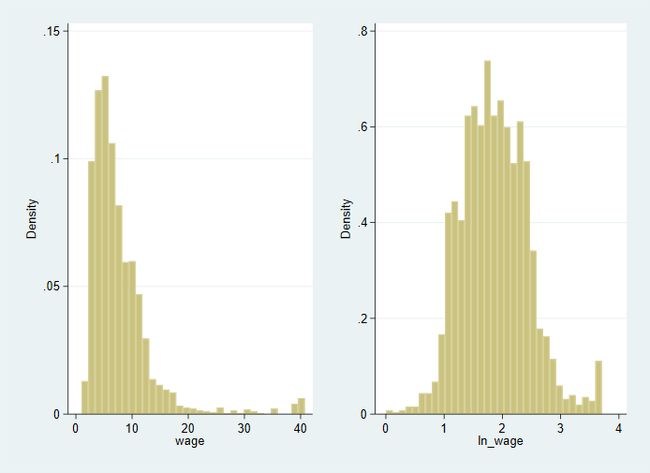 对数转换.png
对数转换.png
从上图中可见,经对数转换后的工资变量(ln_wage)的离群值明显减少,分布也更加集中。
需要注意的是,如果用对数转换后的数据进行回归分析,则回归模型中
系数的经济含义会发生变化。
以线性回归为例,下表列示了不同模型设定下,回归系数的经济含义。
| 回归模型 | 回归系数( β )的经济含义 |
|---|---|
| y= α + β x | 边际效应 |
| ln( y ) = α + β ln( x ) | 弹性 |
| ln( y ) = α + β x | 半弹性 |
3.2 缩尾
将超出变量特定百分位范围的数值替换为其特定百分位数值的方法。
help winsor
沿前例:
对 wage 变量进行缩尾处理
sysuse nlsw88.dta, clear
winsor wage, gen(wage_w) p(0.025)
gen(wage_w)选项:为缩尾后所得的新变量设定名称为“ wage_w ”。
p(0.025)选项:指定分别在第 2.5 百分位和第 97.5 百分位进行缩尾。即,将 wage 变量中小于其 2.5 百分位的数值替换为其 2.5 百分位数值;将 wage 变量中大于其 97.5 百分位的数值替换为其 97.5 百分位数值。(注:这一过程是双侧缩尾,是winsor命令的默认处理方式。)
看看缩尾后发生了什么变化
histogram wage, ylabel(, angle(0)) xtitle("wage") name(fig1, replace)
histogram wage_w, ylabel(, angle(0)) xtitle("wage_w") name(fig2, replace)
graph combine fig1 fig2
绘图结果如下
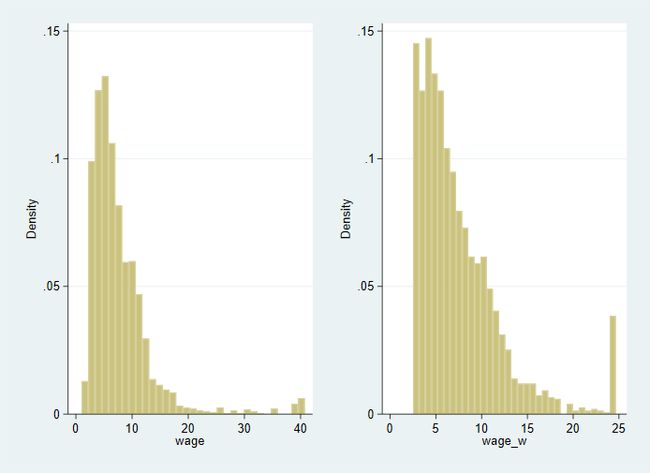 winsor.png
winsor.png
缩尾后,对应于之前变量的2.5和97.5百分位上的数值变多了,这是由原来超过该范围的“离群值”转换而来的。
但是,我们之前已经发现, wage 变量的原始数据似乎只在右侧存在离群值,在左侧并不存在离群值。我们可以通过winsor命令的highonly或lowonly选项来进行单侧缩尾处理。
仅对 wage 变量进行右侧缩尾
sysuse nlsw88.dta, clear
winsor wage, gen(wage_wh) p(0.025) highonly
histogram wage_wh, ylabel(, angle(0)) xtitle("wage_wh")
绘图结果如下
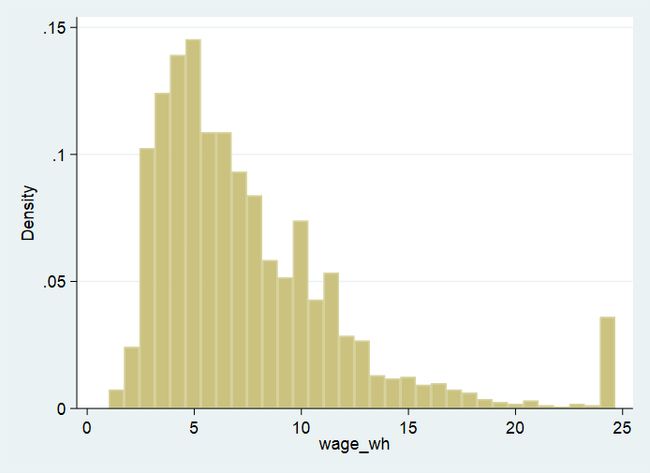 winsor_h.png
winsor_h.png
3.3 截尾
将超出变量特定百分位范围的数值予以删除的方法。
help winsor2
沿前例:
对 wage 变量进行截尾处理
sysuse nlsw88.dta, clear
winsor2 wage, cut(2.5 97.5) trim
cut(2.5 97.5)选项:指定分别在第 2.5 百分位和第 97.5 百分位进行截尾。即,将 wage 变量中小于其 2.5 百分位的数值或大于其 97.5 百分位的数值予以删除。
trim选项:指定进行截尾处理(否则默认进行缩尾处理)。
看看截尾后发生了什么变化
histogram wage, ylabel(, angle(0)) xtitle("wage") name(fig1, replace)
histogram wage_tr, ylabel(, angle(0)) xtitle("wage_tr") name(fig2, replace)
graph combine fig1 fig2
绘图结果如下
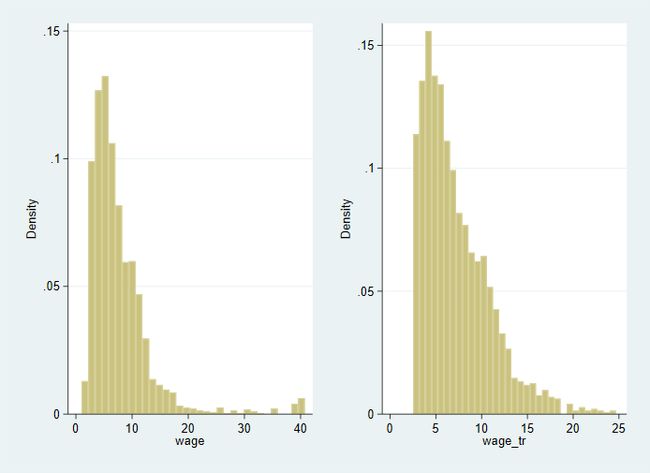 trim.png
trim.png
超过原来数据 2.5% ~ 97.5% 范围的部分被 截断了。
同样,我们可能仅需对 wage 变量进行右侧截尾
sysuse nlsw88.dta, clear
winsor2 wage, cut(0 97.5) trim suffix(_trh)
histogram wage_trh, ylabel(, angle(0)) xtitle("wage_trh")
绘图结果如下
 trim_h.png
trim_h.png
延伸 :
winsor2命令 —— 一个命令满足缩、截尾全部需要
winsor2命令比winsor命令的功能丰富得多。不只是因为winsor2可以执行缩尾和截尾两种操作,更重要的是,它还增加了多变量操作、分组操作、替换原变量等实用功能。
winsor2命令的语法如下
winsor2 varlist [if] [in], [ suffix(string) replace trim cuts(# #) by(groupvar) label ]
varlist:可以输入多个变量进行操作。
replace选项:指定用处理后的变量替换原变量。
trim选项:指定进行截尾处理(否则默认进行缩尾处理)。
cuts(# #)选项:指定进行缩、截尾处理的百分位。默认为cuts(1 99),即在 1% 、 99% 分位数上进行缩、截尾。同理, cuts(0 #) 表示右侧缩、截尾。 cuts(# 100) 表示左侧缩、截尾。
by(groupvar)选项:指定分组操作的组别变量。
3.4 插值
应用原有数据信息对离群值赋予一个相对合理的新值的方法。
对数据进行赋值的方法有很多。比如,随机赋值、最近点赋值、均值赋值、回归赋值等。插值法是对数据赋值的一种方法,一般指的是线性插值( linear interpolation )。参见 Imputation ; Interpolation
在Stata中,ipolate命令可以进行线性插值操作。impute命令可以进行回归赋值操作。
4. 小结
最后,具体采用哪种方法来处理离群值需要结合各方法的特点和研究的需要而定。
比如,在上述方法中,对数转换对某变量的全部观察值均进行了处理,而其他方法则仅对变量中的离群值进行了处理;插值法利用了原有数据中的相关性信息,其他方法则没有利用这些信息;截尾处理会减少数据中的样本量,其他方法则保留了原有数据的样本量。在实际操作中应该结合这些特点进行选择。
此外,对于不同的研究领域,也有不同的适用方法和偏好。比如,在公司金融领域,缩尾被较为广泛地运用。而在时间序列分析中,则更适宜采用插值法。
相关链接
- "3 methods to deal with outliers"
- "Outliers: To Drop or Not to Drop"
这篇写得不错 - "Data on the Edge: Handling Outliers"
这个写得比较简洁 - "Handling Outliers and Missing Data in Statistical Data Models"
PDF 格式,引文写得不错,有不错的图片 - "How would you typically handle and investigate outliers in a dataset?"
一些讨论,有不错的建议和 github 上的范例。 - "Dealing with Outliers"
这篇的思路很清楚,先讲为什么会有离群值,然后是处理方法。 - "Outliers with R examples"
关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 【-Stata连享会】 和 【知乎-连玉君Stata专栏】。可以在和知乎中搜索关键词
Stata或Stata连享会后关注我们。 - 推文中的相关数据和程序,以及 Markdown 格式原文 可以在 【Stata连享会-码云】 中获取。【Stata连享会-码云】 中还放置了诸多 Stata 资源和程序。如 Stata命令导航 || stata-fundamentals || Propensity-score-matching-in-stata || Stata-Training 等。
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至
Stata连享会(公众号: StataChina),我们会保留您的署名;录用稿件达五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。 - 意见和资料: 欢迎您的宝贵意见,您也可以来信索取推文中提及的程序和数据。
- 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
Stata 现场培训报名中……
