姓名:梁祥 学号:17021210935
【嵌牛导读】:在存在噪声和簇形状非凸的情况下,划分聚类的先天残疾问题使其无法很好好的解决问题,因此基于密度的聚类思想被提了出来。DBSCAN作为一种简单快速的密度聚类算法很好地体现了这一思想。
【嵌牛鼻子】:密度聚类,DBSCAN
【嵌牛提问】:如何使用密度来界定聚类的终止条件,对于远在天边和近在眼前的点我们应该如何区别对待?
【嵌牛正文】:
在与生俱来的缺陷下,基于划分的聚类方法(如Kmeans算法)只能发现形状为凸的簇。而对于非凸的簇很多情况下,需要使用基于密度的算法来处理。密度聚类的主要特点是:对数据只需要进行一遍扫描就可以发现任意形状的簇,并且在使用密度参数作为终止条件的前提下,不需要事先约定分类的个数,而且对于离群点密度聚类也可以进行很好的处理。这里主要介绍密度聚类中的DBSCAN算法。
1.1 两个参数
Eps: 邻域的最大半径
MinPts: 在 Eps-邻域中的最少点数
1.2 三个概念
直接密度可达的: 点 p 关于Eps, MinPts 是从点q直接密度可达的, 如果
1) p 属于 NEps(q)
2) 核心点条件:
|NEps (q)| >= MinPts
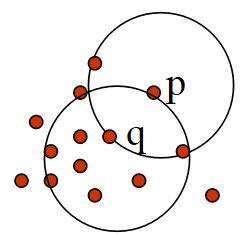
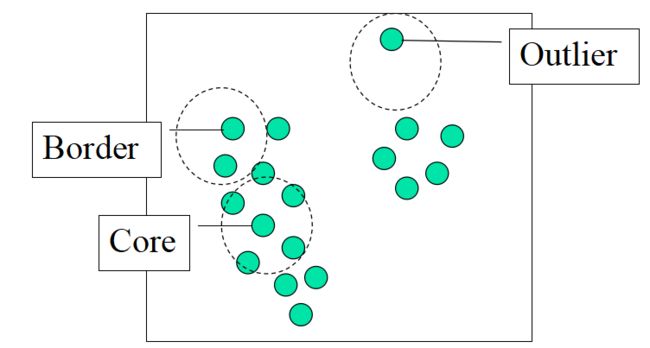
其中,核心对象 (Core object): 一个对象的–邻域至少包含最小数目MinPts个对象;
不是核心点 ,但落在某个核心 点的 Eps 邻域内的对象称为边界点,不属于任何簇的对象为噪声;
对于空间中的一个对象,如果它在给定半径e的邻域中的对象个数大于密度阈值MinPts,则该对象被称为核心对象,否则称为边界对象。
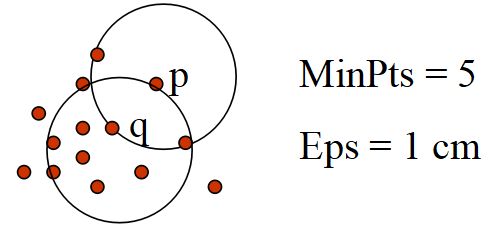
直接密度可达的(Directly density reachable, DDR): 给定对象集合D, 如果p是在q的–邻域内, 而q是核心对象, 我们说对象p是从对象q直接密度可达的(如果q是一个核心对象,p属于q的邻域,那么称p直接密度可达q。)
密度可达的(density reachable): 存在 一个从p到q的DDR对象链(如果存在一条链,满足p1=p,pi=q,pi直接密度可达pi+1,则称p密度可达q)
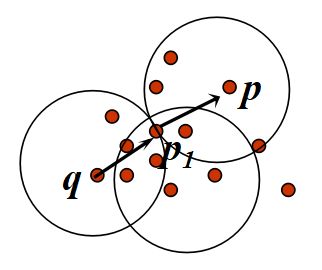
密度相连的:
点 p关于 Eps, MinPts 与点 q是密度相连的, 如果 存在点 o 使得, p 和 q 都是关于Eps, MinPts 是从 o 密度可达的(如果存在o,o密度可达q和p,则称p和q是密度连通的)
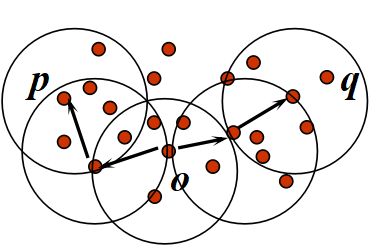
Eg: 假设半径 Ε=3 , MinPts=3 ,点 p 的 Eps 领域中有点 {m,p,p1,p2,o}, 点 m 的Eps 领域中有点 {m,q,p,m1,m2}, 点 q的Eps领域中有 {q,m}, 点 o 的Eps领域中有点 {o,p,s}, 点 s 的Eps领域中有点 {o,s,s1}.那么核心对象有 p,m,o,s(q 不是核心对象,因为它对应的 Eps 领域中点数量等于 2 ,小于 MinPts=3) ;点 m 从点 p 直接密度可达,因为 m 在 p 的Eps领域内,并且 p 为核心对象;点 q 从点 p 密度可达,因为点 q 从点 m 直接密度可达,并且点 m 从点 p 直接密度可达;点 q 到点 s 密度相连,因为点 q 从点 p 密度可达,并且 s 从点 p 密度可达。
1.3 算法步骤:
任意选取一个点 p
得到所有从p 关于 Eps 和 MinPts密度可达的点。
如果p 是一个核心点, 则找到一个聚类。
如果 p 是一个边界点, 没有从p 密度可达的点, DBSCAN 将访问数据库中的下一个点.
继续这一过程, 直到数据库中的所有点都被处理。
1.4 DBSCAN的复杂度
采用空间索引, 复杂度为O(nlog n), 否则为O(n2)。
1.5 DBSCAN的缺点:
对用户定义的参数是敏感的, 参数难以确定(特别是对于高维数据), 设置的细微不同可能导致差别很大的聚类。(数据倾斜分布)全局密度参数不能刻画内在的聚类结构。