逝者如斯夫,不舍昼夜。 —— 孔子
时间如流水,一去不复返。自古不乏对时间流逝的感慨,而现代已经有很多技术记录流逝的过去。我们可以拍照,可以录像,当然还可以用时序数据库!
时序数据库是专门存放随着时间推移而不断变化的数据。近些年,随着IoT等概念的流行,时序数据库成为数据库一个相对独立的领域逐渐受到重视,广泛应用于物联网、监控系统、金融、医疗和零售等多种场景。
热度不断增长")
那么云上的用户如何构建一个存储海量数据的时序数据库呢?笔者这里推荐使用 云HBase + OpenTSDB 方案。云HBase是使用阿里多年优化过的HBase内核版本,本文不作过多介绍,详情请看产品主页。
OpenTSDB简介
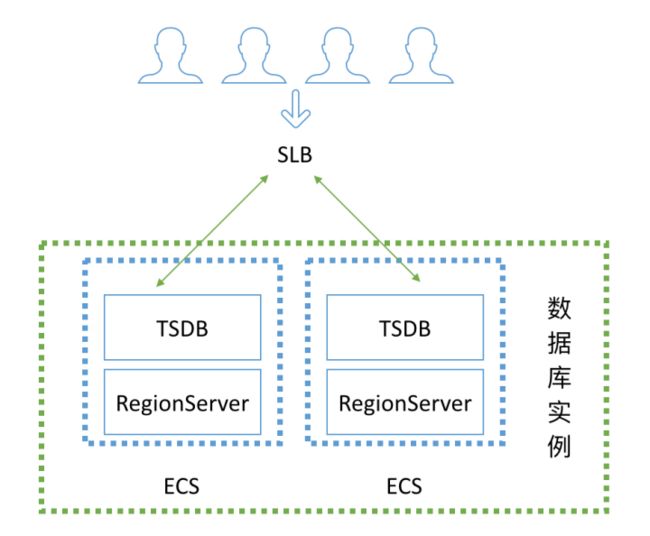
OpenTSDB是一款基于HBase构建的时序数据库,它的数据存储完全交给HBase,本身没有任何数据存储。所有节点是对等的,所以部署起来其实是非常方便的。因为基于HBase,所以本身就具备了横向扩展,存储海量数据的能力。常见的部署模式有2种,一种分离部署,一种混合部署。
独立部署,即与多个业务共享一个HBase。适合时序业务较小,或者用不满HBase资源。
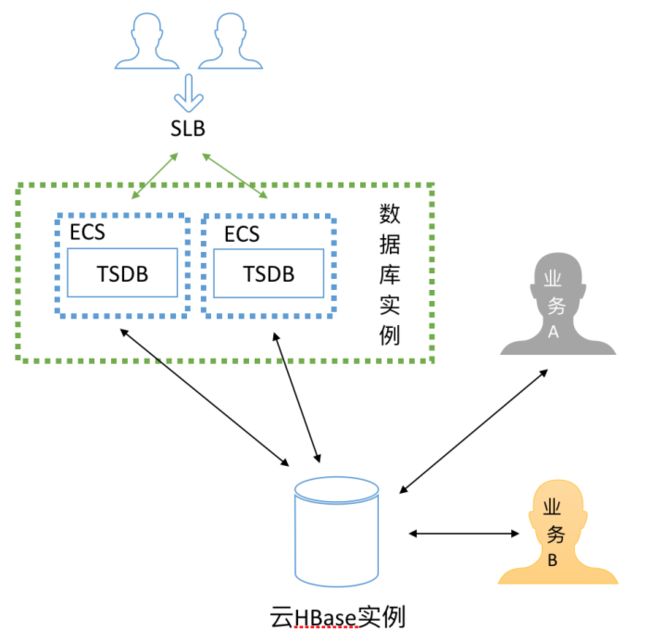
混合部署,即TSDB进程和RS在一个VM内。适合时序业务较重,需要独享HBase。
上述2种模式,云HBase产品都能提供支持,云HBase购买页面现已增加时序引擎购买入口。
OpenTSDB数据定义

一条时间线由 Metirc + 多个tag 唯一确定,时间线上会有源源不断的数据点(Data Point)写入,数据点由时间戳和值组成。OpenTSDB支持秒级(10位整数),毫秒级别(13位整数)两种时间精度。
举个例子,比如我们监控一个手环收集的心跳信息,那么我们可以这样定义:
Metric: "band.heartbeat"
Tags: "id" # 只定义一个tag,就是手环的ID那么我们通过 band.heartbeat + id=1 就能查询到编为1的手环收集到的心跳信息。
OpenTSDB数据存储格式
数据表整体设计

这个设计有几个特点:
- 1.metric和tag映射成UID,不存储实际字符串,以节约空间。
- 2.每条时间线每小时的数据点归在一行,每列是一个数据点,这样每列只需要记录与这行起始时间偏移,以节省空间。
- 3.每列就是一个KeyValue,如果是毫秒精度,一行最多可以有3600000个KV,这里其实会有些问题,后面会讲到。
RowKey格式

salt:打散同一metric不同时间线的热点
metric, tagK, tagV:实际存储的是字符串对应的UID(在tsdb-uid表中)
timestamp:每小时数据存在一行,记录的是每小时整点秒级时间戳
metric和tag
它们长度默认是3个字节,即最多只能分配 2^24=16777216 个UID。可以通过这些参数调整:
tsd.storage.uid.width.metric # metric UID长度,默认3
tsd.storage.uid.width.tagk # tagK UID长度,默认3
tsd.storage.uid.width.tagv # tagV UID长度 默认3
# 这3者的UID分配分别是独立的空间注意:
集群已经写过数据后就无法修改,所以最好是一开始就确定好,建议4个字节。因为使用压缩技术后,RowKey多占的几个字节可以忽略,下文会提到。
salt
salt这个东西最好根据自己HBase集群规模去配置,它有2个配置:
tsd.storage.salt.width # 默认1,1基本够了,不用调整
tsd.storage.salt.buckets # 打散到几个bucket去,默认20查询的时候会并发 tsd.storage.salt.buckets 个Scanner到HBase上,所以如果这个配置太大,对查询影响比较大,容易打爆HBase。这里其实是一个权衡,写入热点和查询压力。默认20其实我个人觉得有点多,配置3~8就差不多了,当然实际效果还和metric设计有关,如果在一个metric里设计了很多时间线,那就得配置很多bucket。在一个metric中设计过多时间线,会影响OpenTSDB的查询效率,所以不建议这么做。
这个参数也是设置了就不能改的,所以也是要一开始规划好。
Column格式

这是列名(HBase中称为qualifier)的格式,可以看到毫米级需要多出2个字节。所以如果你的采集间隔不需要精确到毫秒级别,那请一定使用秒级(10位整数)。Value只能存储整数和浮点,所以有一个bit存储Float flag。
这里大家一定会有疑问,直接通过qualifier长度是4还是2不就能判断是秒级精度的数据点,还是毫秒了么?为何还需要MS flag这样一个标记信息?阅读下面的“压缩”部分,就能知道为什么。
OpenTSDB压缩问题
OpenTSDB有个很常见并且很麻烦的问题,就是整点时候对HBase对流量冲击。下面2张图是我们一个测试集群只做写入对效果:


可以看到会有一个数倍流量的爆发,要持续很久才能消化。这意味着我们需要更高规格去抗这个峰值。首先我们要明白OpenTSDB为啥要做压缩?在压缩些什么东西?
前面提到过OpenTSDB一行一小时的特点,那么一行里会有很多KV。表面上看起来好像没什么问题,但是实际上对比逻辑视图和物理视图你会发现一些问题。

很明显,每个KV都记录了rowX,那rowX就是一个空间浪费。这个空间不仅影响成本,还影响查询效率(毕竟数据多了)。压缩做的事情就是把多个小KV合成1个大KV,减少这部分浪费。所以压缩的时候会涉及到对HBase的“读-写-删”,这就是整点HBase IO流量的来源。
那么我们有没有办法,既做压缩,同时又消除这部分HBase IO呢?
当然有!我们可以把压缩的逻辑放到HBase内部去。因为HBase本身就需要对HFile做合并工作,这时候HBase本身就会读写数据文件,这部分对HDFS的IO不会少,而我们通过hook在HBase读出数据后,替换掉要写入的数据(即压缩好的数据)。

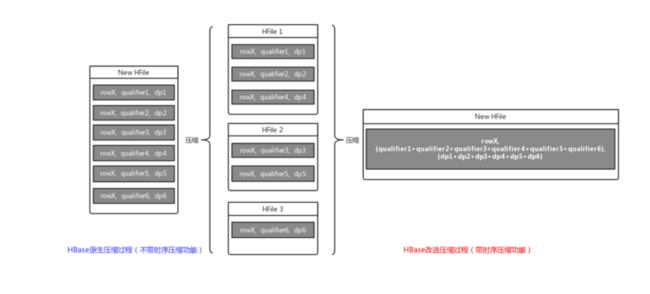
实现上面这个功能,当然需要一定内核开发量。好消息是通过云HBase购买页面购买的时序引擎,已经自带了上述功能。不管是分离部署模式,还是混合部署模式。
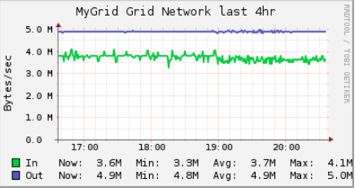
这个功能的好处显而易见,消除峰值节省成本,提升集群稳定性。这样我们对一个现有的HBase集群空闲资源需求就不是那么高了,完全可以复用了。下面是使用此功能后,同样只做写入的测试集群的流量情况:
本文作者:郭泽晖
本文为云栖社区原创内容,未经允许不得转载。