占小狼
转载请注明原创出处,谢谢!
数组动态扩容导致频繁FGC
关于数组动态扩容导致频繁GC的问题,笨神又写了一篇文章分析,当时因为没有仔细看,导致还有一些疑惑,于是把垃圾回收算法的实现重新看了一遍,不过每次看都会有不小的收获,所以源码不是读一遍就可以了,隔三差五的回头看看,说不定有些不懂的地方,在下一次的时候就豁朗了。
关于数组动态扩容导致频繁FGC,有兴趣的同学可以按下面的步骤动手实践一下,Java代码如下:
// jdk1.7 -Xmx500M -Xms500M -Xmn200M -XX:+UseConcMarkSweepGC
// -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=90
public class CrossReference {
private static int unit = 20 * 1024;
public static void main(String[] args) throws Exception{
Thread.sleep(5000);
System.out.println("allocate start************");
allocate();
Thread.sleep(1000);
System.out.println("allocate end************");
System.in.read();
}
private static void allocate() throws Exception{
int size = 1024 * 1024 * 400; // 400M
int len = size / unit;
List list = new ArrayList<>();
for(int i = 1; i <= len; i++){
BigObject bigObject = new BigObject();
list.add(bigObject);
Thread.sleep(1);
System.out.println(i);
}
}
private static class BigObject{
private byte[] foo;
BigObject(){
foo = new byte[unit];
}
}
}
通过jstat -gcutil 命令,可以展示堆内存的使用情况和GC触发情况。
1、JVM参数中没有-XX:+CMSScavengeBeforeRemark,jstat 结果如下:
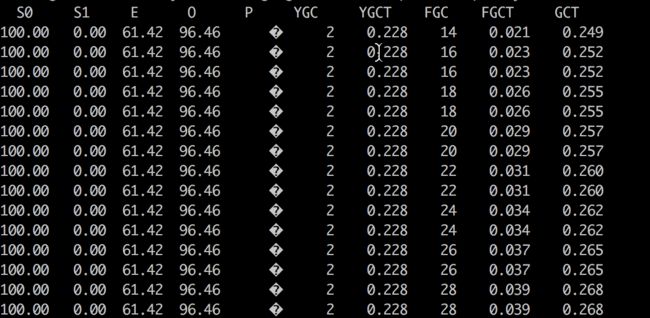
图中每个分代的数值代表内存使用率,可以看出发生FGC的时候,并没有触发YGC,所以老年代的对象一直回收不了,因为老年代进行GC时,会把新生代的对象作为GC root,在本场景中,新生代的对象不回收,老年代的对象也无法回收,而且老年代的内存使用率已经超过设置的阈值90%,所以会不断的进行FGC。
2、JVM参数中添加-XX:+CMSScavengeBeforeRemark,结果如下:
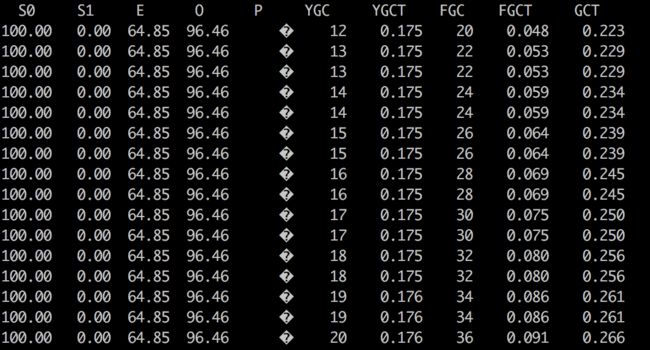
从上面的数据可以发现,发生FGC时,确实也触发了YGC,但是这次YGC并没有回收对象,导致了又不断的FGC,通过查看GC日志,可以发现也是在不断的打印GC信息,而且每次打印的数据(GC前的内存使用量和GC后的内存使用量)都是一样的。
现象描述如下:
allocate() 方法执行完成后
1.频繁CMS GC,但是old区仍然占用大,基本未回收空间
2.添加-XX:+CMSScavengeBeforeRemark参数,remark之前的一次ygc也未回收空间,old区情况同1
3.在Jprofiler中手动Run Full GC,young区,old区都被正常回收
4.若Arraylist初始化容量为它需要add的数量,则不存在上述现象
问题如下:
1.allocate() 方法执行完成后,堆中存在young-》old, old-》young的循环引用吗
2.添加-XX:+CMSScavengeBeforeRemark参数,为何仍然有问题,方法执行完后在Jprofiler中查看存活对象Arraylist已经没有,但是BigObject,byte[]仍然存在,占用约400M内存
3.手动Run Full GC为何就能正常回收?
为了解答这个问题,就得从Hotspot的实现源码入手,看看GC动作到底是什么样的过程,我们不妨可以假设一下,确实触发了YGC动作,然后记录了GC信息,但是因为某些原因并没有真正的执行YGC过程。
YGC实现过程
新生代内存分配失败触发YGC
如果是因为新生代内存分配失败触发YGC时,JVM内部对应会生成一个VM_GenCollectForAllocation对象,提交到一个执行队列中,最终会由VM Thread执行它的doit()方法,可以看一下doit方法
void VM_GenCollectForAllocation::doit() {
SvcGCMarker sgcm(SvcGCMarker::MINOR);
GenCollectedHeap* gch = GenCollectedHeap::heap();
GCCauseSetter gccs(gch, _gc_cause);
_res = gch->satisfy_failed_allocation(_size, _tlab);
assert(gch->is_in_reserved_or_null(_res), "result not in heap");
if (_res == NULL && GC_locker::is_active_and_needs_gc()) {
set_gc_locked();
}
}
这里需要关注的是satisfy_failed_allocation()方法,定义在GenCollectedHeap中
HeapWord* GenCollectedHeap::satisfy_failed_allocation(size_t size, bool is_tlab) {
return collector_policy()->satisfy_failed_allocation(size, is_tlab);
}
由垃圾回收策略决定执行satisfy_failed_allocation方法,实现如下
HeapWord* GenCollectorPolicy::satisfy_failed_allocation(size_t size,
bool is_tlab) {
GenCollectedHeap *gch = GenCollectedHeap::heap();
GCCauseSetter x(gch, GCCause::_allocation_failure);
HeapWord* result = NULL;
assert(size != 0, "Precondition violated");
if (GC_locker::is_active_and_needs_gc()) {
// GC locker is active; instead of a collection we will attempt
// to expand the heap, if there's room for expansion.
if (!gch->is_maximal_no_gc()) {
result = expand_heap_and_allocate(size, is_tlab);
}
return result; // could be null if we are out of space
} else if (!gch->incremental_collection_will_fail(false /* don't consult_young */)) {
// Do an incremental collection.
gch->do_collection(false /* full */,
false /* clear_all_soft_refs */,
size /* size */,
is_tlab /* is_tlab */,
number_of_generations() - 1 /* max_level */);
} else {
if (Verbose && PrintGCDetails) {
gclog_or_tty->print(" :: Trying full because partial may fail :: ");
}
// Try a full collection; see delta for bug id 6266275
// for the original code and why this has been simplified
// with from-space allocation criteria modified and
// such allocation moved out of the safepoint path.
gch->do_collection(true /* full */,
false /* clear_all_soft_refs */,
size /* size */,
is_tlab /* is_tlab */,
number_of_generations() - 1 /* max_level */);
}
...
1、如果GC_locker正在起作用,说明有线程正在通过JNI操作临界内存,那么就放弃GC动作,因为JNI操作完之后会可能会触发一次GC
2、如果上一次YGC是失败的,至于为什么上一次是失败的,可能是因为老年代没有足够的空间容纳新生代的对象,那么就不执行本次的YGC,直接进行FGC
不管是YGC还是FGC,都是通过执行GenCollectedHeap::do_collection()方法实现的,在该方法中会记录执行GC的日志,实现如下:
bool complete = full && (max_level == (n_gens()-1));
const char* gc_cause_prefix = complete ? "Full GC" : "GC";
TraceCPUTime tcpu(PrintGCDetails, true, gclog_or_tty);
GCTraceTime t(GCCauseString(gc_cause_prefix, gc_cause()), PrintGCDetails, false, NULL);
其中GCTraceTime实现中,会打印GC日志信息,而且这个时刻并未开始GC动作。
CTraceTime::GCTraceTime(const char* title, bool doit, bool print_cr, GCTimer* timer) :
_title(title), _doit(doit), _print_cr(print_cr), _timer(timer) {
if (_doit || _timer != NULL) {
_start_counter = os::elapsed_counter();
}
if (_timer != NULL) {
assert(SafepointSynchronize::is_at_safepoint(), "Tracing currently only supported at safepoints");
assert(Thread::current()->is_VM_thread(), "Tracing currently only supported from the VM thread");
_timer->register_gc_phase_start(title, _start_counter);
}
if (_doit) {
gclog_or_tty->date_stamp(PrintGCDateStamps);
gclog_or_tty->stamp(PrintGCTimeStamps);
gclog_or_tty->print("[%s", title);
gclog_or_tty->flush();
}
}
执行YGC的真正逻辑在parNewGeneration::collect()方法中,在方法中有这么一个判断逻辑:
// If the next generation is too full to accommodate worst-case promotion
// from this generation, pass on collection; let the next generation
// do it.
if (!collection_attempt_is_safe()) {
gch->set_incremental_collection_failed(); // slight lie, in that we did not even attempt one
return;
}
如果不满足collection_attempt_is_safe(),就直接返回,说明本次YGC是不安全的,不会真正执行本次的垃圾回收,那什么情况算是不安全的呢?collection_attempt_is_safe()实现如下:
bool DefNewGeneration::collection_attempt_is_safe() {
if (!to()->is_empty()) {
if (Verbose && PrintGCDetails) {
gclog_or_tty->print(" :: to is not empty :: ");
}
return false;
}
if (_next_gen == NULL) {
GenCollectedHeap* gch = GenCollectedHeap::heap();
_next_gen = gch->next_gen(this);
assert(_next_gen != NULL,
"This must be the youngest gen, and not the only gen");
}
return _next_gen->promotion_attempt_is_safe(used());
}
1、to空间不为空
2、没有下一个内存代,即没有老年代
3、其中情况1和2几乎不会发生,主要还是看这种情况,主要看老年代是否有足够的空间来容纳新生代的对象,老年代的promotion_attempt_is_safe()的实现如下:
bool ConcurrentMarkSweepGeneration::promotion_attempt_is_safe(size_t max_promotion_in_bytes) const {
size_t available = max_available();
size_t av_promo = (size_t)gc_stats()->avg_promoted()->padded_average();
bool res = (available >= av_promo) || (available >= max_promotion_in_bytes);
if (Verbose && PrintGCDetails) {
gclog_or_tty->print_cr(
"CMS: promo attempt is%s safe: available("SIZE_FORMAT") %s av_promo("SIZE_FORMAT"),"
"max_promo("SIZE_FORMAT")",
res? "":" not", available, res? ">=":"<",
av_promo, max_promotion_in_bytes);
}
return res;
}
如果老年代中的可用空间大于gc_stats统计的新生代每次平均晋升的对象大小,或者可以容纳目前新生代所有的对象,表明可以执行正常的YGC动作,如果都不满足,就直接放弃本次YGC。
由FGC触发的YGC
在JVM参数中添加-XX:+CMSScavengeBeforeRemark,执行FGC之前会触发一次YGC,这个参数的好处是如果YGC比较有效果的话是能有效降低remark的时间长度,可以简单理解为如果大部分新生代的对象被回收了,那么GC root变少了,从而提高了remark的效率。
因为CMS是多线程执行的,主要的执行入口定义在ConcurrentMarkSweepThread::run()方法,ConcurrentMarkSweepThread相当于继承了Java中的Thread的一个类,在run方法执行实现具体逻辑,下面是CMS执行过程的简要分析。
1、run方法中调用CMSCollector::collect_in_background方法,在该方法中,会根据当前CMS的执行状态,初始化对应的 VM_CMS_Operation,本文是分析CMSScavengeBeforeRemark,该变量所用到的逻辑中对用的状态为 VM_CMS_Final_Remark,该状态是CMS中再次标记阶段。
2、初始化 VM_CMS_Final_Remark,并提交到VM Thread的执行队列中,等待被执行,最终由VM Thread执行它的doit方法,这方式和执行YGC时类似
3、在VM_CMS_Final_Remark::doit()方法中调用_collector->do_CMS_operation();,最终调用CMSCollector::checkpointRootsFinal()方法,其中和CMSScavengeBeforeRemark相关的代码实现如下:
if (CMSScavengeBeforeRemark) {
GenCollectedHeap* gch = GenCollectedHeap::heap();
// Temporarily set flag to false, GCH->do_collection will
// expect it to be false and set to true
FlagSetting fl(gch->_is_gc_active, false);
NOT_PRODUCT(GCTraceTime t("Scavenge-Before-Remark",
PrintGCDetails && Verbose, true, _gc_timer_cm);)
int level = _cmsGen->level() - 1;
if (level >= 0) {
gch->do_collection(true, // full (i.e. force, see below)
false, // !clear_all_soft_refs
0, // size
false, // is_tlab
level // max_level
);
}
}
这里又回到了GenCollectedHeap::do_collection()方法,具体过程和新生代内存分配失败触发YGC的情况一样。
另外手动执行Run Full GC和执行jmap -histo:live
参考资料:
假笨说-关于数组动态扩容导致频繁GC的问题,我还有话说