
1.1 API 分析
网易云音乐的评论区一直为人们所津津乐道,不少人因其优质的评论被圈粉。近日看到篇通过 SnowNLP 对爬取的云音乐评论进行情感分析的文章,便乘此研究下如何爬取云音乐评论并对其进行情感分析。
首先,通过浏览器的开发者工具观察云音乐歌曲评论的页面请求,发现评论是通过 Ajax 来传输的,其 POST 请求的 params 和 enSecKey 参数是经过加密处理的,这问题已有人给出了解决办法。但在前面提到的那篇文章里,发现了云音乐未被加密的 API(=。=):
http://music.163.com/api/v1/resource/comments/R_SO_4_5279713?limit=20&offset=0
在该 URL 中,R_SO_4_ 后的那串数字是歌曲的 id,而 limit 和 offset 分别是分页的每页记录数和偏移量。但有了这个 API 还不够,还需要获取歌曲列表的 API,否则得手动查找和输入歌曲 id。然后又十分愉快地,找到了搜索的 API:
http://music.163.com/api/search/get/web?csrf_token=&hlpretag=&hlposttag=&s=%E7%AA%A6%E5%94%AF&type=1&offset=0&total=true&limit=
这条 URL,s= 后面的是搜索条件,type 则对应的是搜索结果的类型(1=单曲, 10=专辑, 100=歌手, 1000=歌单, 1006=歌词, 1014=视频, 1009=主播电台, 1002=用户)。
有了这两个 API,就可以开始编写爬虫了。
Warning:
本文代码基于 Win10 + Py3.7 环境,由于为一次性需求,且对数据量估计不足(实际爬取近 16w 条),未过多考虑效率和异常处理问题,仅供参考。
1.2 爬虫
按照惯例,首先导入爬虫的相关库。
import requests
import re
import urllib
import math
import time
import random
import pandas as pd
import sqlite3
构造请求头。
my_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
接下来构建了 6 个用于爬虫的函数:
-
getJSON(url, headers): 从目标 URL 获取 JSON -
countPages(total, limit): 根据记录总数计算要抓取的页数 -
parseSongInfo(song_list): 解析歌曲信息 -
getSongList(key, limit=30): 获取歌曲列表 -
parseComment(comments): 解析评论 -
getSongComment(id, limit=20): 获取歌曲评论
def getJSON(url, headers):
""" Get JSON from the destination URL
@ param url: destination url, str
@ param headers: request headers, dict
@ return json: result, json
"""
res = requests.get(url, headers=headers)
res.raise_for_status() #抛出异常
res.encoding = 'utf-8'
json = res.json()
return json
def countPages(total, limit):
""" Count pages
@ param total: total num of records, int
@ param limit: limit per page, int
@ return page: num of pages, int
"""
page = math.ceil(total/limit)
return page
def parseSongInfo(song_list):
""" Parse song info
@ param song_list: list of songs, list
@ return song_info_list: result, list
"""
song_info_list = []
for song in song_list:
song_info = []
song_info.append(song['id'])
song_info.append(song['name'])
artists_name = ''
artists = song['artists']
for artist in artists:
artists_name += artist['name'] + ','
song_info.append(artists_name)
song_info.append(song['album']['name'])
song_info.append(song['album']['id'])
song_info.append(song['duration'])
song_info_list.append(song_info)
return song_info_list
def getSongList(key, limit=30):
""" Get a list of songs
@ param key: key word, str
@ param limit: limit per page, int, default 30
@ return result: result, DataFrame
"""
total_list = []
key = urllib.parse.quote(key) #url编码
url = 'http://music.163.com/api/search/get/web?csrf_token=&hlpretag=&hlposttag=&s=' + key + '&type=1&offset=0&total=true&limit='
# 获取总页数
first_page = getJSON(url, my_headers)
song_count = first_page['result']['songCount']
page_num = countPages(song_count, limit)
# 爬取所有符合条件的记录
for n in range(page_num):
url = 'http://music.163.com/api/search/get/web?csrf_token=&hlpretag=&hlposttag=&s=' + key + '&type=1&offset=' + str(n*limit) + '&total=true&limit=' + str(limit)
tmp = getJSON(url, my_headers)
song_list = parseSongInfo(tmp['result']['songs'])
total_list += song_list
print('第 {0}/{1} 页爬取完成'.format(n+1, page_num))
time.sleep(random.randint(2, 4))
df = pd.DataFrame(data = total_list, columns=['song_id', 'song_name', 'artists', 'album_name', 'album_id', 'duration'])
return df
def parseComment(comments):
""" Parse song comment
@ param comments: list of comments, list
@ return comments_list: result, list
"""
comments_list = []
for comment in comments:
comment_info = []
comment_info.append(comment['commentId'])
comment_info.append(comment['user']['userId'])
comment_info.append(comment['user']['nickname'])
comment_info.append(comment['user']['avatarUrl'])
comment_info.append(comment['content'])
comment_info.append(comment['likedCount'])
comments_list.append(comment_info)
return comments_list
def getSongComment(id, limit=20):
""" Get Song Comments
@ param id: song id, int
@ param limit: limit per page, int, default 20
@ return result: result, DataFrame
"""
total_comment = []
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_' + str(id) + '?limit=20&offset=0'
# 获取总页数
first_page = getJSON(url, my_headers)
total = first_page['total']
page_num = countPages(total, limit)
# 爬取该首歌曲下的所有评论
for n in range(page_num):
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_' + str(id) + '?limit=' + str(limit) + '&offset=' + str(n*limit)
tmp = getJSON(url, my_headers)
comment_list = parseComment(tmp['comments'])
total_comment += comment_list
print('第 {0}/{1} 页爬取完成'.format(n+1, page_num))
time.sleep(random.randint(2, 4))
df = pd.DataFrame(data = total_comment, columns=['comment_id', 'user_id', 'user_nickname', 'user_avatar', 'content', 'likeCount'])
df['song_id'] = str(id) #添加 song_id 列
return df
在爬取数据前,先连接上数据库。
conn = sqlite3.connect('netease_cloud_music.db')
设置搜索条件,并爬取符合搜索条件的记录。
artist='窦唯' #设置搜索条件
song_df = getSongList(artist, 100)
song_df = song_df[song_df['artists'].str.contains(artist)] #筛选记录
song_df.drop_duplicates(subset=['song_id'], keep='first', inplace=True) #去重
song_df.to_sql(name='song', con=conn, if_exists='append', index=False)
从数据库中读取所有 artists 包含 窦唯 的歌曲,这将得到 song_id 数据框。
sql = '''
SELECT song_id
FROM song
WHERE artists LIKE '%窦唯%'
'''
song_id = pd.read_sql(sql, con=conn)
爬取 song_id 数据框中所有歌曲的评论,并保存到数据库。
comment_df = pd.DataFrame()
for index, id in zip(song_id.index, song_id['song_id']):
print('开始爬取第 {0}/{1} 首, {2}'.format(index+1, len(song_id['song_id']), id))
tmp_df = getSongComment(id, 100)
comment_df = pd.concat([comment_df, tmp_df])
comment_df.drop_duplicates(subset=['comment_id'], keep='first', inplace=True)
comment_df.to_sql(name='comment', con=conn, if_exists='append', index=False)
print('已成功保存至数据库!')
完成上述所有步骤后,数据库将增加近 16w 条记录。
1.3 数据概览
从数据库中读取所有 artists 包含 窦唯 的评论,得到 comment 数据框。
sql = '''
SELECT *
FROM comment
WHERE song_id IN (
SELECT song_id
FROM song
WHERE artists LIKE '%窦唯%'
)
'''
comment = pd.read_sql(sql, con=conn)
通过 nunique() 方法可得到 comment 中各字段分别有多少个不同值。从中可以看出,一共有来自 70254 名用户的 159232 条评论。
comment.nunique()
comment_id 159232
user_id 70254
user_nickname 68798
user_avatar 80094
content 136898
likeCount 616
song_id 445
dtype: int64
接下来分别查看评论数、评论次数、点赞数前 10 的歌曲、用户和评论
song_top10_num = comment.groupby('song_id').size().sort_values(ascending=False)[0:10]
song_top10 = song[song['song_id'].isin(song_top10_num.index)].iloc[:, 0:2]
song_top10['num'] = song_top10_num.tolist()
print(song_top10)
| index | song_id | song_name | num |
|---|---|---|---|
| 0 | 5279713 | 高级动物 | 11722 |
| 4 | 5279715 | 悲伤的梦 | 9316 |
| 5 | 77169 | 暮春秋色 | 7464 |
| 8 | 5279714 | 噢 乖 | 6477 |
| 13 | 526468453 | 送别2017 | 5605 |
| 28 | 512298988 | 重返魔域 | 4677 |
| 124 | 27853979 | 殃金咒 | 4493 |
| 327 | 26031014 | 雨吁 | 3965 |
| 377 | 34248413 | 既然我们是兄弟 | 3845 |
| 435 | 28465036 | 天宫图 | 3739 |
user_top10 = comment.groupby('user_id').size().sort_values(ascending=False)[0:10]
print(user_top10)
| user_id | comments |
|---|---|
| 42830600 | 549 |
| 33712056 | 322 |
| 51625217 | 273 |
| 284151966 | 242 |
| 2159884 | 234 |
| 271253793 | 234 |
| 388206024 | 233 |
| 263344124 | 232 |
| 84030184 | 209 |
| 131005965 | 204 |
comment_top10 = comment.sort_values(['likeCount'], ascending=False)[0:10]
print(comment_top10[['comment_id', 'likeCount']])
| index | comment_id | likeCount |
|---|---|---|
| 11252 | 51694054 | 35285 |
| 10522 | 133265373 | 15409 |
| 10211 | 148045985 | 12886 |
| 146129 | 40249220 | 9234 |
| 10038 | 157500246 | 7670 |
| 38728 | 6107434 | 7393 |
| 48826 | 658314395 | 5559 |
| 31101 | 7875585 | 5248 |
| 146213 | 35287069 | 4900 |
| 37307 | 231408710 | 4801 |
1.4 情感分析
导入情感分析及可视化的相关库。
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
import jieba
from snownlp import SnowNLP
from wordcloud import WordCloud
这里使用 SnowNLP 进行情感分析,SnowNLP 是一个用于处理中文文本的自然语言处理库,可以很方便地进行中文文本的情感分析(”现在训练数据主要是买卖东西时的评价,所以对其他的一些可能效果不是很好,待解决“),试举一例:
test = '窦唯只要出来把自己的老作品演绎一遍,就能日进斗金,可人家没这么干!人家还在自己坐着地铁!什么是人民艺术家?这就是!!'
c = SnowNLP(test)
c.sentiments
# 0.9988789161400798
得分在 [0, 1] 区间内,越接近 1 则情感越积极,反之则越消极。一般来说,得分大于 0.5 的归于正向情感,小于的归于负向。下面为 comment 增加两列,分别是评论内容的情感得分和正负向标签(1=正向,-1=负向)。
comment['semiscore'] = comment['content'].apply(lambda x: SnowNLP(x).sentiments)
comment['semilabel'] = comment['semiscore'].apply(lambda x: 1 if x > 0.5 else -1)
基于评论内容的情感得分,得到下方的直方图,从图中不难看出,对窦唯音乐的评论多是积极正面的:
plt.hist(comment['semiscore'], bins=np.arange(0, 1.01, 0.01), label='semisocre', color='#1890FF')
plt.xlabel("semiscore")
plt.ylabel("number")
plt.title("The semi-score of comment")
plt.show()
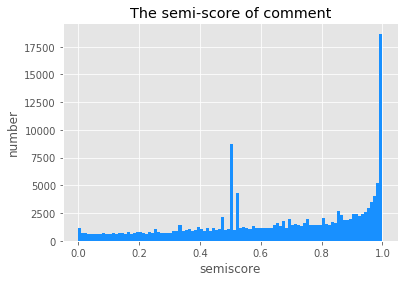
再通过情感标签观察,可知持正向情感的评论数是负向情感的近两倍。
semilabel = comment['semilabel'].value_counts()
semilabel = semilabel.loc[[1, -1]]
plt.bar(semilabel.index, semilabel.values, tick_label=semilabel.index, color='#2FC25B')
plt.xlabel("semislabel")
plt.ylabel("number")
plt.title("The semi-label of comment")
plt.show()

1.5 词云
最后,使用 jieba 进行中文分词(关于 jieba,可参阅简明 jieba 中文分词教程),并绘制词云图:
text = ''.join(str(s) for s in comment['content'] if s not in [None]) #将所有评论合并为一个长文本
jieba.add_word('窦唯') #增加自定义词语
word_list = jieba.cut(text, cut_all=False) #分词
stopwords = [line.strip() for line in open('stopwords.txt',encoding='UTF-8').readlines()] #加载停用词列表
clean_list = [seg for seg in word_list if seg not in stopwords] #去除停用词
# 生成词云
cloud = WordCloud(
font_path = 'F:\fonts\FZBYSK.TTF',
background_color = 'white',
max_words = 1000,
max_font_size = 64
)
word_cloud = cloud.generate(clean_text)
# 绘制词云
plt.figure(figsize=(16, 16))
plt.imshow(word_cloud)
plt.axis('off')
plt.show()

在生成的词云图中(混入了一个 、、、、,可能是特殊字符的问题),最显眼的是窦唯高级动物的歌词,结合高达 11722 的评论数,不难看出人们对这首歌的喜爱。其次是 喜欢, 听不懂, 好听 等词语,在一定程度上体现了人们对窦唯音乐的评价。再基于 TF-IDF 算法对评论进行关键词提取,得出前 30 的关键词:
for x, w in anls.extract_tags(clean_text, topK=30, withWeight=True):
print('{0}: {1}'.format(x, w))
喜欢: 0.07174921826661623
摇滚: 0.06222465433996381
好听: 0.048331581166697744
仙儿: 0.04814604948274102
王菲: 0.04271112348151552
窦仙: 0.027324893954643947
听不懂: 0.01956956751188709
幸福: 0.014775956892430308
成仙: 0.01465450183828875
汪峰: 0.014175488038594907
大仙: 0.013705819518861267
高级: 0.013225888298888759
黑梦: 0.013076421076696725
前奏: 0.012872688959687885
黑豹: 0.012540924545728218
听歌: 0.012455923064269991
艳阳天: 0.012455923064269991
动物: 0.012396754282072616
听听: 0.012369319024839337
听懂: 0.01160376390830011
吉他: 0.01142745810497296
忘词: 0.011296092030755316
歌曲: 0.011181124179616048
希望: 0.01089713506654457
理解: 0.010537493766491456
厉害: 0.0104225740491279
哀伤: 0.009602942087618863
窦靖童: 0.009406198340815812
电影: 0.009266377909595709
送别: 0.008950847971089923
排在前面的关键词有“喜欢、摇滚、好听、听不懂”等,还出现了 3 个人名,分别是窦唯的前妻、女儿以及另一位中国摇滚代表人物。一些歌名(如“高级动物”)、专辑名(如“黑梦”)也出现在这列表中,可惜的是窦唯后来的作品并没有出现(和“听不懂”多少有点关系)。而带“仙”字的关键词有 4 个,“窦唯成仙了”。最有意思的彩蛋,莫过于"忘词"这个关键词,看样子大家对窦唯在 94 年那场演唱会的忘词,还是记忆犹新。