1.python字符串相关操作
s1 = " hello " s2 = " world! " #去除字符串左右两边的空格 s1 = s1.strip() s2 = s2.strip() #拼接字符串 s = s1+s2 #查找字符或子串 s_index = s.index('hello') #字符串大小写转换 s3 = "ABC" s4 = "abc" s3_lower = s3.lower() s4_upper = s4.upper() #翻转字符串 s_reverse = s[::-1] #查找字符串 s_find = s.find("hello") #分割字符串 s5 = "a,b,c,d,e" s5_split = s5.split(",")
import re from collections import Counter #获取字符串中出现最多次数的字符 def count_char(str): str = str.lower() res = re.findall("[a-z]",str) count = Counter(res) return [k for k,v in count.items() if v==max(list(count.values()))]
2.正则表达式(网上很多教程,关键还是理解每一个代表什么意思,还要多写,其实没什么大不了,这里就不写了)就只写写python中是怎么用的
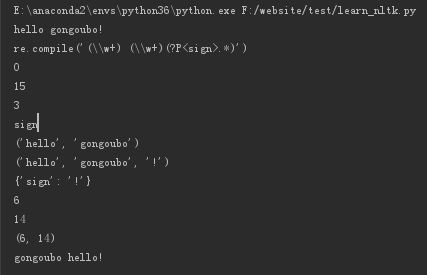
import re #compile传入两个参数,第一个是pattern,第二个是flag(这个根据实际情况使用) pattern = re.compile(r"(\w+) (\w+)(?P.*) ") match = pattern.match("hello gongoubo!") if match: #匹配时使用的文本 print(match.string) #匹配时使用的pattern对象 print(match.re) #开始搜索的索引 print(match.pos) #结束搜索的索引 print(match.endpos) #最后一个分组的索引 print(match.lastindex) #最后一个分组别名 print(match.lastgroup) print(match.group(1,2)) print(match.groups()) print(match.groupdict()) print(match.start(2)) print(match.end(2)) print(match.span(2)) print(match.expand(r'\2 \1\3'))
(1)进行制定的切分
import re pattern = re.compile(r"\d+") print(pattern.split("one1two2three3four4"))

(2)返回全部匹配的字符串
import re pattern = re.compile(r"\d+") print(pattern.findall("one1two2three3four4"))
(3)替换掉符合某种模式的字符串
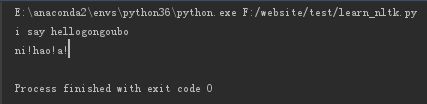
import re pattern1 = re.compile(r"(\w+) (\w+)") pattern2 =re.compile(r' ') s1="say i hellogongoubo" s2="ni hao a " print(pattern1.sub(r'\2 \1',s1)) print(pattern2.sub(r'!',s2))
3.jieba中文处理
import jieba #全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但不能解决歧义; seg_list= jieba.cut("我爱学习自然语言处理",cut_all=True,HMM=False) print("Full Mode:"+"/".join(seg_list)) #精确模式,如不指定,默认是这个模式,适合文本分析; seg_list= jieba.cut("我爱学习自然语言处理",cut_all=False,HMM=False) print("Full Mode:"+"/".join(seg_list)) #搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率 seg_list=jieba.cut_for_search("小明硕士毕业于中国科学技术学院计算所,后在哈佛大学深造") print("Full Mode:"+"/".join(seg_list)) #lcut,lcut_for_search返回的是列表 seg_list= jieba.lcut("我爱学习自然语言处理",cut_all=True) print(seg_list)

(1)添加用户自定义词典:
1)可以利用jieba.load_userdict(file_name)加载用户字典;
2)少量词汇可以手动添加:
- add_word(word,freq=None,lag=None)和del_word(word)在程序中动态修改字典,这时HMM要设置为False
- 用suggest_freq(segment,tune=True)可调节单个词语的词频,使其能(或不能)被分出来
import jieba seg_list= jieba.cut("如果放在旧字典中将出错",cut_all=False,HMM=False) print(','.join(seg_list)) jieba.suggest_freq(("中","将"),tune=True) seg_list= jieba.cut("如果放在旧字典中将出错",cut_all=False,HMM=False) print(','.join(seg_list))
![]()
会发现"中将"被拆为"中"和"将"了。
(2)基于TF-IDF算法的关键词提取
jieba.analyse.extract_tags(sentense,topK=20,withWeight=False,allowPOS=())
sentense:待提取的文本
topK:返回权重较大的前多少个关键词
withWeight:是否一并返回权重值,默认为False
allowPOS:仅保留指定词性的词,默认为空
from jieba import analyse text = "Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言," \ "最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加," \ "越来越多被用于独立的、大型项目的开发。" print(" ".join(analyse.extract_tags(text)))
![]()
注意:关键词提取所使用的的逆文档频率(IDF)文本语料库可以切换成自定义语料库的路径:
jieba.analyse.set_idf_path(file_name)
关键词提取所使用的停止词文本语料库也可以切换成自定义语料库的路径:
jieba.analyse.set_stop_words(file_name)
(2)基于TextRank算法的关键词提取
jieba.analyse.textrank(sentense,topK=20,withWeight=False,allowPOS=('ns','n','vn','v'))
基本思想:
- 将待提取的关键词进行文本分词;
- 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图;
- 计算图中节点的PageRank;(无向带权图)
from jieba import analyse text = "Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言," \ "最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加," \ "越来越多被用于独立的、大型项目的开发。" print(" ".join(analyse.textrank(text)))
![]()
(3)词性标注
jieba.posseg.POSTTokenizer(tokenizer=None)新建自定义分词器,tokenizer参数可指定内部使用的jieba.Tokenizer分词器。jieba.prosseg.dt默认词性标注分词器;
标注句子分词后每个词的词性,采用和ictclas兼容的标记法;
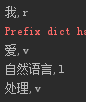
from jieba import posseg text = "我爱自然语言处理" words = posseg.cut(text) for word, flag in words: print("{},{}".format(word,flag))
(4)并行分词
jieba.enable_parallel()
import jieba import time content=open(u'遮天.txt').read() def en_parallel(content): jieba.enable_parallel() t1=time.time() words = "/".join(jieba.cut(content)) t2=time.time() tm_cost=t2-t1 print("并行分词速度为{} bytes/second".format(len(content)/tm_cost)) def dis_parallel(content): jieba.disable_parallel() t1=time.time() words = "/".join(jieba.cut(content)) t2=time.time() tm_cost=t2-t1 print("非并行分词速度为{} bytes/second".format(len(content)/tm_cost))
![]()
在windows环境下会报错,由于没有Linux系统就不试了
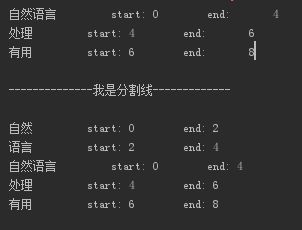
(5)Tokenize:返回词语在原文的起止位置
import jieba #默认模式 result=jieba.tokenize(u'自然语言处理有用') for tk in result: print("%s\t\t start: %d \t\t end: %d" % (tk[0],tk[1],tk[2])) #搜索模式 result=jieba.tokenize(u'自然语言处理有用',mode='search') for tk in result: print("%s\t\t start: %d \t\t end: %d" % (tk[0],tk[1],tk[2]))