论文解读:Pedro Domingos技术论文:机器学习中一些有用的知识

机器学习算法可以通过从数据中归纳出如何执行类似任务的方法。在手动编程不适用的情况下,这通常是可行的并且非常划算。随着更多数据的可用,越来越多的问题可以得到解决。
机器学习算法可以通过从数据中归纳出如何执行类似任务的方法。在手动编程不适用的情况下,这通常是可行的并且非常划算。随着更多数据的可用,越来越多的问题可以得到解决。因此,机器学习正在被广泛应用于计算机等领域。然而,开发一个成功的机器学习应用程序需要大量难以在教科书中找到的“黑色艺术(black art)”。
我最近读了华盛顿大学Pedro Domingos教授的一篇技术论文,题为“机器学习的一些有用的知识”,它总结了机器学习研究人员和从业人员需要记住的12个关键经验教训,包括避免陷阱(pitfalls to avoid)、重点问题以及常见问题的答案。我想在本文中分享这些经验教训,因为在考虑解决一个机器学习问题时,它们是非常有用。
论文地址:https://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf
1:学习=表征(Representation)+评估+优化
所有机器学习算法通常由以下3个组件组成:
· 表征(Representation):分类器必须用计算机可以处理的一些语言来表示。相反,为学习者选择一种表示方式等于选择它可能学习的一组分类器。这个集合称为学习者的假设空间。如果分类器不在假设空间中,则无法学习。一个相关的问题是如何表示输入,即使用哪些功能。
· 评估:需要一个评估函数来区分分类器的好坏。算法内部使用的评估函数可能不同于我们希望分类器优化的外部评估函数。
· 优化:最后,我们需要一种方法在语言中的分类器中搜索得分最高的分类器。优化技术的选择对于学习者的效率至关重要,并且还有助于确定评估函数具有多于一个最佳值时产生的分类器。新学习者开始使用现成的优化器(后来由定制设计替代)是很常见的。
2:机器学习要以预测训练集之外的数据为目的(It’s Generalization that Counts)
机器学习的基本目标是推广超出了训练集中的例子。这是因为,无论我们有多少数据,我们都不太可能在测试时再次看到这些确切的示例。训练集是很容易制作的。机器学习初学者最常犯的错误是测试训练数据,并有成功的幻觉。如果选择的分类器在随后的新数据上进行测试,那么通常不会比随机猜测更好。因此,如果聘请某人构建机器学习模型,请务必保留一些数据给自己,并测试他们提供的分类器。相反,如果被聘为构建机器学习模型,请将其中的一些数据设置为一开始,并仅在最后测试选择的分类器,然后在整个数据中训练处最好的模型。

3:没有足够的数据
这似乎是一个令人沮丧的消息。幸运的是,我们想要从现实世界中学习的模型并不是完全要遵循数学的精准性!事实上,非常普遍的假设:如平滑性、类似的例子、有限的依赖性或有限的复杂性,通常足以做得很好,这是机器学习如此成功的很大一部分原因。就像演绎一样,归纳(学习者所做的)就是知识杠杆:它将少量的输入知识转化为大量的输出知识。归纳法是一种比演绎更加强大的杠杆,需要更少的输入知识来产生有用的结果,但它仍然需要输入知识才能工作。而且,就像任何杠杆一样,我们投入的越多,收获的也就越多。
现在想想,学习知识的所需的数据不应该令人惊讶。机器学习不是魔术,它无法从无到有。它现在所做的是从更少获得更多。像所有工程一样,编程有很多工作:我们必须从头开始构建所有的东西。学习更像是农业,让大自然完成大部分的工作。农民将种子与营养物质结合起来种植作物,类似训练者将知识与数据结合起来发展项目。
4:过度拟合有很多处理方式
如果我们拥有的知识和数据不足以完全确定正确的分类器,该怎么办?我们冒着对分类器(或其中的一部分)产生幻觉的风险,这些分类器没有基于现实,并且只是编码数据中的随机怪癖,这个问题被称为过度拟合,是机器学习的怪症。当学习者输出的分类器对训练数据100%准确,但对测试数据的准确率只有50%时,实际上它已经是过度拟合了。
机器学习中的每个人都知道过度拟合,但它有很多形式,并不是很明显。了解过度拟合的一种方法是将泛化误差分解为偏差和方差。偏差是学习者倾向于始终学习相同的错误。无论真实信号如何,方差都倾向于学习随机事物。线性学习者通常有很高的偏差,因为当两个类之间的边界不是超平面时,学习者无法处理它。决策树不存在这个问题,因为它们可以表示任何布尔函数,但是另一方面,他们可能会产生很高的方差:在同一个现象产生的不同训练集上学习的决策树往往是非常不同的,但实际上应该是一样的。
交叉验证可以帮助对抗过度拟合,例如通过使用它来选择决策树的最佳大小。但它不是万能的,因为如果我们用它来做太多的参数选择,它本身就会开始过度拟合。
除了交叉验证之外,还有很多方法可以解决过度拟合的问题。最流行的是添加正则化术语到评估功能。例如,这可以惩罚具有更多结构的分类器,从而有利于较少结构的分类器。另一种选择是在添加新结构之前,执行像卡方这样的统计显着性检验,以确定该类别的分布在具有和不具有该结构的情况下是否真的不同。当数据非常少时,这些技术特别有用。尽管如此,你应该对某种技术“解决”过度拟合问题的说法持怀疑态度,因为没有任何一种技术总能做到最好(没有免费的午餐)。
5:直觉错误——高维度
过度拟合之后,机器学习中最大的问题就是维度的诅咒。这个话题是由Bellman在1961年提出的,指的是许多在低维度下工作正常的算法在输入是高维时就变得棘手。但在机器学习中,它指的是随着示例的维数(特征数量)增加,泛化正确地变得越来越难,因为固定大小的训练集只覆盖了输入空间的一小部分。
高维度的一般问题是我们的直觉来自三维世界,通常不适用于高维空间。在高维度中,多元高斯分布的大部分质量并不接近平均值,而是在其周围越来越远的“壳”中。如果恒定数量的示例在高维超立方体中均匀分布,超出某些维度,则大多数示例更接近超立方体的面,而不是最近邻居。如果我们通过将超球体写入超立方体来近似超球体,那么在高维中几乎所有超立方体的体积都在超球体的外面。这对于机器学习来说是个坏消息,其中一种类型的形状经常通过另一种形状来近似。
在二维或三维中构建分类器非常简单,我们可以通过视觉检查在不同类别的例子之间找到合理的边界。但是在高维度上,我们很难理解正在发生的事情。这反过来又使设计好的分类器变得困难。天真地说,人们可能会认为聚集更多的功能不会受到损失,因为在最糟糕的情况下,它们不会提供关于该类的新信息 但实际上,维度的诅咒可能会超过它们的好处。
6:理论保证不是他们所看到的
机器学习论文充满了理论保证。最常见的类型是确保良好泛化所需的示例数量的界限。你应该怎样做到这些保证?首先,它们甚至可能是非常了不起的,归纳传统上与扣除形成对比:在推论中,你可以保证结论是正确的;在归纳中,所有判断都社区。近几十年来的一个主要发展是认识到,我们可以对归纳结果保证,特别是如果我们愿意解决概率保证。
我们必须小心这种约束是什么意思。例如,如果你的模型返回了一个与特定训练集相一致的假设,那么这个假设可能概括得很好。所谓的是,如果给定足够大的训练集,那么你的模型要么返回一个推广的假设,要么找不到一致的假设。界限也没有说如何选择一个好的假设空间。它只告诉我们,如果假设空间包含真实的分类器,那么训练处输出不好的分类器的概率是随着训练集大小而减少。如果我们缩小假设空间,边界就会改善,但是包含真实分类器的机会也会缩小。
另一种常见的理论保证类型是渐近的:给定无限的数据,训练模型的人保证输出正确的分类器。在实践中,我们很少处于渐近状态(也称为“asymptopia”)。而且,由于上面讨论的偏差-方差权衡,如果学习者A在给定无限数据的情况下比学习者B好,则B通常比给定有限数据的A好。
理论保证在机器学习中的主要作用不是作为实际决策的标准,而是作为理解和推动算法设计的源泉。事实上,理论与实践的密切相互作用是机器学习多年来取得如此巨大进步的主要原因之一。但要注意:训练是一个复杂的现象。
7:特征工程是关键
有些机器学习项目成功了,有些失败了,到底什么在其中起到关键作用?最容易使用的特征是最重要的因素。如果你有许多独立的特征,每个特征都与类相关联,学习是很容易。另一方面,如果这个类是一个非常复杂的特征,你可能无法学习它。通常情况下,原始数据不是可以学习的形式,但是可以从中构建特征。这通常是机器学习项目中的大部分工作所在,它通常也是最有趣的部分之一,其中直觉、创造力和“黑色艺术”与技术材料一样重要。
初学者常常惊讶于机器学习项目实际进行机器学习的时间太少。但是,如果考虑收集数据,整合数据,清理数据并对数据进行预处理以及进行特征设计的尝试和错误可能会花费多少时间,你会发现这些才是真正费时间的。此外,机器学习不是建立数据集和运行模型的一步式过程,而是运行模型、分析结果、修改数据或模型并重复的迭代过程。训练通常是最快速的部分,但那是因为我们已经掌握了很好的技巧!特征工程是最困难的,因为它是特定领域的,而训练是通用标准执行的。但是,两者之间没有明显的边界。
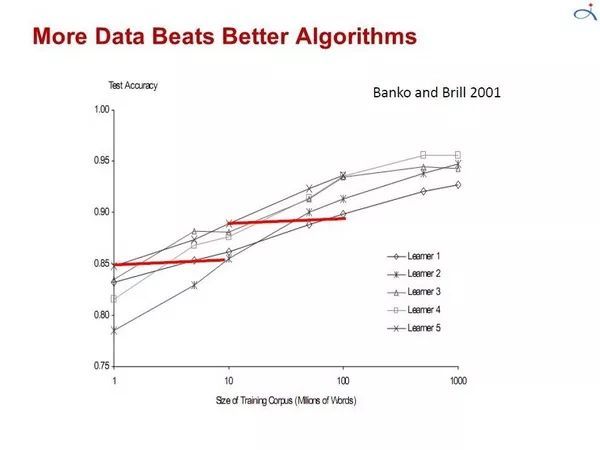
8:更多数据击败更聪明的算法
在大多数计算机科学中,这两种主要的有限资源是时间和记忆。在机器学习中,还有第三个:训练数据。在20世纪80年代,数据是稀缺的。今天往往是时间是宝贵的。大量的数据是可用的,但没有足够的时间来处理它,所以它没有被使用。这导致了一个矛盾:尽管原则上更多的数据意味着可以学习更复杂的分类器,但在实践中是更简单的分类器被使用,因为复杂的分类器学习时间过长。今天所有的研究者都想找到快速训练复杂分类器的方法,而且在这方面确实取得了显着的进展。
部分原因是使用更聪明的算法。所有学习者本质上都是通过将附近的例子分组到同一个类来工作的,关键的区别在于“附近”。由于数据分布不均匀,训练可以产生广泛不同的边界,同时在重要的区域仍然做出相同的预测(具有大量训练实例的那些预测),大多数文本示例可能会出现。
通常,首先尝试最简单的训练(例如,逻辑回归之前的朴素贝叶斯,支持向量机之前的k-最近邻居)。更复杂的训练是诱人的,但他们通常更难以使用,因为他们有更多的参数需要调整以获得更好的结果,并且他们的内部更不透明。
模型可以分为两种主要类型:表示具有固定大小的线性分类器,以及表示可随数据增长的线性分类器,如决策树。固定大小的分类器只能利用这么多的数据。原则上可变大小的分类器可以在给定足够数据的情况下学习任何函数,但实际上,由于算法或计算成本的限制,它们可能不会。而且,由于维度的诅咒,没有现有的数据量可能就足够了。出于这些原因,那些充分利用数据和计算资源的算法,通常会表现得很好,只要你愿意付出努力。机器学习项目通常会有一个重要的学习者设计组成部分,从业者需要有一些专业知识。
9:模型不只是一个
在机器学习的早期,每个人都有自己喜欢的模型,以及一些先验理由相信它的优越性。大部分人努力尝试很多参数的变化,并选择了最好的一个。然后系统的经验表明,不同应用的最佳模型往往是不同,并且包含许多模型的系统开始出现。但是随后研究人员注意到,如果不是选择找到的最佳变体,我们可以结合了许多变体,结果会更好。并且对设计者而言没有额外的工作量。
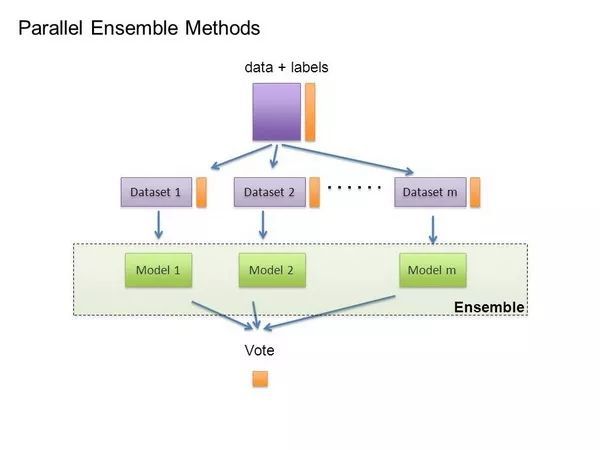
创建这样的模型集合有一个通用的名词:装箱。我们只需通过重采样生成随机变化的训练集,分别学习分类器并结合,看看他们的性能即可。这是有效的,因为它极大地减少了方差,而偏差只是稍微增加。在训练过程中,训练样例有权重,而且这些都是不同的,这样每个新的分类器都会将重点放在前面往往出错的例子上。在堆叠中,单个分类器的输出成为“更高层次”的输入,该模型计算出如何最好地组合它们。
在Netflix奖中,来自世界各地的团队竞相建立最佳视频推荐系统。随着比赛的进行,团队发现他们通过将学习者与其他团队相结合而获得最佳成绩。获胜者和亚军都是由100多名学习者组成的合并队伍,合并在一起进一步提高了模型的性能。毫无疑问,这将是未来的趋势。
10:简单并不意味着准确
奥卡姆的剃刀这个故事地指出,实体不应该超出必要的倍增。在机器学习中,这通常意味着,给定两个具有相同训练错误的分类器,其中较简单的分类器可能具有最低的测试错误。有关这一说法的证据经常出现在文献中,但事实上,它有很多反例,而“无免费午餐”定理暗示它不可能是真实的。

我们在前一部分看到一个反例:模型集合。即使在训练误差达到零之后,分类器的泛化误差也会继续提高。因此,与直觉相反,模型的参数数量与其过度拟合的倾向之间没有必然的联系。
相反,更复杂的观点将复杂性等同于假设空间的大小,因为较小的空间允许假设由较短的代码表示。如上面关于理论保证部分的界限可能会被视为暗示更短的假设。这可以通过将更短的代码分配给我们有一些先验偏好的空间中的假设来进一步细化。但将此视为准确性与简单性之间权衡的“证明”是循环推理:我们通过设计使我们喜欢的假设更简单,如果它们准确,那是因为我们的偏好是准确的,而不是因为假设“简单”代表了我们选择。
11:可描述并不意味着可以学习
本质上,所有可变规模模型的描述都具有形式的相关定理:“使用这种描述,每个函数都可以被描述或近似地描述”。然而,仅仅因为一个函数可以描述,并不意味着它可以被学习。例如,标准决策树模型不能学习含有更多叶子的树干。在连续的空间中,使用一组固定的基元描述甚至简单的函数往往需要无数的组件。

此外,如果假设空间具有许多评估函数的局部最优值(通常情况如此),则学习者可能无法找到真正的函数,即使它是可描述的。给定有限的数据、时间和记忆,标准模型只能学习所有可能函数的一小部分,而这些子集对于具有不同表述的模型是不同的。因此,关键问题不是“能否描述出来?
12:相关并不意味着因果关系
相关性并不意味着因果关系。但是,尽管我们讨论过的那种模型只能学习相关性,但他们的结果往往被视为代表因果关系。这不是错了吗?如果是这样,那么人们为什么这样做呢?

通常情况下,训练预测模型的目标是将它们用作行动指南。如果我们发现啤酒和尿布经常在超市买到,那么也许把啤酒放在尿布部分旁边会增加销售。但实际上实验很难说清楚。机器学习通常应用于观察性数据,其中预测变量不受学习者的控制。一些学习算法可能潜在地从观测数据中提取因果信息,但它们的适用性相当有限。另一方面,相关性是潜在因果关系的标志,我们可以用它作为进一步调查的指导。
结论
像任何学科一样,机器学习有很多的“民间智慧”,虽然不是100%正确,但对成功至关重要。多明戈斯教授的论文总结了一些最重要的内容。学习更多知识是他的书The Master Algorithm,这是一个非技术性的机器学习入门。他还教授在线机器学习课程,可以在这里查看。

媒体合作请联系: