[编译] 吴思锐 (湖南大学),[email protected]
Source: Xu R, Frank K A, Maroulis S J, et al. konfound: Command to quantify robustness of causal inferences[J]. The Stata Journal, 2019, 19(3): 523-550. Link
Stata连享会 计量专题 || 精品课程 || 推文 || 公众号合集

2020寒假Stata现场班 (北京, 1月8-17日,连玉君-江艇主讲)
「+助教招聘」

2020连享会-文本分析与爬虫-现场班
(西安, 3月26-29日,司继春-游万海 主讲; 内附助教招聘)

1 引言
未控制的混淆变量或非随机选取样本可能会导致偏差,为了评估因果推断偏差的稳健性,许多敏感性分析方法应运而生。然而,之前的多数方法要么仅仅控制某一特定来源的偏差(如遗漏变量),要么是仅适用于特定类型的数据(如分类变量)。本文主要介绍 konfound 命令,用以在 Stata 中执行如下两个检验:
- 使用 Rubin 因果模型解释偏差导致因果推断失效的程度;
- 根据回归模型中其他变量与不可观测变量的相关系数量化因果推断的稳健性。
具体而言, konfound 命令可用于检验模型的稳健性,mkonfound 命令可用于检验多次研究的稳健性,pkonfound 可用于检验对某一已发表研究的稳健性。接下来,我们简要介绍这两种方法的理论基础及在 Stata 中如何使用。对于该方法更加深入详细的介绍,可参考 Frank (2000), Pan 和 Frank (2003), Frank 和 Min (2007), Frank 等 (2008, 2013) 等文献。
2 因果推断的稳健性
2.1 遗漏的混淆变量的影响阈值
在观察性研究和准实验研究中,遗漏变量偏差是影响因果推断的一个关键问题。也就是说,有一些不可观测的混淆变量与自变量和因变量均相关,从而使模型估计产生偏差,使得推论无效。Frank (2000) 对这种混淆变量影响因果推断的程度进行了量化,他定义了混淆变量对因果推断的影响为
即混淆变量与自变量和混淆变量与因变量的相关系数的乘积。例如,研究父亲的职业 X 和其子女受教育程度 Y 之间的关系,一个被忽略的混淆变量可能是父亲的受教育程度 cv,父亲的受教育程度同时和自变量父亲的职业以及因变量子女受教育程度相关。

2.2 使推断无效的偏差百分比
第二种方法从评价估计中使推论无效的偏差比例开始(Frank et al., 2013)。偏差百分比被定义为能够被原假设替代从而使推论无效的可观测样本比例。这些替代可能来自反事实数据,如 Rubin 的因果模型(Rubin, 1974),也可能来自未被选取的样本。使用这一拐点,可以解决关于外部效度或关于内部效度的问题。
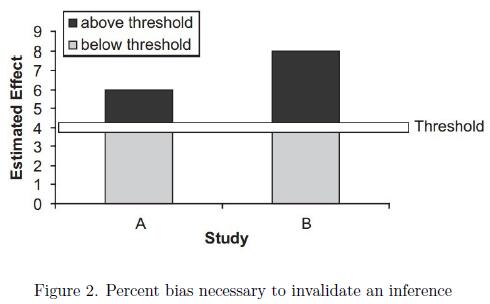
该方法源于将一个估计值与一个阈值对比时,要多大偏差才能使推论转变。例如,假设研究 A(估计效果为 6)和 B(估计效果为 8)的处理效果都超过了推断 4 的阈值。但是研究 B 的估计效果超出阈值的程度超过了研究 A 的估计效果(假设这些估计是在研究设计的选择偏差控制水平和精度水平相似的情况下获得的)。因此,我们认为研究 B 得出的推论比研究 A 得出的推论更可靠,因为研究 B 得出的估计有更大的比例是由于偏差而使推论无效。
3 konfound 命令
konfound varlist [, sig (#) nu (#) onetail (#) uncond (#) rep_0 (#) non_li (#)]
3.1 概述
konfound 命令用来计算遗漏的可能使因果推断回归系数失效的混淆变量的影响,它也可以用来评价遗漏变量和被解释变量以及解释变量相关的程度。在选取模型后(如线性回归模型),用户提供一系列变量名称,konfound 命令将会计算遗漏变量对每一个变量的影响,以此来判断因果推断的有效性。 konfound 命令还可以提供用户之前模型中所有可观测的协变量的的影响。这些可以用作评价遗漏的混淆变量对因果推断有效性影响的基准。
此外,konfound 还可以计算在估计中因果推断有效性偏差的大小。在选取模型后,用户可以提供一些列变量名称,konfound 命令将会计算每一个变量的偏差百分比,konfound 还可以提供用户模型中在统计意义上显著的变量的灵敏度图。
3.2 命令选项
- sig (#) 指明显著性水平,默认值为 sig (0.05)
- nu (#) 指明与所检验估计相对立的原假设,默认值为 nu (0)
- uncond (#) 计算调节模型协变量前后的影响和成分相关性,默认值为 uncond (1)
- rep_0 (#) 控制偏差百分比替换情形下的效果
- non_li (#) 针对非线性模型(如 logit 或 probit 模型),指定解释偏差百分比的基础
3.3 应用实例
我们以 Hamilton (1992) 数据集中的两个例子来说明 konfound 命令的用法。第一个命令来自 Hamilton (1983) 关于用水量的调查。被解释变量是1981年夏天的家庭用水量 water81,解释变量包括1980年夏天的家庭用水量 water80,家庭收入 income,受教育年限 educ,户主是否退休 retire 和1980年家庭成员数 peop80。首先,进行回归。
. use http://stats.idre.ucla.edu/stat/stata/examples/rwg/concord1
. regress water81 water80 income educat retire peop80
Source | SS df MS Number of obs = 496
----------+----------------------------- F(5, 490) = 194.82
Model | 727354309 5 145470862 Prob > F = 0.0000
Residual | 365884401 490 746702.858 R-squared = 0.6653
----------+----------------------------- Adj R-squared = 0.6619
Total | 1.0932e+09 495 2208563.05 Root MSE = 864.12
---------------------------------------------------------------------
water81 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
----------+----------------------------------------------------------
water80 | .4943149 .0268001 18.44 0.000 .4416577 .5469722
income | 22.60311 3.502279 6.45 0.000 15.72177 29.48445
educat | -44.25776 13.43811 -3.29 0.001 -70.6612 -17.85433
retire | 155.4727 96.33892 1.61 0.107 -33.81568 344.761
peop80 | 225.1984 28.70482 7.85 0.000 168.7987 281.5981
_cons | 299.7437 210.0136 1.43 0.154 -112.8947 712.3821
---------------------------------------------------------------------
家庭成员数 peop80 在统计意义上显著。为了量化关于遗漏变量的因果推断稳健性或量化或判断因果推断有效性的偏差百分比,我们使用konfound命令,结果如下所示。
konfound peop80
------------------
% Bias to Invalidate/Sustain the Inference
For peop80:
To invalidate the inference 74.96% of the estimate would have to be due to bias; to invalidate the inference 74.96% (372) cases would have to be replaced with cases for which there is an effect of 0.
------------------
Impact Threshold for Omitted Variable
For peop80:
An omitted variable would have to be correlated at 0.519 with the outcome and at 0.519 with the predictor of interest (conditioning on observed covariates) to invalidate an inference.
Correspondingly the impact of an omitted variable (as defined in Frank 2000) must be 0.519 x 0.519 = 0.2697 to invalidate an inference.
These thresholds can be compared with the impacts of observed covariates below.
Observed Impact Table for peop80
| Raw | Cor(v,X) | Cor(v,Y) | Impact |
|--------------+-----------+-----------+-----------|
| water80 | .5339 | .7648 | .4083 |
| income | .2845 | .4178 | .1188 |
| retire | -.3584 | -.2731 | .0979 |
| educat | .0571 | .0404 | .0023 |
| Partial | Cor(v,X) | Cor(v,Y) | Impact |
|--------------+-----------+-----------+-----------|
| water80 | .458 | .726 | .3325 |
| income | .0714 | .2868 | .0205 |
| educat | -.0545 | -.1567 | .0085 |
| retire | -.225 | -.0066 | .0015 |
X represents peop80, Y represents water81, v represents each covariate.
First table is based on unconditional correlations, second table is based on partial correlations.
注意:
- 首次使用
konfound命令的用户需要安装moss,indeplist和matsort三个命令。 - 在使用
konfound命令之前必须运行一次基准回归。 - 只有统计意义上显著的变量才能产生条形图。
- 用户可以同时评价多个变量因果推断的稳健性,如在前例中同时评价户主是否退休 retire 和家庭成员数 peop80的稳健性。
上述举例主要解释 konfound 命令在线性回归模型中的应用,接下来主要阐述 konfound 命令在非线性模型中的应用。在非线性模型中,由于基于相关性,遗漏变量影响阈值的方法不再适用,但偏差百分比方法仍然适用。但是,为了得到更为准确的偏差百分比,我们建议根据平均边际效应(又称为平均偏效应)而非原始回归系数计算。
下一个例子来自 Hamilton (1992) 数据集中关于 Williamstown污水的调研数据,被解释变量是受访者是否认为被污染的学校应该关闭的二分变量,解释变量包括居住年限 lived、受教育年限 educ、受访者是否参与过两次或两次以上健康和安全委员会的会议 hsc 和受访者是否是女性 female。
use https://stats.idre.ucla.edu/stat/stata/examples/rwg/toxic, clear
logit close lived educ contam hsc female
Iteration 0: log likelihood = -104.60578
Iteration 1: log likelihood = -73.509565
Iteration 2: log likelihood = -73.284048
Iteration 3: log likelihood = -73.283842
Iteration 4: log likelihood = -73.283842
Logistic regression Number of obs = 153
LR chi2(5) = 62.64
Prob > chi2 = 0.0000
Log likelihood = -73.283842 Pseudo R2 = 0.2994
------------------------------------------------------------------------------
close | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lived | -.0433669 .015164 -2.86 0.004 -.0730878 -.013646
educ | -.1684151 .0904774 -1.86 0.063 -.3457475 .0089174
contam | 1.185863 .4641455 2.55 0.011 .2761551 2.095572
hsc | 2.287901 .4836289 4.73 0.000 1.340006 3.235796
female | .7286153 .4422411 1.65 0.099 -.1381614 1.595392
_cons | 1.223659 1.334176 0.92 0.359 -1.391278 3.838595
------------------------------------------------------------------------------
结果显示 hsc 的估计效应在1%的水平上显著为正。为了计算 hsc 变量使推断无效的偏差百分比,我们使用 konfound 命令的非线性模型选项如下。
konfound hsc, non_li(1)
Average marginal effects Number of obs = 153
Model VCE : OIM
Expression : Pr(close), predict()
dy/dx w.r.t. : hsc
------------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
hsc | .356942 .0532873 6.70 0.000 .2525008 .4613832
------------------------------------------------------------------------------
Following calculation is based on Average Partial Effect:
------------------
The Threshold for % Bias to Invalidate/Sustain the Inference
For hsc:
To invalidate the inference 70.50% of the estimate would have to be due to bias;
> to invalidate the
inference 70.50% (108) cases would have to be replaced with cases for which ther
> e is an effect of 0.
连享会计量方法专题……
4. mkonfound 命令
mkonfound var1 var2 [, sig(#) nu(#) onetail(#) rep_0(#) z tran(#)]
4.1 概述
mkonfound 命令计算在多项研究中可能使回归系数推断无效的遗漏变量的影响,也可以评价遗漏变量和被解释变量以及解释变量相关的程度。用户输入可观测的 t 值和自由度这两个变量。mkonfound 命令生成四个变量。第一个变量 itcv_ 表示使回归系数推断无效的遗漏变量的影响,第二个变量 r_cv_y 表示在控制协变量的情况下使回归系数推断无效的遗漏变量与被解释变量的相关系数。第三个变量 r_cv_x 表示在控制协变量的情况下使回归系数推断无效的遗漏变量与解释变量的相关系数。第四个变量 stat_sig_ 表示如果原始回归是统计意义上显著的,则为1,否则为0。
4.2 命令选项
- sig (#) 指明显著性水平,默认值为 sig (0.05)
- nu (#) 指明与所检验估计相对立的原假设,默认值为 nu (0)
- onetail (#) 指明是单尾检验还是双尾检验,默认值为onetail(0)(双尾)
- rep_0 (#) 控制偏差百分比替换情形下的效果
- z_tran (#) 根据 Fisher's z 变换计算使因果推断系数无效的偏差百分比,默认值为 z_tran(0)
4.3 应用实例
为了说明 mkonfound 命令的使用方法,生成 t ratios和10项研究的自由度变量。
clear
set obs 10
// number of observations (_N) was 0, now 10
drawnorm t, mean(1) sd(3)
generate df=int(200*runiform())
list
+-----------------+
| t df |
|-----------------|
1. | -3.303957 149 |
2. | 2.403263 104 |
3. | -3.944921 80 |
4. | -.0738815 173 |
5. | 3.158566 54 |
|-----------------|
6. | .9201233 144 |
7. | -2.225994 159 |
8. | 2.888172 178 |
9. | 6.907921 141 |
10. | -.8450018 73 |
+-----------------+
接下来,使用 mkonfound 命令计算使因果推断系数无效的偏差百分比和遗漏变量影响阈值。
mkonfound t df
list
+--------------------------------------------------------------------------------+
| t df itcv_ r_cv_y r_cv_x stat_s~_ percen~e percen~n |
|--------------------------------------------------------------------------------|
1. | -3.303957 149 -.1211944 .348 -.348 1 38.84 . |
2. | 2.403263 104 .0478329 .219 .219 1 16.78 . |
3. | -3.944921 80 -.2395181 .489 -.489 1 46.18 . |
4. | -.0738815 173 .1246401 .353 .353 0 . 96.21 |
5. | 3.158566 54 .1804086 .425 .425 1 33.35 . |
|--------------------------------------------------------------------------------|
6. | .9201233 144 -.0742505 .272 -.272 0 . 52.96 |
7. | -2.225994 159 -.0226796 .151 -.151 1 10.99 . |
8. | 2.888172 178 .0766735 .277 .277 1 30.84 . |
9. | 6.907921 141 .4063581 .637 .637 1 67.34 . |
10. | -.8450018 73 .1054489 .325 .325 0 . 56.67 |
+--------------------------------------------------------------------------------+
为了计算遗漏变量的影响阈值,mkonfound 命令生成四个变量。第一个变量 itcv_ 表示使回归系数推断无效的遗漏变量的影响,第二个变量 r_cv_y 表示在控制协变量的情况下使回归系数推断无效的遗漏变量与被解释变量的相关系数。第三个变量 r_cv_x 表示在控制协变量的情况下使回归系数推断无效的遗漏变量与解释变量的相关系数。第四个变量 stat_sig_ 表示如果原始回归是统计意义上显著的,则为1,否则为0。
为了计算使因果推断无效的偏差百分比的影响,mkonfound 命令在每项研究中生成两个变量,percent_replace(percent_e) percent_sustain(percent_n),如表格后两列所示。对于在统计意义上显著的研究,percent_replace 显示为使推断无效,需要被效应为0的样本替代的样本百分比。对于在统计意义上不显著的研究,percent_sustain显示为使推断有效,需要被在推断阈值有效应的样本替代的样本百分比。
连享会计量方法专题……
5. pkonfound 命令
pkonfound # # # # [, sig(#) nu(#) onetail(#) rep 0(#)]
5.1 概述
pkonfound 命令根据用户输入的数值(如从已发表研究中获取的数值)(1)计算使因果推断系数无效的偏差百分比;(2)计算使因果推断系数无效的遗漏变量的影响,以此检验某一已发表研究的稳健性。
用户必须输入四个数值,第一个数是估计的效果值(如估计的回归系数),第二个数是估计效果的标准误差(回归系数),第三个数是样本规模,第四个数是模型中协变量的数量。
5.2 命令选项
- sig (#) 指明显著性水平,默认值为 sig (0.05)
- nu (#) 指明与所检验估计相对立的原假设,默认值为 nu (0)
- onetail (#) 指明是单尾检验还是双尾检验,默认值为onetail(0)(双尾)
- rep_0 (#) 控制偏差百分比替换情形下的效果
5.3 应用实例
为了说明 pkonfound 命令的使用方法,估计某一已发表研究的估计效应是10,估计的标准误差是2,样本规模是100,协变量的数量是4。为了计算使因果推断系数无效的偏差百分比和影响阈值,输入如下命令。
pkonfound 10 2 100 4
------------------
Impact Threshold for Omitted Variable
An omitted variable would have to be correlated at 0.569 with the outcome and at 0.569 with the predictor
of interest (conditioning on observed covariates) to invalidate an inference.
Correspondingly the impact of an omitted variable (as defined in Frank 2000) must be
0.569 x 0.569=0.3240 to invalidate an inference.
------------------
The Threshold for % Bias to Invalidate/Sustain the Inference
To invalidate the inference 60.29% of the estimate would have to be due to bias; to invalidate the
inference 60.29% (60) cases would have to be replaced with cases for which there is an effect of 0.
Note:
For non-linear models, the impact threshold should not be used.
The % bias calculation is based on the original coefficient, compare
with the use of average partial effects as in the [konfound] command.
类似于 konfound 命令,pkonfound 命令的结果也分为两部分。第一部分结果显示,使因果推断系数无效的遗漏变量的影响阈值和成分相关性。第二部分显示使因果推断系数无效的偏差百分比。
6. 主要参考文献
[1] Frank, K. A. 2000. Impact of a confounding variable on a regression coefficient. Sociological Methods and Research 29: 147–194. [PDF]
[2] Pan, W., and K. A. Frank. 2003. A probability index of the robustness of a causal inference. Journal of Educational and Behavioral Statistics 28: 315–337. [PDF]
[3] Frank, K. A., G. Sykes, D. Anagnostopoulos, M. Cannata, L. Chard, A. Krause, R.McCrory. 2008. Does NBPTS certification affect the number of colleagues a teacher helps with instructional matters? Educational Evaluation and Policy Analysis 30:3–30. [PDF]
[4] Xu, R., Frank, K. A., Maroulis, S. J., & Rosenberg, J. M. 2019. konfound: Command to quantify robustness of causal inferences. The Stata Journa 19(3): 523-550. [PDF]
关于我们
- Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- 公众号推文同步发布于 CSDN,和知乎平台。可在上述网站或百度中搜索关键词「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接和相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期精彩推文:
Stata绘图 | 时间序列+面板数据 | Stata资源 | 回归分析-交乘项-内生性 | 数据处理+程序 |

RqjkOw)