
本文是小编在一次数学建模比赛中所用的模型,特此记录下来分享于大家便于理解。文中如有知识等错误,请在评论区指出更正。感谢阅读!
问题分析
为了评估N个鸡蛋中是否有圈养鸡蛋,我们利用卷积神经网络(CNN)让计算机学习圈养鸡蛋和土鸡蛋图片的特征,然后根据鸡蛋的图片将其分类。通过对图片的预处理,将其转化为3232相同大小的图片。在神经网络加载数据之后,会将其转化为3232*3的数组。然后通过卷积和池化等一系列操作提取出图片的特征。以达到对鸡蛋进行分类的目的。我们主要用Python语言在TensorFlow中构建卷积神经网络(CNN),让CNN学习圈养鸡蛋和土鸡蛋的特征。然后对比其多次测试分类的情况。综合评估N个鸡蛋是否有圈养鸡蛋。
前期数据处理
-
数据描述
因为神经网络需要固定输入的图片大小,所以,我们将所有图片调整为相同的大小。但是由于图片具有不同的长宽比,并且我们收集的图片数据中鸡蛋的占比率比较小,噪点较多,图片特征不明显。我们采用裁剪方式,将其背景去掉,使鸡蛋面积占图片面积超过50%。提高土鸡蛋和圈养鸡蛋的图片特征。优化数据集,让机器更好的学习两种鸡蛋的特征。最终,我们用程序将图片批量处理为32 * 32像素的尺寸,这在肉眼下较容易识别图片。如下图:
 size: 33*32
size: 33*32 -
数据目录结构:
 项目目录
项目目录
datasets目录有两个子文件夹Training和Testing用于存放训练和测试图片,训练过程模型保存在egg_model1目录下.。模型代码在egg根目录。整个egg文件夹已放在附件。
-
加载数据方式
因为数据集比较小,因此可以直接将数据加载到RAM里面。加载完数据之后,并且通过Numpy将其转化成数组(矩阵)格式。下图是我们通过代码访问并显示数据集况:
 说明:0表示圈养鸡蛋,1表示土鸡蛋
说明:0表示圈养鸡蛋,1表示土鸡蛋
模型建立
-
模型描述
模型是基于TensorFlow建立的,因此我们先了解TensorFlow中的神经网络。
TensorFlow的执行图中封装了神经网络的架构。构建的图包含了操作(简称为Ops),比如 Add,Multiply,Reshape,..... 等等。这些操作在张量(多维数组)中对数据执行操作。

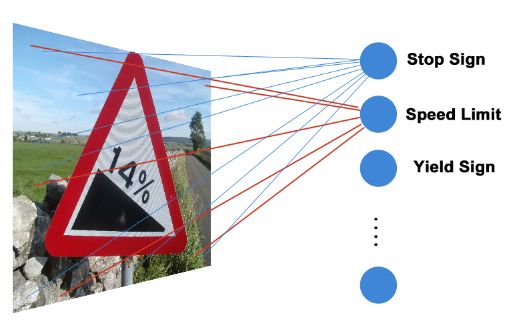
模型训练需要提取出图片的特征,即计算出图片数组的特征值。模型的输入层是一个一维向量。该向量由一个32323的三维数组压平转化而得。神经层通过构d建一个全连接池,该连接池有N个神经元,让每个神经元都连接到输入层,因此每个神经元接受32 * 32 * 3 = 3072个输入。并使用ReLU函数作为激活函数。下图较清晰地描述了模型思路:
ReLU激活函数:f(x) = max(0, x),如下:
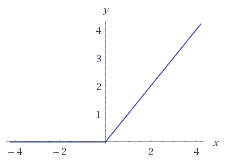
使用ReLU函数作为激活函数的优点是它可以模拟出了脑神经元接受信号更精确的激活模型,更快的进行特征学习,学习周期大大缩短。综合速率和效率更高。
- 建立模型
2.1. 设置占位符(Placeholder)用来放置图片和标签。
参数images_ph的维度是[None, 32, 32, 3],四个参数分别表示[批量大小,高度,宽度,通道]。批处理大小用None表示向模型中导入任意批量大小的数据。
images_ph=tf.placeholder(tf.float32, [None,32,32,3])
labels_ph = tf.placeholder(tf.int32, [None])
2.2. 定义一个全连接层
logits=tf.contrib.layers.fully_connected(images_flat, 32, tf.nn.relu)
模型的输入是一个一维向量(images_flat)。全连接层的输出是一个长度是32的对数矢量,如:[0.3, 0, 0, 1.2, 2.1, 0.01, 0.4, ... ..., 0, 0]。矢量值越高,表示图片为该标签的可能性越高。
2.3. 将连接层结果的最大值为预测值
predicted_labels = tf.argmax(logits, 1)
argmax函数使输出结果(logits)将是一个整数,范围是0和1。0表示圈养鸡蛋,1表示土鸡蛋。预测标签保存在predicted_labels列表中。
2.4. 定义交叉熵损失函数
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits,labels_ph))
因为我们用Relu函数作为神经元的激活函数时,因此使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢。交叉熵代价函数是一个在分类任务中最常见的函数。它是两个概率向量之间的差的度量。TensorFlow中交叉熵函数表示为:sparse_softmax_cross_entropy_with_logits,利用交叉熵函数将标签和神经网络的输出转换成概率向量。然后通过reduce_mean函数来获得一个值,表示最终的损失值。
2.5. 使用梯度下降训练
train=tf.train.AdamOptimizer(0.001).minimize(loss)
使用ADAM优化算法,它对每个权值都计算自适应的学习速率,收敛速度比一般的梯度下降法更快。
2.6.初始化所有的操作,将所有变量的值设置为零(或随机值)
init = tf.initialize_all_variables()
开始训练模型
- 创建一个会话(Session)对象。
会话(Session)保存所有变量的值。模型中图(Gragh)保存的是方程y = xW + b,那么会话保存的是这些变量的实际值。
session = tf.Session()
- 初始化操作
session.run(init)
- 开始循环训练模型
for i in range(200):
_, loss_value = session.run([train, loss],
feed_dict={images_ph: images_a, labels_ph:
labels_a})
if i % 10 == 0:
print("Loss: ", loss_value)
在训练过程中,我们记录并且打印出损失函数的值,帮助我们监控训练的进度。将循环次数设置成了200,并且当循环次数满足10的倍数时,打印出损失值。最终的输出结果看起来像这样:
Loss: 164.604
Loss: 12.3638
Loss: 7.03638
...
Loss: 1.22729
Loss: 1.00379
模型测试(检验)
- 随机取了10个图片进行分类,并且同时打印了标签结果和预测结果。
sample_indexes=random.sample(range(len(images32)), 10)
sample_images = [images32[i] for i in sample_indexes]
sample_labels = [labels[i] for i in sample_indexes]
# Run the "predicted_labels" op.
predicted = session.run(predicted_labels,
{images_ph: sample_images})print(sample_labels)print(predicted)
Output:
[0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1]
[0 1 1 0 1 1 1 1 1 0 1 0 0 0 1 1 1 1 1 1]
- 结果可视化,编写一个可视化函数用来展示对比结果,展示效果如下:
从图中我们可以发现,我们的模型是可以正确运行的,但是从图中不能量化它的准确性。因为训练数据量比较小,我们测试分类的还是训练的图片。因此模型在未知数据集上面的效果如何,我们在测试集上面进行更好地评测。
模型评估(优缺点和优化)
模型优点:
1.读取方式简单,直接读取数据图片所在目录文件夹。
2.通过将图片改成32*32像素相同大小,可以快速高效地提取出图片的特征,提高模型的学习效率和准确值。
3.利用一个全连接池的32神经元,多个特征提取,最后通过迭代训练找出特征最明显的情况确认可能性最高分类结果。
4.训练速度快,计算量较小。可以快速高效地训练并得到分类结果、模型缺点:
1.当loss处于局部收敛时,会出现分类情况为全是圈养鸡蛋,分类无效。
2.训练过程中变量不能保存,每次测试过程中都需要训练,这使得模型应用性较差。因此我们需要在此基础上进行优化,使其保存在训练过程中的所有变量值,测试的时候直接读取训练的变量值,提高测试效率。
3.模型优化:
由于需要将变量保存起来,我们给模型增加两个卷积层构成卷积神经网络(CNN),我们在输入层和全连接层之间加入两次卷积和池化。模型结构如下图:
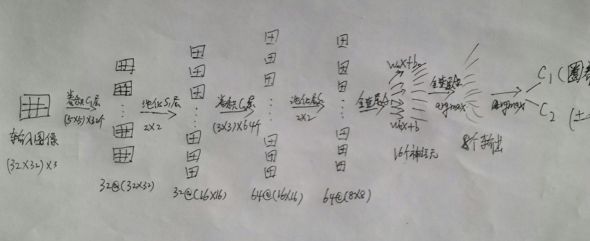
模型优化部分如下:
一. 定义变量和卷积池化函数
- 定义权值变量函数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
- 定义偏差变量 函数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
- 卷积函数
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
- 池化函数
def max_pool(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
- 第一个卷积层
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(images_ph, W_conv1) + b_conv1)
参数为卷积核为5*5,图片RGB通道为3,输出为32
- 第一个池化层
h_pool1 = max_pool(h_conv1)
将卷积每一个通道的32个输出通过22池化得到32个1616图片
- 第二个卷积层
W_conv2 = weight_variable([3, 3, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
参数为卷积核为3*3,图片RGB通道为3,输出为64
- 第二个池化层
h_pool2 = max_pool(h_conv2)
将卷积每一个通道的32个输出通过22池化得到64个88图片
- 第一个全连接池
W = weight_variable([8864,16])
b = bias_variable([16])
h_pool2_flat = tf.reshape(h_pool2, [-1, 8864])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat, W) + b)
参数8864为第二池化层输出的图片大小8*8以及数量64
- 第二个全连接池
logits = tf.contrib.layers.fully_connected(h_fc1,8, tf.nn.relu)
11.防止过拟合(dropout)
用dropout防止logits过拟合
keep_prob = tf.placeholder("float")
logits1 = tf.nn.dropout(logits, keep_prob)
- 保存(Saver)和读取(Restore)
saver = tf.train.Saver()
#判断模型保存路径是否存在,不存在就创建
if not os.path.exists('egg_model/'):
os.mkdir('egg_model/')
#初始化
session = tf.Session()
if os.path.exists('egg_model/checkpoint'): #判断模型是否存在
saver.restore(session, 'egg_model/model1.ckpt') #存在就从模型中恢复变量
else:
init = tf.global_variables_initializer() #不存在就初始化变量
session.run(init)
for i in range(10):
train_value, loss_value = session.run([train, loss],
feed_dict={images_ph: images_a, labels_ph: labels_a,keep_prob:0.8})
if(i%2==0):
save_path = saver.save(session, 'egg_model/model1.ckpt') print("模型保存:%s 当前训练损失:%s"%(save_path, loss_value))
-
训练过程
下图是训练50次后随机抽取10张的预测结果:
 准确率70%
准确率70%
可视化如图:

-
测试过程:
我们分为两个数据集合,一个用于训练,另一个用于测试。两个数据有所区别。用于测试图片数据鸡蛋面积的占图片面积百分比多样化,图片处理比训练数据更加随机化。所以,我们可以很容易的使用测试集来评估我们的训练模型。再让其训练1000次之后,让其分类测试数据集,先在测试集中随机抽二十张,分类效果如下:
 准确率65%
准确率65%
测试全部图片:

为了确认当前训练情况是否有效。我们用一个评估部分的相关代码,加载测试集,然后计算预测正确性。代码如下:
# 测试全部图片.
predicted = session.run(predicted_labels,
feed_dict={images_ph: sample_images,keep_prob:0.8})
match_count = sum([int(y == y_)
for y, y_ in zip(sample_labels, predicted)])
accuracy = match_count / len(sample_labels)
print("正确数量:",match_count)
print("测试图片总数量:",len(sample_labels))
print("Accuracy: {:.3f}".format(accuracy))
结果如下所示:

在每次的运行中,模型在训练次数较小的情况下(1000次),准确性在0.50~0.70之间:

造成这个原因是模型是否落在局部最小值还是全局最小值。这也是简单的CNN模型无法避免的问题。那么当我们增加模型训练次数,扩大数据集更大时,模型训练的正确率是否将更高,又能达到多少呢。。如何提高结果的一致性?这个还需要增加收集数据量和训练时间,由于数据和时间有限,我们将下一次专题讨论。
By 何斌