主从复制的读写分离:
- mysql-proxy(Mysql官方提供,坑巨多,现已不维护此项目,更换为mysql-router也不推荐使用) --> atlas(国内公司开源的mysql-proxy衍生稳定版)
- mycat:国内项目
- amoeba for MySQL:读写分离、分片;
- OneProxy
开源的项目:
- ProxySQL(DBA 提供的完全开源的版本)
http://www.proxysql.com/, ProxySQL is a high performance, high availability, protocol aware proxy for MySQL and forks (like Percona Server and MariaDB).
https://github.com/sysown/proxysql/releases - MaxScale
MaxScale是maridb开发的一个MySQL数据中间件,配置好MySQL的主从复制架构后,希望实现读写分离,把读操作分散到从服务器中,并且对多个服务器实现负载均衡。 - cobar:Cobar是来自阿里的mysql中间件; gizzard
- AliSQL:
- mysqlrouter:
语句透明路由服务;
MySQL Router 是轻量级 MySQL 中间件,提供应用与任意 MySQL 服务器后端的透明路由。MySQL Router 可以广泛应用在各种用案例中,比如通过高效路由数据库流量提供高可用性和可伸缩的 MySQL 服务器后端。Oracle 官方出品。
双主或多主模型是无须实现读写分离,仅需要负载均衡:haproxy, nginx, lvs, ...
- pxc:Percona XtraDB Cluster
- MariaDB Cluster
ProxySQL配置示例:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:admin"
mysql_ifaces="127.0.0.1:6032;/tmp/proxysql_admin.sock"
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:3306;/tmp/mysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.5.30"
connect_timeout_server=3000
monitor_history=600000
monitor_connect_interval=60000
monitor_ping_interval=10000
monitor_read_only_interval=1500
monitor_read_only_timeout=500
ping_interval_server=120000
ping_timeout_server=500
commands_stats=true
sessions_sort=true
connect_retries_on_failure=10
}
mysql_servers =
(
{
address = "172.18.0.67" # no default, required . If port is 0 , address is interpred as a Unix Socket Domain
port = 3306 # no default, required . If port is 0 , address is interpred as a Unix Socket Domain
hostgroup = 0 # no default, required
status = "ONLINE" # default: ONLINE
weight = 1 # default: 1
compression = 0 # default: 0
},
{
address = "172.18.0.68"
port = 3306
hostgroup = 1
status = "ONLINE" # default: ONLINE
weight = 1 # default: 1
compression = 0 # default: 0
},
{
address = "172.18.0.69"
port = 3306
hostgroup = 1
status = "ONLINE" # default: ONLINE
weight = 1 # default: 1
compression = 0 # default: 0
}
)
mysql_users:
(
{
username = "root"
password = "mageedu"
default_hostgroup = 0
max_connections=1000
default_schema="mydb"
active = 1
}
)
mysql_query_rules:
(
)
scheduler=
(
)
mysql_replication_hostgroups=
(
{
writer_hostgroup=0
reader_hostgroup=1
}
)
maxscale配置示例:
[maxscale]
threads=auto
[server1]
type=server
address=172.18.0.67
port=3306
protocol=MySQLBackend
[server2]
type=server
address=172.18.0.68
port=3306
protocol=MySQLBackend
[server3]
type=server
address=172.18.0.69
port=3306
protocol=MySQLBackend
[MySQL Monitor]
type=monitor
module=mysqlmon
servers=server1,server2,server3
user=maxscale
passwd=201221DC8FC5A49EA50F417A939A1302
monitor_interval=1000
[Read-Only Service]
type=service
router=readconnroute
servers=server2,server3
user=maxscale
passwd=201221DC8FC5A49EA50F417A939A1302
router_options=slave
[Read-Write Service]
type=service
router=readwritesplit
servers=server1
user=maxscale
passwd=201221DC8FC5A49EA50F417A939A1302
max_slave_connections=100%
[MaxAdmin Service]
type=service
router=cli
[Read-Only Listener]
type=listener
service=Read-Only Service
protocol=MySQLClient
port=4008
[Read-Write Listener]
type=listener
service=Read-Write Service
protocol=MySQLClient
port=4006
[MaxAdmin Listener]
type=listener
service=MaxAdmin Service
protocol=maxscaled
port=6602
MHA:Master HA(主从结构的高可用方案)
使用MHA对mysql主从复用的主节点做高可用;对主节点进行监控,可实现自动故障转移至其它从节点;通过提升某一从节点为新的主节点;
- MHA介绍:
MHA(Master HA)是一款开源的MySQL的高可用程序,它为MySQL主从复制架构提供了automating master failover功能。MHA在监控到master节点故障时,会提升其中拥有最新数据的slave节点称为新的master,在此期间,MHA会通过其它从节点获取额外信息来避免一致性方面的问题。MHA还提供了master节点在线切换的功能,即按需切换master/salve节点。
MHA服务有两种角色,MHA Manager(管理节点)和MHA Node(数据节点):
MHA Manager:通常单独部署在一台独立的机器上管理多个master/slave集群,每个master/slave集群称作一个Application;
MHA Node:运行在每台MySQL服务器上(master/slave/manager),它通过监控具备分析和清理logs功能的脚本来加快故障转移。 -
MHA架构:
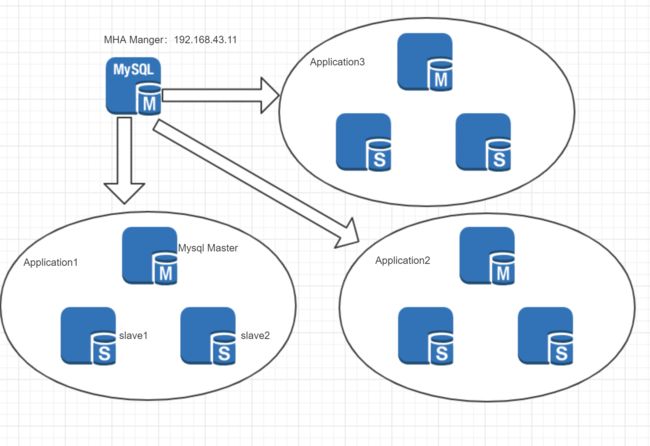 MHA架构.png
MHA架构.png
MySQL复制集群中的master故障时,MHA按如下步骤进行故障转移:
(1) 主节点掉线,会有丢失的事件还没有复制到从节点上,为了避免出现事件丢失而导致数据不一致,MHA会在管理节点上保存一份主节点上的二进制日志事件的副本
(2) 当主节点掉线后,从管理节点上保存的事件中就能读出所有的事件,并且查找从各个节点中的中继日志中事件指针指向的位置,来拍段哪个节点与主节点的事件更接近,并把管理节点本地备份冗余的二进制日志事件读出并处理应用在这个最接近的从节点上,使这个从节点与主节点事件同步
(3) 然后把其它从节点的主节点指向这个被修复的最近从节点,从而提升这个从节点为新的主节点
(4) 为了完成这个功能MHA强依赖与ssh服务,因此它要通过ssh协议从主节点不断读取各种数据,把二进制日志事件同步到本地,以保证主节点掉线本地扔能获取到二进制日志事件;然后,就在最近的从节点上重放管理节点上的事件,达到与掉线的朱姐点一样的数据
- MHA的组件:
MHA会提供诸多工具程序,常见如下- Manager节点:
- masterha_check_ssh: MHA依赖的ssh环境检测工具
- masterha_check_repl: MySQL复制环境检测工具
- masterha_manager: MHA服务主程序
- masterha_master_monitor: MySQL master 节点可用性检测工具
- masterha_master_switch: master节点切换工具
- masterha_conf_hos: 添加或删除配置的节点
- masterha_stop: 关闭MHA服务
- Node节点:
- save_binary_logs: 保存和复制master的二进制日志
- apply_diff_relay_logs: 识别差异的中继日志事件并应用于其他slave
- filter_mysqlbinlog: 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
- purge_relay_logs: 清除中继日志(不会阻塞SQL线程)
- 自定义扩展:
- secondary_check_script:通过多条网络路由检测master的可用性;
- master_ip_ailover_script:更新Application使用的masterip;
- shutdown_script:强制关闭master节点;
- report_script:发送报告;
- init_conf_load_script:加载初始配置参数;
- master_ip_online_change_script:更新master节点ip地址;
- Manager节点:
- MHA对MySQL复制环境有特殊要求:
各节点都要开启二进制日志和中继日志,各从节点必须显式启用其read-only属性,并关闭relay_log_purge功能等;
演示MHA高可用主从架构的配置实现:
manager :192.168.43.11
master:192.168.43.13
slave:192.168.43.14;192.168.43.15
第一步:时间同步
[root@node1 ~]# systemctl restart chronyd.service
第二步:修改hosts配置文件实现主机名通信
[root@node1 ~]# vim /etc/hosts
192.168.43.11 node1
192.168.43.12 node2
192.168.43.13 node3
192.168.43.14 node4
192.168.43.15 node5
192.168.43.16 node6
[root@node1 ~]# scp /etc/hosts [email protected]:/etc
[root@node1 ~]# scp /etc/hosts [email protected]:/etc
[root@node1 ~]# scp /etc/hosts [email protected]:/etc
第三步:配置主从复制集群,1主2从,所有节点都授权slave用户可复制,过程不此处赘述。
第四步:生成密钥对 通过ssh密钥认证,使哥哥节点可以使用私钥实现相互ssh通信
在MHA管理节点manager上:
[root@node1 ~]# ssh-keygen -t rsa -P ''
[root@node1 ~]# cat .ssh/id_rsa.pub > .ssh/authorized_keys
[root@node1 ~]# chmod 600 .ssh/authorized_keys
[root@node1 ~]# ll .ssh/authorized_keys
-rw------- 1 root root 392 Nov 11 13:23 .ssh/authorized_keys
[root@node1 ~]# ssh node1 #使用ssh连接自己
把私钥和认证文件复制到各节点一份:
[root@node1 ~]# scp .ssh/{id_rsa,authorized_keys} node3:/root/.ssh
[root@node1 ~]# scp .ssh/{id_rsa,authorized_keys} node4:/root/.ssh
[root@node1 ~]# scp .ssh/{id_rsa,authorized_keys} node5:/root/.ssh
验证ssh 登录:
[root@node1 ~]# ssh node3 'ifconfig ens33' #第一次需要输入yes确认
ens33: flags=4163 mtu 1500
inet 192.168.43.13 netmask 255.255.255.0 broadcast 192.168.43.255
inet6 2408:84e4:290:ad0c:20d9:f6ba:959d:75bf prefixlen 64 scopeid 0x0
inet6 fe80::7e0c:f15e:acf3:6ff2 prefixlen 64 scopeid 0x20
inet6 fe80::b295:9b62:e93:ce9a prefixlen 64 scopeid 0x20
ether 00:0c:29:78:6d:b7 txqueuelen 1000 (Ethernet)
RX packets 124175 bytes 59707292 (56.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 70693 bytes 58128457 (55.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
第四步:安装MHA
程序下载地址:https://code.google.com/archive/p/mysql-master-ha/downloads;CentOS7可以直接使用适用于el6的程序包。
也可以在github上直接下载
[root@node1 ~]# git clone https://github.com/linyue515/mysql-master-ha.git
在管理节点安装manager:
[root@node1 ~]# cd mysql-master-ha/
[root@node1 mysql-master-ha]# yum -y install ./mha4mysql-manager-0.57-0.el7.noarch.rpm #MHA是使用perl研发的,所以依赖众多模块;需要配置好epel源和base源;
[root@node1 mysql-master-ha]# yum -y install ./mha4mysql-node-0.57-0.el7.noarch.rpm
其它3个节点上安装MHA的node程序:
[root@node1 mysql-master-ha]# scp ./mha4mysql-node-0.57-0.el7.noarch.rpm node3:/root
mha4mysql-node-0.57-0.el7.noarch.rpm 100% 35KB 2.1MB/s 00:00
[root@node1 mysql-master-ha]# scp ./mha4mysql-node-0.57-0.el7.noarch.rpm node4:/root
mha4mysql-node-0.57-0.el7.noarch.rpm 100% 35KB 1.9MB/s 00:00
[root@node1 mysql-master-ha]# scp ./mha4mysql-node-0.57-0.el7.noarch.rpm node5:/root
mha4mysql-node-0.57-0.el7.noarch.rpm
[root@node3 ~]# yum -y install ./mha4mysql-node-0.57-0.el7.noarch.rpm
[root@node4 ~]# yum -y install ./mha4mysql-node-0.57-0.el7.noarch.rpm
[root@node5 ~]# yum -y install ./mha4mysql-node-0.57-0.el7.noarch.rpm
第五步:初始化MHA
Manager节点需要为每个接口的master/slave集群提供一个专用的配置文件,而所有的master/slave集群也可共享全局配置。全局配置文件默认/etc/masterha_default.cnf,其为可选配置。如果仅监控一组master/slave集群,也可直接通过Application的配置来提供各服务器的默认配置信息。而每个Application的配置文件路径为自定义,例如使用/etc/masterha/app1.cnf;
在master主节点:创建一个拥有管理权限的用户账号且能够远程连接;
MariaDB [(none)]> GRANT ALL ON *.* TO 'mhauser'@'192.168.43.%' IDENTIFIED BY 'mhapass';
MariaDB [(none)]> FLUSH PRIVILEGES;
在MHA管理节点编辑配置文件:
[root@node1 ~]# mkdir /etc/masterha/ -pv
[root@node1 ~]# vim /etc/masterha/app1.cnf
[server default]
user=mhauser #此用户为能够远程各mysql主机并拥有管理权限的用户账号;
password=mhapass #为上个指定用户的密码;
manager_workdir=/data/masterha/app1 #此目录可以不存在,会自动创建;
manager_log=/data/masterha/app1/manger.log #日志文件可随意设定;
remote_workdir=/data/masterha/app1 #可与管理节点工作目录保持一致,也可自定义其它目录,此目录不存在,会自动创建;
ssh_user=root #基于ssh通信的用户;
repl_user=slave #拥有复制权限的用户账号;
repl_password=slave #拥有复制权限的用户账号的密码;每个节点保持一样;
ping_interval=1 #表示MHA每隔多长时间检测一次主节点是否在线;
[server1]
hostname=192.168.43.13
#ssh_port=22022 #如果ssh改为别的端口可使用此指令定义;
candidate_master=1 #表示此节点是否可参与成为新的主节点;
[server2]
hostname=192.168.43.14
candidate_master=1
[server3]
hostname=192.168.43.15
#no_master=1
检测各个节点ssh互相通信是否OK:
[root@node1 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
...
Sun Nov 11 15:40:17 2018 - [info] All SSH connection tests passed successfully. ##此行出现表示通过检测
检查管理的Mysql复制集群的连接配置参数是否OK:
[root@node1 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
...
MySQL Replication Health is OK. #此行出现表示通过检测
启动:
[root@node1 ~]# masterha_manager --conf=/etc/masterha/app1.cnf #此命令表示MHA在前台工作,此时可测试使mysql主节点掉线,会自动把一个从节点提升为主节点,这个工作在前台的MHA管理端就会自动退出,需要手动再次开启;
在master节点:
[root@node3 ~]# killall mysqld
在slave节点查看:此时master节点已经转移到192.168.43.14上
MariaDB [(none)]> SHOW SLAVE STATUS\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.43.14
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 245
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 529
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
在新的master节点上查看:
MariaDB [(none)]> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 245 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
MariaDB [(none)]> SHOW GLOBAL VARIABLES LIKE 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
1 row in set (0.00 sec)
至此MHA完成了mysql的主从切换;
下面开始恢复主节点的操作:
(1) 在新master节点备份数据 然后恢复到新加入的节点上:
[root@node4 ~]# innobackupex --backup /backup
[root@node4 backup]# tar -zcf backup.tar.gz ./2018-11-11_16-19-13/
[root@node4 backup]# scp backup.tar.gz node3:/backup/
[root@node3 backup]# tar xf backup.tar.gz
[root@node3 backup]# rm -rf /var/lib/mysql/*
[root@node3 backup]# innobackupex --apply-log ./2018-11-11_16-19-13/
[root@node3 backup]# innobackupex --copy-back ./2018-11-11_16-19-13/
[root@node3 backup]# chown -R mysql.mysql /var/lib/mysql/
(2) 把新的节点配置为从节点加入到复制集群中
[root@node3 ~]# vim /etc/my.cnf
[mysqld]
log_bin=mysql-bin
server_id=1
relay_log_purge=0
relay_log=relay-bin
read_only=1
[root@node3 ~]# systemctl start mariadb
[root@node3 ~]# mysql
MariaDB [(none)]> GRANT REPLICATION CLIENT,REPLICATION SLAVE ON *.* TO 'slave'@'192.168.43.%' IDENTIFIED BY 'slave';
MariaDB [(none)]> GRANT ALL ON *.* TO 'mhauser'@'192.168.%.%' IDENTIFIED BY 'mhapass';
MariaDB [(none)]> FLUSH PRIVILEGES;
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='192.168.43.14',MASTER_USER='slave',MASTER_PASSWORD='slave',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=462;
MariaDB [(none)]> START SLAVE;
MariaDB [(none)]> SHOW SLAVE STATUS\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.43.14
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 462
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 529
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
在manager节点:
[root@node1 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
......
MySQL Replication Health is OK
[root@node1 ~]# masterha_manager --conf=/etc/masterha/app1.cnf
Sun Nov 11 16:53:09 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sun Nov 11 16:53:09 2018 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sun Nov 11 16:53:09 2018 - [info] Reading server configuration from /etc/masterha/app1.cnf..
注意:在实际生产环境中如果使用MHA,那么前端仍然需要一个读写分离器。
.............
MySQL借助Galera Cluster构建多主集群
Galera Cluster类似于高可用集群中的corosync,是分了三个层次的,首先是在多个节点上部署一个信息库,有了信息库以后,上面的应用程序想要完成高可用,这个应用程序自己在研发时调用信息层提供的API去开发,并利用这个API完成集群事务角色;如果不能中间要加一个中间层,就是资源管理器,比如pacemaker就是实现这个功能的;如果没有pacemaker应用程序就要自己把pacemaker的功能实现出来;
因此,对于Galera Cluster也是如此,Galera Cluster本身并不是专门为mysql提供的,它其实就是一个工作较为底层的能够为服务提供数据复制功能的一个底层组件。Mysql只有在研发时调用了Galera Cluster 的API编写这个mysql,它才能基于Galera Cluster完成复制。
简单说,Galera Cluster不是通过让其它节点读取二进制日志在本地重放,而是由Galera Cluster自己,只要指明了哪个复制文件,自己在底层能够直接完成同步;因此,只有使用mysql编译进Galera Cluster的程序包才能使用Galera Cluster构建msyql多主集群;
有三种方式:
自行下载安装相关支出Galera Cluster的对应版本
- 第一种:直接使用Galera Cluster官方提供的支持Galera Cluster的mysql版本
- 第二种:使用percaon官方的发行版,percona-cluster的mysql分支版本;https://www.percona.com/downloads/Percona-XtraDB-Cluster-LATEST/
- 第三种:使用MariaDb的发行版,MariaDB_cluster支持的mysql分支版本;https://mariadb.com/kb/en/mariadb/getting-started-with-mariadb-galera-cluster/
wresp协议复制:
wresp协议与MMM和MHA不同,MMM和MHA都是建构在mysql主从复制结构之上的,也就是说需要事先把mysq配置成传统的复制集群,二者能够在其复制的基础之上完成其功能的增进;但是,Galera Cluster不是这样的;它无需将mysql服务器配置成主从,因为整个复制不是在mysql协议通过读取二进制日志实现,而是在wresp协议直接在较底层的存储级别,将主节点上的任何数据片段变化给同步到其它节点上实现的;而且这其中任何一个节点都可以是主节点;是一套多主节点模型;
Galera Cluster架构实现:
至少需要三个节点(确保法定票数),不能安装mariadb-server
节点1;192.168.43.13
节点2:192.168.43.14
节点3:192.168.43.15
安装Galera Cluster要先替换现有的mariadb-server
使用mariadb官方提供yum源:
[root@node3 ~]# vim /etc/yum.repos.d/CentOS-Mariadb.repo
[mariadb]
name=MariaDB
baseurl=http://yum.mariadb.org/5.5/centos7-amd64/
gpgkey=http://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
[root@node3 ~]# yum repolist
[root@node3 ~]# yum list all | grep -i "mariadb-galera"
MariaDB-Galera-server.x86_64 5.5.62-1.el7.centos mariadb
MariaDB-Galera-test.x86_64 5.5.62-1.el7.centos mariadb
[root@node3 ~]# yum -y remove mariadb-server mariadb-libs #此处
[root@node3 ~]# yum -y install MariaDB-Galera-server
[root@node3 ~]# rpm -ql galera | grep "libgalera"
/usr/lib64/galera/libgalera_smm.so
节点2和节点3同样方式安装:
[root@node4 ~]# yum -y remove mariadb-server mariadb-libs #此处
[root@node4 ~]# yum -y install MariaDB-Galera-server
[root@node5 ~]# yum -y remove mariadb-server mariadb-libs #此处
[root@node5 ~]# yum -y install MariaDB-Galera-server
节点1修改配置文件:
[root@node3 ~]# vim /etc/my.cnf.d/server.cnf
[galera]
# Mandatory settings
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcom://192.168.43.13,192.168.43.14,192.168.43.15"
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
wsrep_cluster_name='mycluster'
[root@node3 ~]# scp /etc/my.cnf.d/server.cnf node4:/etc/my.cnf.d/
[root@node3 ~]# scp /etc/my.cnf.d/server.cnf node5:/etc/my.cnf.d/
在节点1启动cluster:
[root@node3 ~]# /etc/init.d/mysql start --wsrep-new-cluster
Starting MySQL.... SUCCESS!
在节点2、3正常启动mysql:
[root@node4 ~]# service mysql start
Starting MySQL....SST in progress, setting sleep higher. SUCCESS!
[root@node5 ~]# service mysql start
Starting MySQL....SST in progress, setting sleep higher. SUCCESS!
以上实现了基于wsrep协议的Galera Cluster的mysql多主复制功能;
此方式跟meyslq传统的复制模型没有关系,不用配置二进制日志同样可以实现复制;
自动增长的id号不是按顺序的,可以在插入数据时,手动指明其序号即可;
还可使用全局id生成器;这样,只要保证在任何一个节点插入数据的id号都是唯一的,没有重复的就ok;而且这种复制比通过二进制日志复制的好处在于不会延迟,复制是实时的,第一个数据插入以后,立即通过wsrep协议复杂到其它节点上去了;
注意:Galera Cluster也没有分摊写操作,每个节点都可直接写,但读操作可以负载均衡;