基于 SparkGraphx 实现的 DBScan聚类
关于DBScan算法的详细介绍请参见维基百科
https://en.wikipedia.org/wiki/DBSCAN
Graphx 实现Dbscan 图解
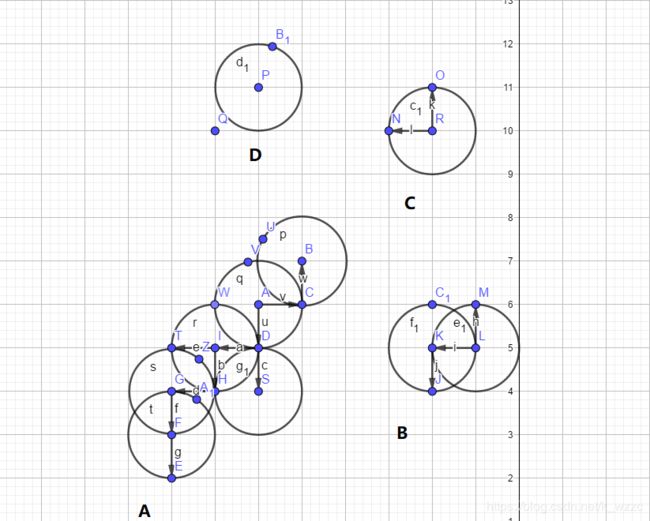
图解
1.上图中蓝色的点代表我们需要聚类的样本点,假设我们将DBScan的两个参数:距离 (Eps)设为1,最小集群点数(minPts)设为 4,则根据聚类规则,上图的A、B部分则会分别被聚为一类,C、D部分则会被视为离群点。
2.而Graphx的作用就是将两个距离满足条件的点连成边,然后再将这些边连成一个个的连通图,最后再计算各个图内的点数是否满足设定的最小集群点数。根据聚类规则我们就可以完成聚类,抽象出来就如上图所示。
3.代码实现过程如下
本文所使用的是经纬度数据,因此在使用距离计算的时候,用的是经纬度距离的计算方法(球面距离),在实现过程中也使用了Geohash算法(相关介绍有很多,这篇帖子就很好)进行了相关优化。
/**
* 参数校验
*/
if (args.length != 4) {
println(
"""
|参数:
|dbinput 输入路径
|eps 邻域半径
|minpts 最小密集点数
|dboutput 输出路径
""".stripMargin)
System.exit(3)
}
val Array(dbinput, eps, minpts, output) = args
val spark = SparkSession.builder()
.appName(s"${this.getClass.getSimpleName}")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.shuffle.consolidateFiles", "true")
.config("spark.io.compression.codec", "snappy")
.getOrCreate()
import spark.implicits._
// 加载数据
val dbdata = spark.read.option("inferSchema", true).csv(dbinput)
// 计算经纬度距离
def distanceBetweenPoints(lon1: Double, lon2: Double, lat1: Double, lat2: Double): Double = {
require(lon1 >= -180 && lon1 <= 180)
require(lon2 >= -180 && lon2 <= 180)
require(lat1 >= -90 && lat1 <= 90)
require(lat2 >= -90 && lat2 <= 90)
val R = 6371009d // average radius of the earth in metres
val dLat = toRadians(lat2 - lat1)
val dLng = toRadians(lon2 - lon1)
val latA = toRadians(lat1)
val latB = toRadians(lat2)
// The actual haversine formula. a and c are well known value names in the formula.
val a = sin(dLat / 2) * sin(dLat / 2) +
sin(dLng / 2) * sin(dLng / 2) * cos(latA) * cos(latB)
val c = 2 * atan2(sqrt(a), sqrt(1 - a))
// 默认返回千米
(R * c) / 1000D
}
// 经纬度距离 sparksql udf
val lonLatDistance = udf((lon1: Double, lon2: Double, lat1: Double, lat2: Double) => {
distanceBetweenPoints(lon1, lon2, lat1, lat2)
})
此部分是结合GeoHash算法做的一点优化,主要是根据dbscan的距离参数预先对数据进行分组,笔者水平有限,只想到了这个数据分区的方法。
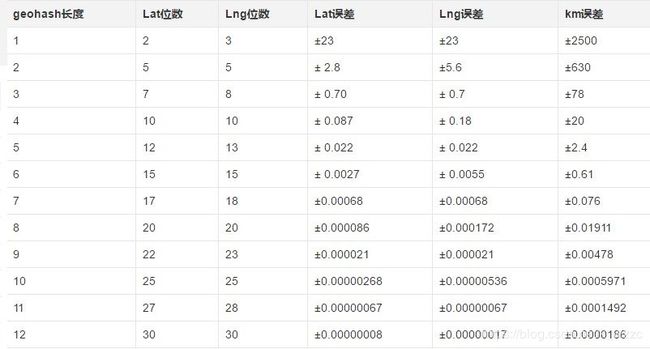
GeoHash Code 精度对照
// 根据geohash算法对经纬度数据做分区
val scope = udf((lon: Double, lat: Double) => {
// geohash
val geohash = GeoHash.encodeHash(lat, lon,
// 计算geohash的最优分区位数
MLUtils.geoLength(eps.toDouble))
val neighbours: Array[String] = GeoHash.neighbours(geohash).toArray().map(_.toString)
Seq(geohash) ++ neighbours
})
// 将原始的经纬度数据按照相同的分组进行 join聚合
val localbase = dbdata
.toDF("lon", "lat")
.where($"lon".isNotNull and $"lat".isNotNull)
.withColumn("id", hash($"lon", $"lat"))
val ll = localbase
.withColumn("scopes", scope($"lon", $"lat"))
.withColumn("scope", explode($"scopes"))
.drop("scopes").cache()
val ll2 = ll.toDF("lon2", "lat2", "id2", "scope")
val data = ll.join(ll2, "scope").where($"id" =!= $"id2")
.withColumn("distance", lonLatDistance($"lon", $"lon2", $"lat", $"lat2"))
//构建边Edge[Int]
val lv: RDD[(VertexId, VertexId)] = data
.filter($"distance" <= eps.toDouble) // 筛选出满足距离条件的点
.select($"id", $"id2").rdd
.map(row => {
val id = row.getAs[Int]("id").toLong
val id2 = row.getAs[Int]("id2").toLong
(id, id2)
})
val le = lv.map { ids => Edge(ids._1, ids._2, 0) } // 根据点构建边
// 构建图
val graph = Graph(lv, le)
val gcc = graph.connectedComponents().vertices
val joined = gcc.join(lv)
.map(tp => {
(tp._2._1, Seq(tp._2._2))
}).reduceByKey(_ ++ _) // 聚合每个联通图的点
.map(tp => {
(tp._2.distinct, tp._2.distinct.length)
}).filter(_._2 >= minpts.toInt) // 筛选出满足最小聚类点数的连通图
val clust = joined.toDF("clu", "ct")
.withColumn("cluid", hash($"clu"))
.withColumn("id", explode($"clu"))
val dbres: DataFrame = localbase.join(clust, Seq("id"), "left")
.na.fill(0).drop("clu", "ct") // 离群点的聚类id以0标识
// 保存聚类结果
dbres.repartition(1).write.option("header", true)
.mode("overwrite")
.csv(output)
在本案例中,eps设为30km,minPts设为 5,聚类结果的可视化如下 ,红圈的就是两个簇类,其余的都是离群点
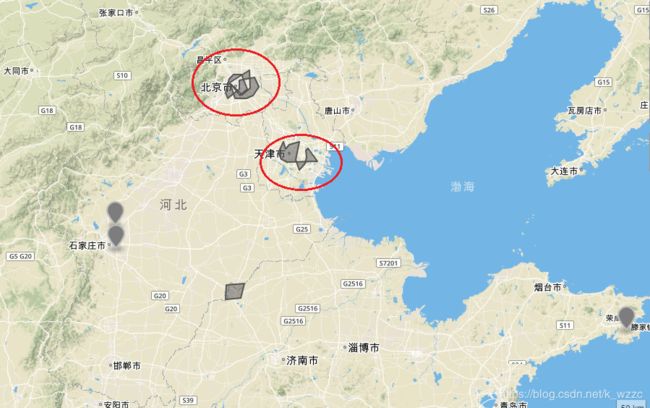
聚类结果可视化
本案例的数据链接 https://pan.baidu.com/s/1EaA7oGAmiJ2m4oXPLppsdg
用此方法实现的DBScan聚类在大数据集上运行效率较低,还有很多可以优化的地方,也有很多可以扩展的地方,如有不当之处,欢迎指正