可靠性
- 程序按照预期运行
- 有一定容错能力(用户使用方式错误)
- 在预期的负载和数据量下,系统性能足够好
- 预防未授权访问和滥用
错误 != 失败,我们只能保证容忍某些特定错误,提供容错性来尽量避免系统fail
可以特意触发某种错误来检测我们系统的容错和error handling的能力(Netflix Chaos Monkey)
尽管我们更倾向于提高容错性而不是完全避免错误,如果涉及到安全性相关的场景,需要做到完全防范(错误很可能无法挽救)
硬件错误
硬件冗余是最先想到的解决方案
- 硬盘Raid
- 后备电源
- 热切换CPU
- 数据中心冗余
down机后通过启动备份机器来保证可用性,对于现在的云服务,可以对不同单个机器进行有计划的downtime维护来确保系统可用性。
软件错误
硬件之间的错误一般没有关联性,一台机器损坏不会导致另一台机器损坏,大规模硬件同时损坏的概率很小(除了地震之类)。
但是系统性的错误就很难预测,可能会涉及不同的节点或者系统模块,更容易导致系统fail,比如:
- 某些输入可能引发软件bug导致系统崩溃,例如Linux 内核的leap second bug
- 失控进程耗尽共享资源- CPU时间片,内存,硬盘或者带宽
- 系统依赖的服务变的缓慢,无响应,或者返回不正确的响应
- failure升级,某个模块中的小错误引发其他模块错误,引起雪崩
这种错误可能长期休眠,在某个时刻突然爆发,只能通过一些方法减少这种错误:
- 仔细思考系统的交互和各种可能性
- 彻底测试
- 进程隔离
- 允许进程崩溃和重启
- 测量,监控和分析production的系统行为
人为错误
人都会犯错,很多时候系统错误是由于不正确的配置造成的,怎样在无法避免人为错误的同事尽量提高系统的可靠性?有下面几个方案:
- 设计系统的时候尽量减少犯错机会,比如精心设计的抽象,API和管理界面可。但是如果接口有太多限制,人们就会想办法绕过他们,所以需要在灵活性和限制性做一个平衡
- 将人们犯错最多的地方和实际可能导致失败进行解耦,提供完整功能的测试环境,并且使用真实数据让人们来进行测试
- 进行全方位的测试,包括单元测试,集成测试和手动测试。自动测试也应该广泛推广,特别是一些正常情况下涉及不到的极端情况
- 允许简单快速恢复来降低人为因素带来的failure,比如快速回滚配置更改,逐步部署新代码,并且提供工具来重新计算数据
- 设置详细和清晰的监控,例如性能指标和错误率,这被称为遥测,来追踪发生的事情,更好理解故障。监控可以发出早期预警,并且让我们去检查是否有任何违规行为。
- 实施良好的管理实践和培训(复杂,这里不讨论)
扩展性
系统现在的可靠不代表将来一定可靠,最常见的场景是用户或者业务增长带来的负载增长。扩展性不是一个简单的概念,说某个系统可扩展而某个不可以,它用来描述系统应对负载上升的能力。我们通常需要考虑“如果系统以某种特定方式增长,我们的应对方案是什么?”
描述负载
负载可以用负载参数来描述,怎样选取取决于系统的架构,举几个例子:
- web server的每秒请求数(QPS)
- 数据库中读写比
- 同时活跃的用户数量
- Cache的命中率
以2012 Twitter公布数据举例, Twitter用户的主要两个操作为:
- 发推: 用户可以向follower发布消息,平均4.6k/s,峰值12k/s
- 主页时间线: 用户可以浏览follow的人的消息,300k/s
仅仅处理12k/s的写入并不难, Twitter的难点在于每个人有多个follower并且可以follow多个人,这个挑战的解决方案有两种:
- 发推只需要简单把新tweet插入一个全局tweet集合中,当用户请求首页时间线时,查找所有他们follow的人,找到对应的tweet,并且按时间顺序合并,在如下图一样的关系型数据库中,可以编写如下query:
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
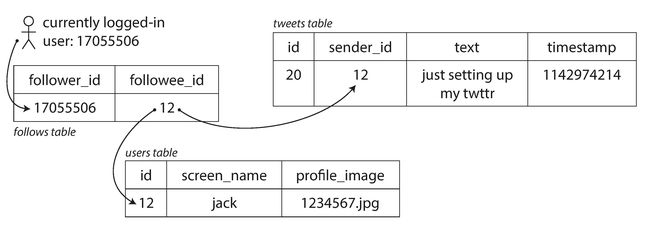
-
为每个用户的首页时间线维护一个缓存,就像一个针对每个收件人的推文邮箱。当用户发布tweet的时候,去查看follow这个用户的所有用户,在他们的cache里面插入这条消息。这个时候对首页时间线的请求就非常"便宜",因为这个结果是提前计算好的。
 image
image
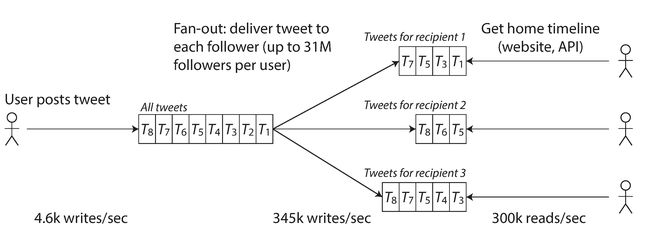
Twitter最开始采用了方法1, 但是query的数量增加很痛苦,后来切换到了方法2,因为发布tweet的平均要比读取首页时间线的低两个数量级。
方法2的缺点是发布一个tweet需要很多额外的工作。平均而言,一条tweet会发送给75个关注者,因此每秒4.6k的tweet会变成345k次对cache的写入。但是这个平均值忽略了用户关注者数量差异巨大这个事实,某些用户拥有超过3000万关注者,这样就意味着一条tweet可能导致超过3000万次对cache的写入。
在Twitter的例子中,每个用户关注者的分布是一个关于可扩展性的关键负载参数。
最终Twitter采用两种方式的混合,大部分人还是采用cache的方式,对于名人则会单独进行提取并且在刷新首页时间线的时候进行合并。
描述性能
当负载增加的时候,我们可以从以下两个方面查看性能:
- 负载参数增加但是系统资源(CPU,内存,带宽等等)不变的情况下,系统性能如何?
- 负载参数增加的情况下,增加多少资源才能使系统性能不变
这两个问题都需要对性能做一个量化,怎么去描述系统性能?
在一个批处理系统(比如Hadoop)中,我们通常关注吞吐量(throughput) - 每秒处理数据的数量, 或者说运行一个特定大小的数据集消耗的时间。
在一个web系统中,我们通常更关心系统的响应时间。如果系统处理多次请求,响应时间或许相差很大,我们需要专注响应的分布而不是单次时间。
响应时间的差异可能有多方面的原因(即使理论上时间应该差不多):
- 后台处理中的上下文切换
- 丢包和TCP重传
- GC 停顿
- 页或者缓存错误需要从新从硬盘读数据
- 机器架子的机械振动
我们常会看到平均响应时间(sum(time)/n), 但是这种方式并不是非常好,你无法知道多少用户的延迟大概是这个数字。
一般来说采取百分比会更好一点,拿到所有的数据按照时间排序,取得其中的中位数,比如是200ms,这意味着半数用户延迟超过了200ms,也意味着我们预期的响应时间是200ms。
如果想要找到异常值有多差,我们可以取更高的百分比,95%,99%,99.9%是常用的指标,比如95%的响应时间是1.5s, 意味着100个里面有5个用户响应时间超过1.5s。
高百分比的(尾部延迟)响应时间十分重要,它直接影响用户体验,请求速度慢有可能是因为请求数据多,也就是说有可能是最有价值的用户, Amazon可能会看到99.9%。
另一方面来说,过高百分比的优化可能会非常昂贵,需要进行收益和开销的权衡。
百分比经常被用于服务等级目标(SLO)和服务等级协议(SLA),来定义服务预期的性能和可用性。比如SLA可以定义如下:
- 中位数响应时间小于200ms
- 99%响应时间小于1s
- 服务需要在99.9%时间内可用
- 如果满足不了以上条件可以退钱...
(SLA = SLO + 后果, 可以简单这么理解)
排队延迟经常是响应时间非常慢的原因,服务器只能并行处理少量请求(比如收到CPU核心数量限制),因此只需要少量几个缓慢的请求就可以阻塞后面的请求,这被称为队头阻塞(head-of-line block),尽管请求被真正处理的时间很短,客户端的响应时间也会很长,所以我们需要在客户端进行测量响应时间。
应对负载
对于当前负载表现良好的系统不见得在10倍负载时还会表现良好,如果设计一个可能快速增长的服务,需要考虑不同维度的负载的增长。
人们常常讨论垂直扩展和水平扩展,在多台机器上分布负载也被称为无共享架构。在做决定的时候也要综合考虑,使用一台或者几台强大的机器仍然可能要比使用很多性能很差的机器更为简单和便宜。
一些系统具有弹性,可以根据负载自动添加计算资源,而有一些系统则需要手动水平扩展。在负载难以预测的情况下,弹性系统更好,但是人工扩展更为简单并且更不容易出现意外。
在分布式系统中无状态服务非常简单直接,而有状态服务会非常繁琐。
分布式系统中需要应对的问题要依据场景来定,不同的系统需要应对的情况差别很大,比如:
- 大量数据读
- 大量数据写
- 大量数据存储
- 数据复杂程度
- 响应时间需求
- 访问模式
- 以上等问题的综合
比如一个系统设计为可以每秒处理100,000个请求,每个请求都有1kb, 那么他和另外一个每分钟处理3个请求,每个请求有2Gb完全不同, 尽管他们的数据输入大小一致。
系统的水平扩展设计基于负载参数的假设,如果假设是错误的,最好情况是做无用功,最差情况是起到反作用。因此在开发初期,快速实现产品功能比对未来负载扩展的设计更为重要。
可维护性
大多数情况下,软件的维护成本要高于开发成本:
- 修复bug
- 保持系统的运行
- 调查故障
- 适配到新的平台
- 技术偿债
- 现有功能修改
- 新功能开发
大部分人不喜欢老系统的维护工作,我们在设计系统的时候应该尽量减少维护时的痛苦,防止创造出所谓的"老系统",有以下3个设计准则:
- 可操控 - 使运维容易维护系统的正常运转
- 简单 - 让新人容易理解这个系统,去除不必要的复杂度
- 可进化 - 能够轻松对系统进行更改,根据需求变化进行调整。也被称为可扩展性(extensibility), 可修改性(modifiability)或者可塑性(plasticity)
可操控: 让运维更轻松
一些方面的运维工作可以被自动化,但是它还是需要很多人为干涉,好的运维有以下职责:
- 监控系统健康,在变差的情况下能够快速恢复服务
- 记录问题原因,比如系统故障或者性能变差
- 保证软件和平台与时俱进,包括安全模块
- 理解并监控不同系统间的相互影响,在有问题的更改造成影响之前发现
- 预测未来的问题并且进行预防(比如 容量估算)
- 对于配置和部署有着丰富经验和成熟的工具
- 能够执行复杂的运维任务,比如将应用进行跨平台移动
- 配置更改后确保系统的安全性
- 定义流程使得操作可预测并且保持production环境稳定
- 在人员流失的情况下保证公司对系统的了解
良好的可操作性可以让日常工作变的简单,让团队可以集中精力处理高价值的任务, 数据系统可以做很多事情:
- 提供可视化的系统运行行为监控
- 提供标准化工具进行自动化集成
- 避免对单个机器的依赖(允许机器单独down机维护并且不影响业务)
- 提供完善的文档和运维模式(如果做X, 会产生Y结果)
- 提供良好的默认行为,但是允许管理员在需要时覆盖这些行为
- 可能的话提供自我恢复功能,但是允许管理员在需要的时候人为控制系统状态
- 尽量保证行为可预测,减少"惊喜"
简单化: 管理复杂度
小型项目可以有很简单并且清晰的代码,项目变大的时候就会变得十分复杂,很难理解,增加了维护成本。复杂度可能来自多个方面:
- 状态空间爆炸
- 模块间紧耦合
- 复杂的依赖挂你
- 不一致的命名和属于
- 某些魔法操作
减少复杂度最好的工具之一是抽象,一个好的抽象可以用一个简单清晰容易理解的外观(facade)隐藏大量背后的实现,也可以广泛用于不同的应用中。这不仅比重新实现相似的功能多次更为高效,而且也会使代码质量变高,在抽象组件的改进可以使所有使用这个抽象的应用受益。
比如高级语言隐藏了机器语言,CPU寄存器,系统调用。SQL隐藏了复杂的磁盘和内存中的数据结构,客户的并发请求以及崩溃后的恢复。
找到好的抽象是很难的,在分布式系统中我们也会把一些算法包装到一些抽象中使得系统复杂度可控。
可进化: 改变更简单
系统需求一直处于不断变化中,敏捷开发提供了一个适应变化的框架,还有其涉及的一些工具和模式比如TDD和重构。
敏捷的讨论大部分集中在小规模系统中,本书会探讨怎样在大的系统中提高敏捷度,可能包括不同的应用或者应用有着不同的特性,比如怎样去重构Twitter组装首页时间线的架构。
可进化的系统通常和简单性和抽象性密切相关,简单和容易理解的系统修改起来更为轻松,我们用可进化性来代表系统的敏捷级别。