本文由两篇文献详解组成,所以我分成上下两部分来讲。
上部分:来自:http://blog.sina.com.cn/s/blog_9db078090102whzw.html
多标签图像分类(Multi-label Image Classification)任务中图片的标签不止一个,因此评价不能用普通单标签图像分类的标准,即mean accuracy,该任务采用的是和信息检索中类似的方法—mAP(mean Average Precision)。
mAP虽然字面意思和mean accuracy看起来差不多,但是计算方法要繁琐得多,以下是mAP的计算方法:
首先用训练好的模型得到所有测试样本的confidence score,每一类(如car)的confidence score保存到一个文件中(如comp1_cls_test_car.txt)。
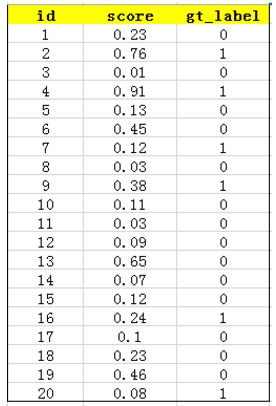
假设共有20个测试样本,每个的id,confidence score和ground truth label如下:
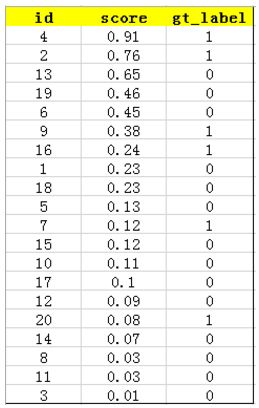
接下来对confidence score排序,得到:
然后计算precision和recall,这两个标准的定义如下:
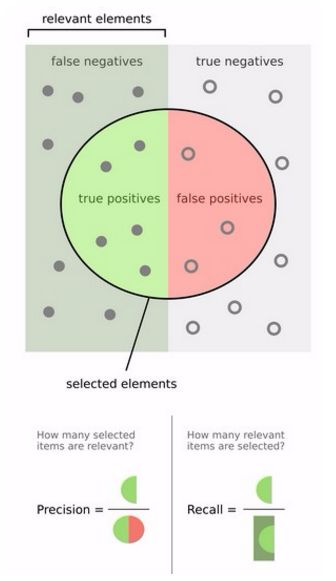
上图比较直观,圆圈内(true positives + false positives)是我们选出的元素,它对应于分类任务中我们取出的结果,比如对测试样本在训练好的car模型上分类,我们想得到top-5的结果,即:
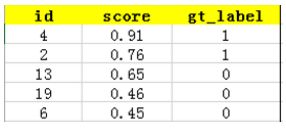
在这个例子中,true positives就是指第4和第2张图片,false positives就是指第13,19,6张图片。方框内圆圈外的元素(false negatives和true negatives)是相对于方框内的元素而言,在这个例子中,是指confidence score排在top-5之外的元素,即:

其中,false negatives是指第9,16,7,20张图片(因为其confidence score都已经小于0.5了),true negatives是指第1,18,5,15,10,17,12,14,8,11,3张图片。
那么,这个例子中Precision=2/5=40%,意思是对于car这一类别,我们选定了5(第4、2、13、19、6张)个样本,其中正确的有2个,即准确率为40%;Recall=2/6=30%,意思是在所有测试样本(第4、2、9、16、7、20张)中,共有6个car,但是因为我们只召回了2个,所以召回率为30%。
实际多类别分类任务中,我们通常不满足只通过top-5来衡量一个模型的好坏,而是需要知道从top-1到top-N(N是所有测试样本个数,本文中为20)对应的precision和recall。显然随着我们选定的样本越来也多,recall一定会越来越高,而precision整体上会呈下降趋势。
把recall当成横坐标,precision当成纵坐标,即可得到常用的precision-recall曲线。这个例子的precision-recall曲线如下:
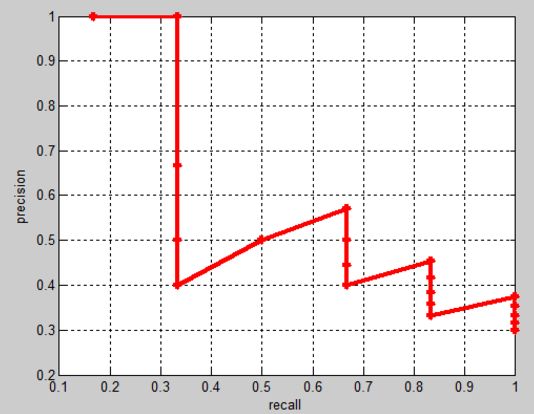
接下来说说AP的计算,此处参考的是PASCAL VOC CHALLENGE的计算方法。首先设定一组阈值,[0, 0.1, 0.2, …, 1]。然后对于recall大于每一个阈值(比如recall>0.3),我们都会得到一个对应的最大precision。这样,我们就计算出了11个precision。AP即为这11个precision的平均值。这种方法英文叫做11-point interpolated average precision。
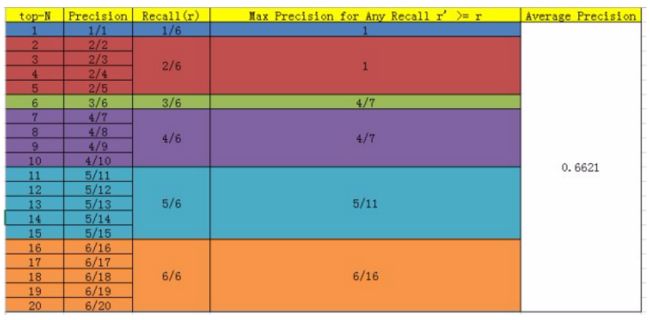
当然PASCAL VOC CHALLENGE自2010年后就换了另一种计算方法。新的计算方法假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, ..., M/M),对于每个recall值r,我们可以计算出对应(r' > r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。计算方法如下(绿色行的Max Precision值有误,应该是3/6):
(下图以confidence score排序为例)
相应的Precision-Recall曲线(这条曲线是单调递减的)如下:
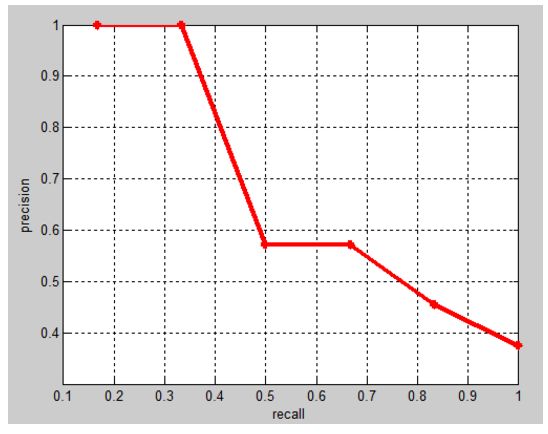
AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。
---------------------------------------------------------------------分割线--------------------------------------------------------------------------------
下部分:原文链接:http://www.xuebuyuan.com/1208150.html
在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总。
Precision准确率、Recall召回率、F1
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(**P**recision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
图示表示如下:
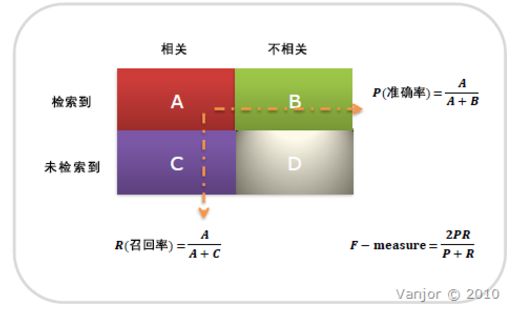
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。
一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
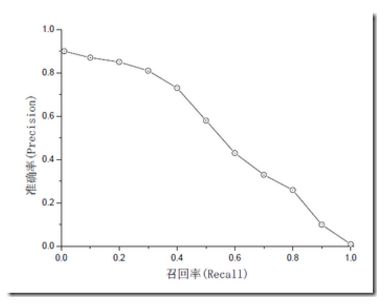
针对Precision和Recall有以下趋势(也正是因为这种趋势,所以要用到mAP来做评价):
假如有1k个样本,当这1k个样本全取完后,Recall = 1,但是Precision会很低。
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
1. F1 = 2 * P * R / (P + R)
公式基本上就是这样,但是如何算图1中的A、B、C、D呢?这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。
AP和mAP(mean Average Precision)
mAP是为解决Precision,Recall,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线
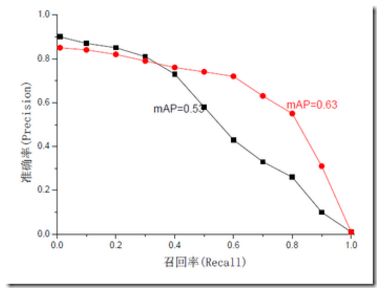
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率)
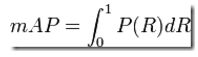
mAP(Mean Average Precision):单个主题的平均精度均值是每篇相关文档检索出后的精度的平均值。
主集合的平均精度均值(mAP)是每个主题的平均准确率的平均值。
mAP 是反映系统在全部相关文档上性能的单值指标。
系统检索出来的相关文档越靠前(rank 越高),mAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均精度均值为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均精度均值为(1/1+2/3+3/5+0+0)/5=0.45。则mAP= (0.83+0.45)/2=0.64。
ROC和AUC
ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。

回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。
ROC关注两个指标
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0,
0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。
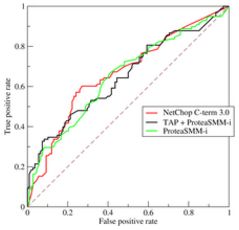
用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
AUC计算工具:
http://mark.goadrich.com/programs/AUC/
P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。
参考链接:
http://wenku.baidu.com/view/ef91f011cc7931b765ce15ec.html