协同过滤——曼哈顿距离、欧式距离、皮尔逊相关系数
假设你要在亚马逊上买书,系统要给你推荐一些书,利用协同过滤的话,原理是找出与你爱好相近的用户的购书清单,把他买了而你还没买的书推荐给你。
1. 如何寻找相似用户
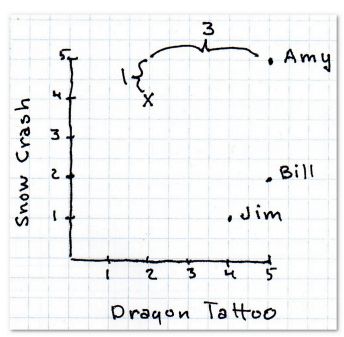
假设用户可以对书采取5星评级方式表达自己的喜好,0 表示很差,5 表示很好。如下图:
要找到与你喜好相近的用户,可以通过计算你与每个用户之间的打分的距离判断。距离越近,意味着喜好越相近。

2. 曼哈顿距离
图示计算过程长这样
Python实现:
def manhattan(rating1, rating2):
distance = 0
for key in rating1:
if key in rating2:
distance += abs(rating1[key] - rating2[key])
return distance
## rating1, rating2 结构如下:
rating1: {"Blues Traveler": 3.5, "Broken Bells": 2.0,
"Norah Jones": 4.5, "Phoenix": 5.0,
"The Strokes": 2.5, "Vampire Weekend": 2.0}
rating2 : {"Blues Traveler": 2.0, "Broken Bells": 3.5,
"Slightly Stoopid": 3.5, "Vampire Weekend": 3.0}
## users 结构,可能会多次用到
users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0,
"Norah Jones": 4.5, "Phoenix": 5.0,
"Slightly Stoopid": 1.5,
"The Strokes": 2.5, "Vampire Weekend": 2.0},
"Bill": {"Blues Traveler": 2.0, "Broken Bells": 3.5,
"Deadmau5": 4.0, "Phoenix": 2.0,
"Slightly Stoopid": 3.5, "Vampire Weekend": 3.0},
"Chan": {"Blues Traveler": 5.0, "Broken Bells": 1.0,
"Deadmau5": 1.0, "Norah Jones": 3.0,
"Phoenix": 5, "Slightly Stoopid": 1.0},
"Dan": {"Blues Traveler": 3.0, "Broken Bells": 4.0,
"Deadmau5": 4.5, "Phoenix": 3.0,
"Slightly Stoopid": 4.5, "The Strokes": 4.0,
"Vampire Weekend": 2.0},
"Hailey": {"Broken Bells": 4.0, "Deadmau5": 1.0,
"Norah Jones": 4.0, "The Strokes": 4.0,
"Vampire Weekend": 1.0},
"Jordyn": {"Broken Bells": 4.5, "Deadmau5": 4.0, "Norah Jones": 5.0,
"Phoenix": 5.0, "Slightly Stoopid": 4.5,
"The Strokes": 4.0, "Vampire Weekend": 4.0},

利用曼哈顿函数寻找最近邻

利用最近邻喜欢的而你没有购买的书进行推荐
3. 毕达哥拉斯定理(勾股定理)

二维下的两点之间的距离
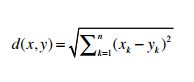
n 维下的综合公式
3.1 计算明式距离

3.2 找出最近邻
3.3 根据最近邻的喜好进行推荐
4. 皮尔逊相关系数
因为用户的评分标准不一致,在A眼里,5分代表好,3分代表差,可能B的标准是3分代表好,0分代表差。皮尔逊相关系数就是平衡“分数贬值”这一问题。
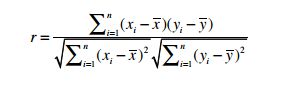
皮尔逊相关系数计算公式

化简后的即平时用的皮尔逊相关系数计算公式
假如有一组数据:
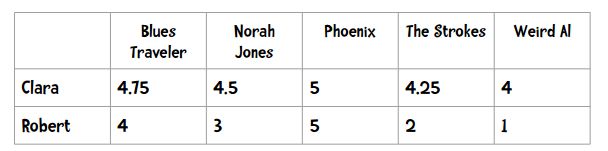
X 代表 Clara 这一列的五个数字, Y 代表 Robert 这一列的数字。
代入公式计算即得到皮尔逊相关系数。

程序实现
得出的皮尔逊相关系数值在0-1之间,越接近1,表示相似度越高。
5. 余弦相似度
亚马逊上有成千上万本书,找到与你喜好相同的用户,你们共同的评分项可能很少,有大量的项是空白,数据稀疏。如果把所有数据拿来计算,因为大量0值会影响最后的计算结果,可能会导致本来有很多共同评分项的用户,由于0值过多,分担计算结果,反而不是你的最近邻。余弦相似度会忽略0-0匹配:

||x|| 表示向量x 的长度,点乘表示内积。
余弦相似度取值范围1到-1,其中1表示完全相似,-1 表示完全不相似。
6. 总结
无论利用哪种公式,计算出的首先都是最近邻,然后根据最近邻的书单进行推荐。
书籍原版