一.在使用中出现的问题
1 package test 2 3 import org.apache.log4j.{Level, Logger} 4 import org.apache.spark.sql.SparkSession 5 6 /** 7 * Created by Administrator on 2019/12/17. 8 */ 9 object TestZip { 10 /** 11 * 设置日志级别 12 */ 13 Logger.getLogger("org").setLevel(Level.WARN) 14 def main(args: Array[String]) { 15 val spark = SparkSession.builder().master("local[2]").appName(s"${this.getClass.getSimpleName}").getOrCreate() 16 val sc = spark.sparkContext 17 val array_left = 1 until 4 //生成1到count的数组 18 val array_right = Array("工单", "电力", "展示") 19 20 val result = array_left.zip(array_right) 21 val rdd = sc.parallelize(result).sortBy(_._1) 22 val rdd2 = sc.parallelize(result).sortByKey(true) 23 24 rdd.foreach(println) 25 println("----------------") 26 rdd2.foreach(println) 27 } 28 }
二.执行结果

从结果中可以看出,sortBy和sortByKey都没有实现排序的功能【虽然它们顺序已经改变】。这是怎么回事?

具体原因下面我们从源码中进行分析!
三.源码分析
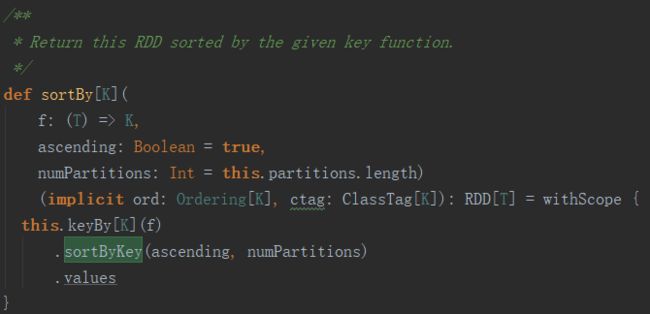
在Spark的源码中,从RDD.scala代码中可以看出,sortBy底层调用的是sortByKey算子,在无升序降序的参数下【ascending】,默认为升序【true】,因此,我们只需要前往sortByKey中分析为什么没有实现排序功能即可。
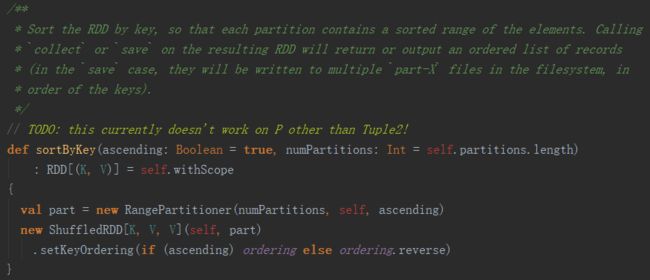
1.在OrderedRDDFunctions.scala中,可以看见sortByKey实现的具体细节,从注释中可以看出,排序基于key,在每个分区内部实现一个排序序列,注意,是每个分区内,下面我们去重置分区为1来检验一下是否有效!
2.另外,注释也提到调用collect或者save也可以获取一个有序的序列,下面也一块去验证!
四.设置分区为1
![]()
执行结果:

由此可见,当设置分区数为1时【即合并所有分区为一个分区,显然之前的分区数不为1,查看存在多少分区数可以参考我的博客:https://www.cnblogs.com/yszd/p/10156231.html】,可以实现升序排序,当然降序也是可以的!


五.以collect为例进行验证


备注:由此可见,调用collect也可以实现排序,但调用collect之后会返回一个Array,不再是RDD!
六.原因分析
不管是repartition还是collect,其本质都是把各个executor中的数据汇总到master主节点中,是调用action算子,会存在repartition和shuffle操作。源码就很好的验证了这一点:
![]()
在sortByKey中,会调用分区算子进行重新分区,与显式调用repartition有异曲同工之妙!

而其中的ShuffledRDD会在shuffle执行过程中现在每个分区内进行排序,之后再进行整体的排序,以便提升排序性能,类似与归并排序算法!